quran-burmese-word-alignment
收藏Hugging Face2026-02-01 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/freococo/quran-burmese-word-alignment
下载链接
链接失效反馈官方服务:
资源简介:
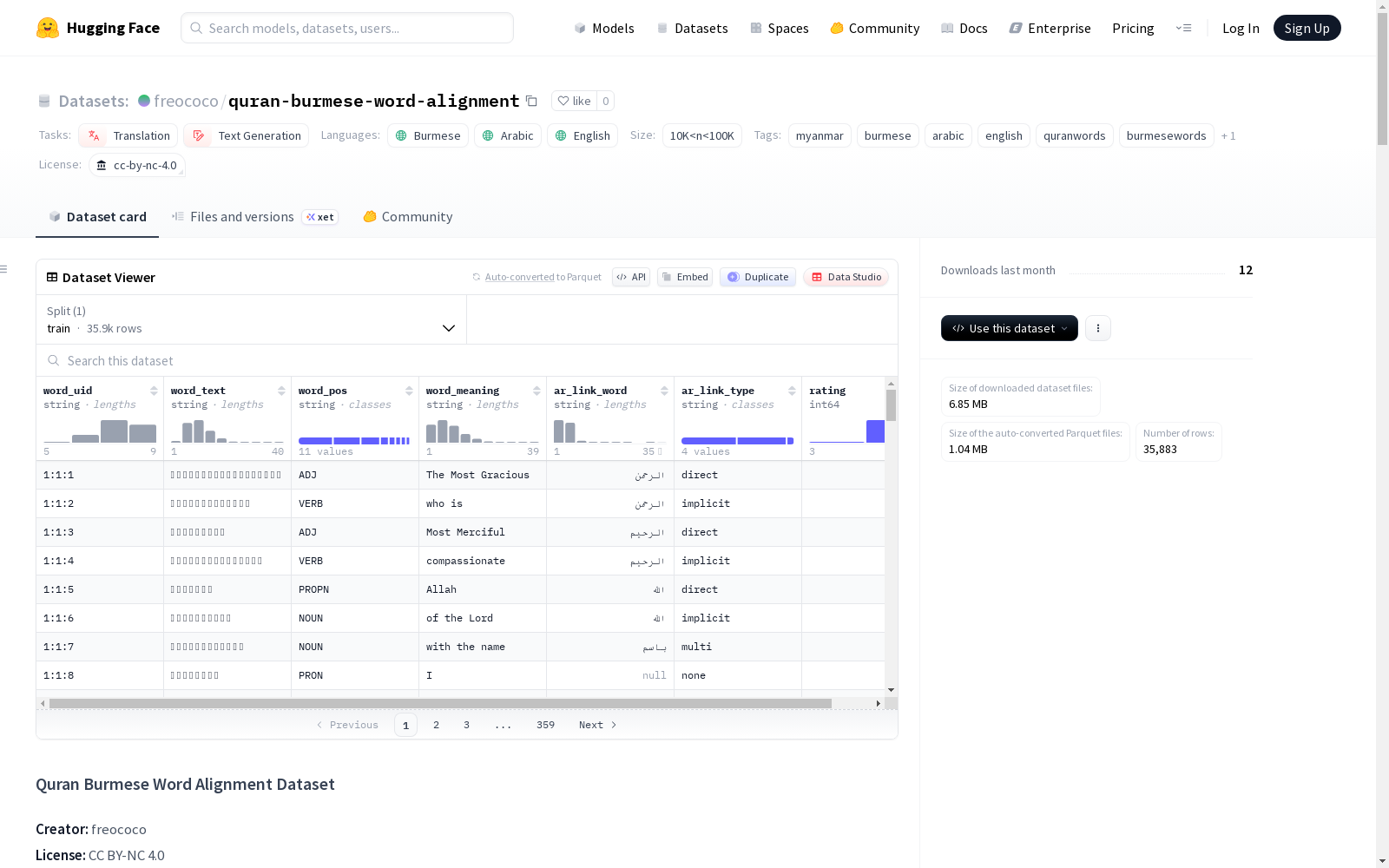
《古兰经缅甸语单词对齐数据集》提供了缅甸语翻译的《古兰经》与阿拉伯语原文之间的逐词对齐。每个缅甸语单词表示为一个JSON对象,并可选地链接到一个或多个对应的阿拉伯语单词,明确标注链接类型(直接、隐含或多词)。数据集采用JSONL格式,每行一个单词,包含唯一标识符、单词文本、词性标签、英语释义、阿拉伯语链接单词、链接类型和置信度评分等字段。当前版本v1涵盖第1-2章,共293节经文,10,874个单词。该数据集适用于《古兰经》语言学研究、低资源语言NLP(缅甸语)、单词对齐和跨语言建模,以及教育和数字《古兰经》项目。数据集遵循严格的注释规则,确保一致性和可审计性,并采用CC BY-NC 4.0许可,允许非商业用途的共享和改编。
创建时间:
2026-02-01
原始信息汇总
Quran Burmese Word Alignment 数据集概述
数据集基本信息
- 数据集名称: Quran Burmese Word Alignment
- 创建者: freococo
- 许可证: CC BY-NC 4.0
- 语言: 缅甸语(缅甸)、阿拉伯语、英语
- 格式: JSONL(每行一个词)
- 当前版本: v1(涵盖第1-2章)
- 大小类别: 10K < n < 100K
- 任务类别: 翻译、文本生成
- 标签: 缅甸、缅甸语、阿拉伯语、英语、quranwords、burmesewords、englishwords
数据集内容与结构
- 文件:
q_v1.jsonl - 覆盖范围: 古兰经第1章和第2章
- 总节数: 293
- 总词数: 10,874
- 数据格式: 每行一个JSON对象,代表一个缅甸语单词
数据模式与字段定义
每个JSON对象包含以下字段:
word_uid: 唯一标识符,格式为Surah:Verse:WordIndexword_text: 节文中出现的精确缅甸语单词word_pos: 词性标签(NOUN、VERB、ADJ、PRON、PARTICLE、PROPN、UNKNOWN)word_meaning: 缅甸语单词的简明英语含义ar_link_word: 来自原始古兰经的阿拉伯语单词(去除变音符号),或为nullar_link_type: 阿拉伯语链接类型:direct、implicit或multirating: 置信度/质量评分,范围从1(低)到5(高)
阿拉伯语对齐原则
对齐基于语义和含义,而非机械强制。
direct: 与特定阿拉伯语单词存在清晰的一对一对应关系implicit: 含义从周围的阿拉伯语上下文中推断得出multi: 一个缅甸语单词对应多个阿拉伯语单词null: 不存在有意义的阿拉伯语链接
标注规则
- 包含每一个缅甸语单词(无跳过)
- 一个单词对应一行JSONL
- 单词索引在每节开始时重置
- 阿拉伯语变音符号被移除以进行规范化
- 始终提供
word_pos和word_meaning
版本规划
v1: 第1-2章(已发布)v2: 附加章节(计划中)v3: 完整古兰经(计划中) 所有未来版本将保持与早期版本的向后兼容性。
数据来源与归属
- 原始缅甸语古兰经译本来源: King Fahd Complex for the Printing of the Holy Quran(沙特阿拉伯)印制
- 翻译者: Burmese Muslim Scholars Translation Committee
- 翻译方法: 基于含义,遵循古典逊尼派学术传统 本数据集不修改原始翻译文本,仅为研究和教育目的提供词级注释和对齐。
许可信息
本数据集根据 知识共享署名-非商业性使用 4.0(CC BY-NC 4.0) 许可证发布。 允许共享、改编和基于数据集进行构建。 要求署名,且不允许商业用途。
创建目的
本数据集旨在支持:
- 缅甸伊斯兰教育
- 开放的语言学和古兰经研究
- 合乎伦理的非商业人工智能开发
搜集汇总
数据集介绍
构建方式
在跨语言宗教文本研究领域,构建高质量的对齐数据集对于理解语义传递至关重要。本数据集以沙特阿拉伯国王法赫德古兰经印刷厂出版的缅甸语译本为源文本,由专业学者进行逐词标注与对齐。标注过程严格遵循预先定义的规则,确保每个缅甸语词汇均对应独立的JSON对象,并依据语义关联性链接至阿拉伯语原文词汇。阿拉伯语对齐采用去除了变音符号的规范化形式,且标注类型明确区分直接对应、隐含对应及多词对应等多种情形,所有链接均基于语言学判断,杜绝人为编造或强制对齐,从而保障了数据的学术严谨性与可靠性。
特点
作为面向低资源语言与经典文本研究的专项数据集,其核心特点体现在精细的词汇级对齐与丰富的元信息标注上。数据集覆盖了古兰经前两章,包含超过一万个缅甸语词汇,每个词汇均附带词性标注、英文释义以及对齐置信度评分。阿拉伯语链接类型的设计反映了翻译中的语义复杂性,允许存在一对多或隐含关联,这为跨语言语义分析和翻译模型训练提供了 nuanced 的监督信号。数据集采用JSONL格式存储,结构清晰且易于解析,严格的版本管理计划确保了未来扩展的向后兼容性,为长期学术研究提供了稳定基础。
使用方法
在自然语言处理与计算语言学应用中,本数据集适用于多种研究场景。研究者可将其用于缅甸语-阿拉伯语词汇对齐模型的训练与评估,尤其对低资源语言机器翻译和跨语言词嵌入学习具有价值。教育技术领域可基于该数据集开发交互式古兰经学习工具,通过可视化词汇对应关系辅助语言与宗教教学。使用时,用户需遵循CC BY-NC 4.0许可协议,仅限非商业用途。数据加载可通过逐行读取JSONL文件实现,利用其中的唯一标识符、词性、对齐类型及评分等字段,进行统计分析、模型输入构建或可视化呈现。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的机器翻译与跨语言对齐研究长期面临数据稀缺的困境。Quran Burmese Word Alignment数据集由freococo于近期创建,旨在为缅甸语与阿拉伯语之间的词级对齐提供精准标注资源。该数据集以沙特阿拉伯国王法赫德古兰经印制局出版的缅甸语译本为源文本,由缅甸穆斯林学者翻译委员会基于古典逊尼派学术传统完成翻译。其核心研究问题聚焦于解决缅甸语这一低资源语言在古兰经翻译中的词义对齐难题,通过语义驱动的标注方法,为古兰经语言学、低资源语言自然语言处理以及跨语言建模等领域提供了高质量的基础数据,对推动宗教文本的数字化研究与教育应用具有重要价值。
当前挑战
该数据集致力于解决古兰经翻译中缅甸语与阿拉伯语之间的词级对齐挑战,这涉及处理两种语言在形态、句法和语义层面的深刻差异,例如阿拉伯语的高度屈折特性与缅甸语的孤立语特征之间的映射复杂性。在构建过程中,标注工作面临多重困难:首先,必须确保对齐基于语义而非机械匹配,这要求标注者具备深厚的语言学与宗教学知识;其次,缅甸语作为低资源语言,缺乏成熟的自然语言处理工具支持,增加了词性标注与分词的一致性维护难度;此外,数据集采用严格的逐词收录与JSONL格式规范,要求标注过程高度精确,以避免信息遗漏或格式偏差,这些因素共同构成了数据集构建的核心挑战。
常用场景
经典使用场景
在低资源语言处理领域,该数据集为缅甸语与阿拉伯语之间的词级对齐提供了珍贵资源。研究者常利用其精细标注的语义链接,开发跨语言词嵌入模型或统计对齐算法,以探索两种语言在形态和句法层面的对应关系。尤其在宗教文本的翻译研究中,数据集支持对古兰经经文进行结构化的语言学分析,为机器翻译系统在低资源语言对上的性能提升奠定基础。
解决学术问题
该数据集有效应对了低资源语言自然语言处理中的核心挑战,如缺乏大规模平行语料库的问题。通过提供专家生成的词级对齐,它促进了跨语言信息检索、语义角色标注等任务的模型训练。在计算语言学领域,数据集助力于研究语言类型学差异,特别是阿拉伯语与缅甸语之间的语义映射机制,为多语言模型在稀缺语言场景下的泛化能力提供了实证基础。
衍生相关工作
围绕该数据集,已衍生出多项经典研究工作。例如,基于其对齐结构开发的跨语言词向量模型,被用于提升缅甸语-阿拉伯语机器翻译的准确性。同时,在低资源语言处理领域,研究者利用该数据集评估了多种无监督对齐算法的性能。此外,数据集还启发了对宗教文本计算语言学分析方法的创新,如结合语义链接的经文风格迁移研究,推动了多语言NLP技术在特定领域的深化应用。
以上内容由遇见数据集搜集并总结生成


