NuTonic/sat-vl-sft-training-ready-v1
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/NuTonic/sat-vl-sft-training-ready-v1
下载链接
链接失效反馈官方服务:
资源简介:
---
pretty_name: sat-bbox-metadata-sft
language:
- en
license: other
task_categories:
- text-generation
- image-text-to-text
tags:
- satellite
- remote-sensing
- vision-language
- instruction-tuning
- grounding
- bounding-boxes
- dynamic-world
configs:
- config_name: default
data_files:
- split: train
path: data/train.jsonl
- split: validation
path: data/validation.jsonl
- split: test
path: data/test.jsonl
size_categories:
- 100K<n<1M
---
## Dataset Summary
`NuTonic/sat-bbox-metadata-sft-v1` is a **metadata-first, procedural VLM SFT dataset** built from an existing “sat-bbox” style dataset tree (Sentinel‑2 chips + per-tile JSON metadata sidecars, optionally paired Mapbox stills).
The goal is to create **high-signal, production-shaped supervision** for multimodal chat models:
- **Captioning** for satellite chips
- **Grounding** (bounding boxes in normalized coordinates) for land-cover regions
- **Class-focused captions** and **absence checks** for specific land-cover classes
- **Cross-view** reasoning using optional Mapbox overhead context
- **Production-like analytical summaries** that include:
- Sentinel‑2 imagery
- An additional procedural “analysis image” (a TiM-like predicted-class raster)
- A compact **TiM-shaped analytics JSON** block
- A profile-specific assistant summary (land use change, wildfire, flood pulse, etc.)
This dataset is generated **without calling Mapbox APIs**; it only uses paths that already exist in the input dataset root.
## What “procedural” means here
The dataset uses *deterministic, rule-based / synthetic* construction to:
- transform metadata sidecars into multiple supervised tasks,
- produce a TiM-shaped analytics JSON structure,
- render an additional analysis PNG per row (for the analytical tasks).
These rows are intended for **instruction tuning** and **format/behavior alignment**, not as ground-truth scientific measurements.
## Land-cover classes
Land-cover semantics follow **Google Dynamic World v1** class ids (0–8):
| id | label |
|---:|---|
| 0 | water |
| 1 | trees |
| 2 | grass |
| 3 | flooded_vegetation |
| 4 | crops |
| 5 | shrub_and_scrub |
| 6 | built |
| 7 | bare_ground |
| 8 | snow_and_ice |
## Data format (what’s in `data/*.jsonl`)
Rows are JSON objects with a `messages` list in a chat format compatible with common VLM SFT pipelines.
Each row is one conversation like:
- `system` (optional; used for production-analysis rows)
- `user`: one or more `{"type":"image","image":"<relative path>"}` parts, followed by one `{"type":"text","text":"..."}` part
- `assistant`: `{"type":"text","text":"..."}`
Some rows also include a `metadata` object on the top-level row (not to be confused with the dataset `metadata/` folder). For example, production-analysis rows include:
- `metadata.sample_id`
- `metadata.task`
- `metadata.analysis_profile`
- `metadata.tile_stem`
- `metadata.split`
- `metadata.image_paths`
- `metadata.analysis_image_path`
### Tasks emitted
Depending on build configuration, the builder can emit the following task types:
- `production_analysis`:
- 2–3 images (Sentinel‑2 + optional Mapbox + generated analysis image)
- user prompt contains a compact TiM-shaped JSON block
- assistant output is an application-specific analytical summary
- `caption`:
- 1 Sentinel‑2 image
- assistant caption derived from sidecar
- `grounding_all`:
- 1 Sentinel‑2 image
- assistant output is JSON list of boxes: `[{"label": str, "bbox":[x1,y1,x2,y2]}, ...]` with coords normalized to 0–1
- `grounding_per_class`:
- same as grounding, but per dominant class label
- `class_focus`:
- 1 Sentinel‑2 image
- assistant describes only a specific class’ approximate share/layout
- `absence`:
- 1 Sentinel‑2 image
- assistant answers conservatively about whether a class is substantively present
- `cross_view` (optional; only if mapbox still paths exist):
- 2 images: Mapbox still + Sentinel‑2 chip
- assistant relates overhead context to satellite/labels
## Repository layout (files on the Hub)
A typical exported dataset root contains:
- `data/`
- `train.jsonl`
- `validation.jsonl`
- `test.jsonl`
- `images/...`
Satellite chips (copied or hardlinked from the source tree)
- `mapbox_stills/...` (optional)
Only included if present in the source dataset and enabled in the build config
- `analysis_images/...`
**Generated** procedural PNGs used by `production_analysis` rows
- `metadata/`
- `sft_metadata_rows/`
- `*.json` one sidecar per emitted SFT row (build provenance + specs used)
### `metadata/sft_metadata_rows/*.json` (row sidecars)
For each JSONL row, a sidecar is written under `metadata/sft_metadata_rows/` containing the fields used to build that row. Example fields vary by task but commonly include:
- `sample_id`
- `task`
- `tile_stem`
- `split`
- `image_paths`
For `production_analysis`, sidecars also include:
- `analysis_profile`
- `analysis_image_path`
- `analysis_image_spec` (the serializable spec used to render the PNG)
- `sentinel_sidecar` (a cleaned observation extracted from the original per-tile metadata)
## How this dataset is created
This dataset is built from an **input dataset root** that contains:
- `data/*.jsonl` with stable relative image paths such as:
- `images/.../<tile_stem>.png`
- optionally `mapbox_stills/.../<poi_id>.png`
- `metadata/**/*.json` per-tile sidecars containing at minimum:
- `tile_stem`
- `poi_id` (preferred) and/or `split`
- `caption` (for caption tasks)
- `class_fractions` (for analysis + some derived tasks)
- `regions` (for grounding tasks; pixel coords in the model output resolution)
The builder walks `metadata/**/*.json`, joins to `data/*.jsonl` by `tile_stem`, then emits multiple SFT tasks per tile depending on configuration.
## Intended use
- **Instruction tuning** / SFT for multimodal chat models that accept a list of messages with interleaved images.
- Learning stable formatting for:
- captions,
- grounding JSON outputs,
- profile-specific “analyst” summaries.
Not intended for:
- precise geospatial measurement,
- scientific change detection validation,
- legal or operational maritime detection claims.
## Known limitations / considerations
- Many targets are **procedural** (synthetic TiM-shaped signals and templated summaries).
- Grounding boxes are derived from metadata sidecars (not from human annotation in this builder).
- Cross-view reasoning depends on whether `mapbox_stills/` paths exist in the input dataset.
- Prompts are filtered to prevent accidental training on large internal blobs (certain substrings are banned).
## License
This repository does not define a universal license for all upstream imagery/metadata in the source dataset tree.
Please ensure you have the rights to redistribute the underlying source content used to build this dataset.
## Citation
If you use this dataset, please cite the dataset repo and the upstream sources it was derived from (your internal sat-bbox dataset tree and any imagery providers).
---
## Hub layout (sharded)
This snapshot was processed with `python data/scripts/shard_lfm_vl_dataset_for_hub.py` so that ``images/``, ``mapbox_stills/``, ``overlays/``, ``analysis_images/``, ``metadata/``, and ``metadata/sft_metadata_rows/`` use at most **9000** files per leaf directory (Hub git limit: 10k files per directory). JSONL paths may include ``sNNNNN/`` shard segments where needed.
---
## Hub layout (sharded)
This snapshot was processed with `python data/scripts/shard_lfm_vl_dataset_for_hub.py` so that ``images/``, ``mapbox_stills/``, ``overlays/``, ``analysis_images/``, ``metadata/``, and ``metadata/sft_metadata_rows/`` use at most **9000** files per leaf directory (Hub git limit: 10k files per directory). JSONL paths may include ``sNNNNN/`` shard segments where needed.
`NuTonic/sat-bbox-metadata-sft-v1` is a metadata-first, procedural VLM SFT dataset built from an existing “sat-bbox” style dataset tree (Sentinel‑2 chips + per-tile JSON metadata sidecars, optionally paired Mapbox stills). The goal is to create high-signal, production-shaped supervision for multimodal chat models, including captioning for satellite chips, grounding (bounding boxes) for land-cover regions, class-focused captions and absence checks, cross-view reasoning, and production-like analytical summaries. The dataset is generated using deterministic, rule-based construction for instruction tuning and format/behavior alignment, not as ground-truth scientific measurements. It includes multiple task types such as production_analysis, caption, grounding_all, grounding_per_class, class_focus, absence, and cross_view. The data format is JSONL with a chat-style messages list supporting multi-image and text interactions. The dataset also includes satellite images, optional Mapbox stills, and generated analysis images.
提供机构:
NuTonic
搜集汇总
数据集介绍
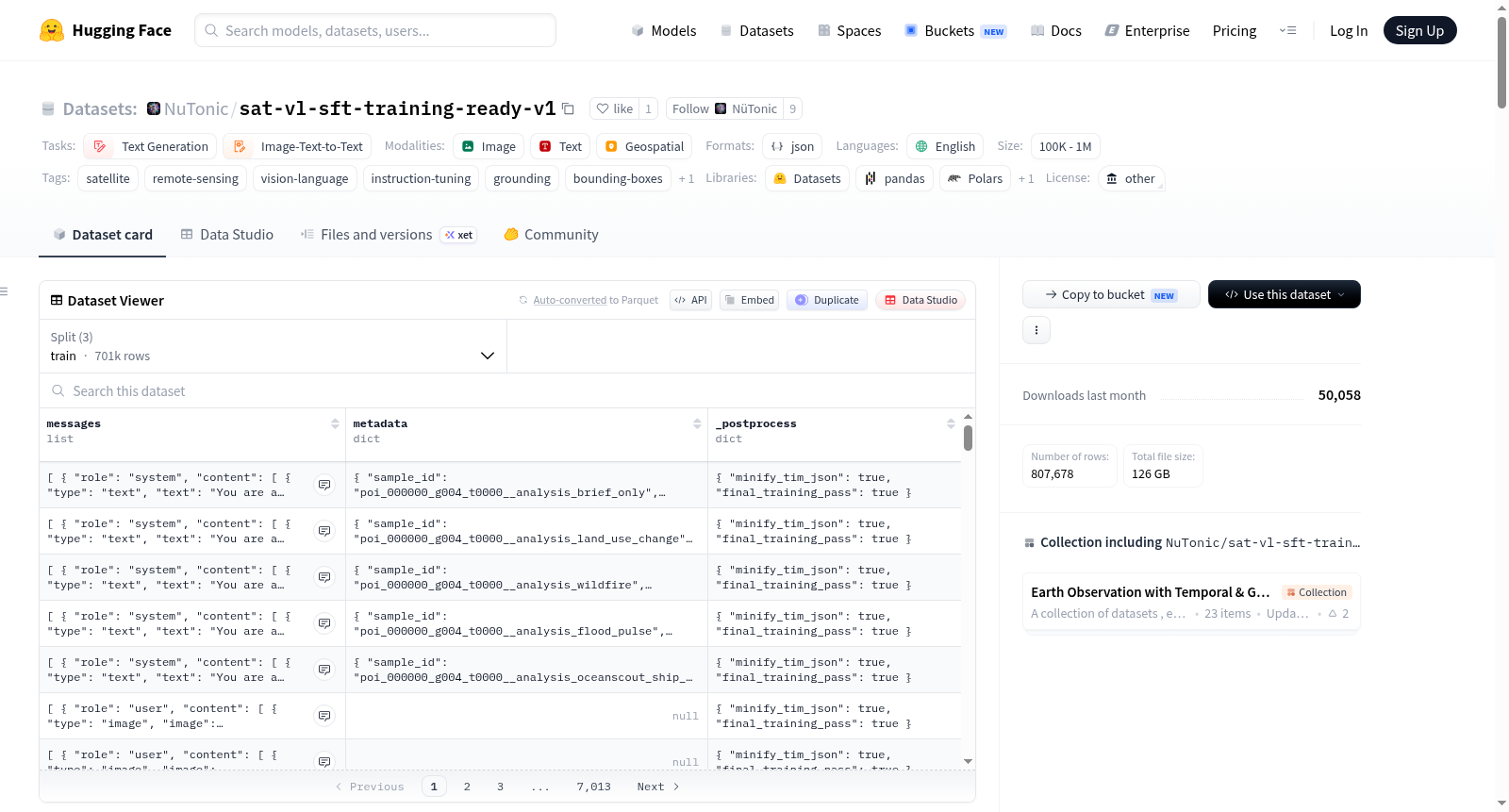
构建方式
该数据集基于已有的卫星边界框(sat-bbox)元数据树构建,采用确定性规则与合成方法进行程序化生成。构建过程从输入数据根目录中的元数据侧车文件出发,通过遍历metadata/**/*.json文件并与data/*.jsonl文件依据tile_stem字段进行关联,为每个瓦片生成多个监督式微调任务。数据集无需调用Mapbox API,仅依赖输入数据集中已存在的路径,通过转换元数据侧车中的信息,生成包括标题、边界框定位、类别聚焦、缺失检测及跨视角推理在内的多类型训练样本。最终输出为符合聊天格式的JSONL文件,并附带分析图像与元数据侧车以供溯源。
特点
该数据集的核心特点在于其元数据优先的程序化构建范式,为多模态聊天模型提供高信号、生产级形态的监督信号。数据集覆盖遥感领域的多种任务类型,包括卫星影像的标题生成、基于归一化坐标的边界框定位、特定土地覆盖类别的聚焦描述与缺失检验,以及可选的跨视角推理。此外,生产分析任务集成了哨兵二号影像、程序化生成的分析图像与紧凑的TiM格式分析JSON块,生成面向特定应用场景(如土地利用变化、野火、洪水脉冲)的分析摘要。土地覆盖类别遵循Google Dynamic World v1体系,共划分9类,确保语义一致性。
使用方法
该数据集适用于多模态聊天模型的指令微调与行为对齐。数据以JSONL格式存储,每行包含一个messages列表,遵循通用的视觉语言模型SFT流水线格式,支持system、user与assistant角色的交替对话。图像通过相对路径引用,用户可根据需要加载影像、地图底图及分析图像。数据集已按HuggingFace Hub的目录文件限制进行分片处理,确保各子目录文件数不超过9000个。使用时需注意,许多标注目标为程序化合成信号,边界框源于元数据而非人工标注,跨视角推理任务依赖于输入数据集中是否存在地图底图路径。
背景与挑战
背景概述
sat-vl-sft-training-ready-v1数据集由NuTonic团队于近年来构建,旨在为遥感领域的多模态对话模型提供高质量的监督微调数据。该数据集基于Sentinel-2卫星影像和元数据侧边文件,通过程序化方法生成,核心研究问题在于如何利用结构化元数据生成涵盖描述、目标检测、跨视角推理等任务的指令微调样本,从而提升视觉语言模型在动态世界土地覆盖分类与变化分析中的表现。其影响力体现在为遥感基础模型与领域智能体的对齐训练提供了规模化、可复现的数据范式。
当前挑战
该数据集主要挑战包括:1)遥感图像细粒度理解问题,如土地覆盖类别的精确边界检测与语义描述,需应对地物尺度多变、云层遮挡等影像质量干扰;2)构建过程中,元数据向多任务监督信号的转换依赖确定性规则与合成方法,缺乏人工标注的校准,易引入格式偏差;3)跨视角推理任务受限于Mapbox影像的可用性,数据覆盖不均衡,且分析型摘要需兼顾领域术语的准确表达与模型可读性,避免误导性科学推断。
常用场景
经典使用场景
在遥感视觉语言模型的指令微调领域,sat-vl-sft-training-ready-v1数据集被广泛用于构建多模态对话系统的训练基准。该数据集通过程序化生成策略,将哨兵二号影像与元数据侧边文件相结合,提供了涵盖影像描述、目标接地(归一化坐标边界框)、类别聚焦描述和缺失检测等多种监督信号。其典型用法是作为大规模多模态大语言模型的指令微调数据源,支持模型学习如何根据卫星影像生成结构化的分析和交互输出,尤其是在需要同时处理图像与文本信息的复杂对话任务中表现突出。
解决学术问题
该数据集有效解决了遥感领域中视觉语言模型缺乏大规模、高质量指令微调数据的学术难题。传统的遥感数据集多侧重于单一的分类或检测任务,难以支撑多模态模型在复杂语义理解与生成方面的需求。sat-vl-sft-training-ready-v1通过程序化构建,提供了多种任务格式的对齐数据,使研究者能够系统性地研究模型在接地描述、跨视图推理、缺失类别判断等子问题上的性能。其意义在于推动了遥感智能从简单的感知任务向深层次的语义交互与决策支持迈进,为地理空间人工智能的发展奠定了数据基础。
衍生相关工作
围绕该数据集已衍生出一系列具有影响力的研究工作,包括基于程序化数据构建的多模态指令微调方法、面向遥感影像的接地描述生成模型,以及跨视图推理框架。此外,数据集引入的生产式分析JSON结构与分析图像生成策略,启发了后续在时序预测和多任务联合学习方面的探索。研究者们还借鉴其元数据优先的设计理念,开发出针对特定领域(如城市扩张监测、生态退化评估)的定制化微调数据集,进一步拓展了遥感视觉语言模型在复杂地学问题中的应用边界。
以上内容由遇见数据集搜集并总结生成


