JiashengGuo/ExpressEdit
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/JiashengGuo/ExpressEdit
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
task_categories:
- image-text-to-image
- image-to-image
language:
- en
- zh
- ja
- ko
tags:
- art
pretty_name: ExpressEdit
size_categories:
- 10K<n<100K
viewer: false
---
# ExpressEdit: A Comprehensive Database for Stylized Facial Expression Editing

## 🚀 Interactive Demo
We provide a minimalist Retrieval-Augmented Generation (RAG) demo hosted on Hugging Face Spaces. You can input your own creative story snippet, and the system will retrieve the most matching expression tag from this database.
👉 **[Try the ExpressEdit RAG Demo Here](https://huggingface.co/spaces/JiashengGuo/ExpressEdit-RAG)**
## 📋 Dataset Summary
Facial expressions of characters are a vital component of visual storytelling. While current AI image editing models hold promise for assisting artists in the task of stylized expression editing, these models introduce global noise and pixel drift into the edited image, preventing the integration of these models into professional image editing software and workflows.
Furthermore, models primarily rely on textual prompts for image generation, which means users have to come up with detailed descriptions of expressions. This requirement on the prompt quality poses a cognitive burden for users and slows down the creation process.
**ExpressEdit** provides a solution by mapping free-form narrative intents to structured generation tags. To support the generation of diverse expressions according to different narrative needs, we compile a comprehensive expression database of 135 expression tags enriched with example stories and images designed for retrieval-augmented generation. This dataset accompanies the ExpressEdit Photoshop plugin, an open-source tool for fast and clean stylized expression editing.
## 🖼️ Dataset Composition
The dataset contains a rich combination of text, tags, and generated images:
### Expression Tags
* **Base Tags:** We obtained the expression tags from the Danbooru official website of face tags and eye tags. We manually choose the tags that can assist expression generation, filtering out explicit content, to obtain **135 expression tags**.
* **Definitions:** The definition for each expression tag was obtained from the official Danbooru website, specifying when the tag should and should not be applied.
* **Alternative Tags:** We also include alternative tags, which are Pixiv tags for each expression, or translations of the expression tag into Chinese, Japanese, or Korean. A total of **332 alternative tags** were obtained in this process.
* **Transformation-Free Flag:** Each tag is annotated with a flag indicating whether it can be reliably edited without applying Photoshop transformations such as Liquify. 100 out of 135 tags are transformation-free; the remaining 35 require quick manual operations.
### Example Stories
* To inspire users and facilitate the retrieval process, we generated 5 example stories for each tag with Gemini 3 Flash.
* The process is repeated for Chinese, English, Japanese, and Korean.
* The process results in **2,700 short stories** (135 tags × 5 stories × 4 languages).
### Example Images
* Example images were automatically generated based on 5 original character images.
* For each expression tag, we repeat the generation 5 times with different random seeds, resulting in **3,375 total edited images**.
## 🎯 Applications
There are two primary use cases for the ExpressEdit dataset:
### Retrieval-Augmented Generation (RAG)
Given the database, a user can conveniently use a VLM to retrieve the tag that is relevant to their stories, ideas, or specific editing instructions. By converting free-form user intent into structured expression tags, ExpressEdit refines the prompt into a format suitable for the image generation model, mitigating the prompt sensitivity of multi-modal generative models that potentially degrades image quality.

### Reference for Expression Stylization
The 3,375 image results can be used as a visual benchmark for how specific Danbooru tags influence the style, eye placement, and mouth shape of various 2D characters across different random seeds.
## 🏗️ Dataset Structure
The repository is organized into image folders and text-based JSONL files:
### Image Data
* **`results/` Directory:** Contains the 3,375 generated `.png` images. The files are named systematically as `c{character}_t{tag}_r{round}.png`, where `character` ranges from 1 to 5, `tag` is the zero-padded tag index from 001 to 135, and `round` is the random seed repetition from 1 to 5.
### Metadata & Text Files
* **`danbooru_expression_tags_full.jsonl`:** The core expression tag database. Each line is a JSON object with the following fields:
* `tag_id`: Integer identifier from 1 to 135.
* `tag`: The canonical Danbooru tag string (e.g., `+_+`, `averting_eyes`).
* `definition`: Human-readable explanation of the expression, sourced from the Danbooru wiki.
* `alternative_tags`: A list of Pixiv tags and translations into Chinese, Japanese, and Korean.
* `wai_illustrious_sdxl_16_auto_edit`: Integer flag (1 = transformation-free; 0 = requires Photoshop transformations such as Liquify).
* **`*_stories.jsonl`:** Four separate files (`english_stories.jsonl`, `chinese_stories.jsonl`, `japanese_stories.jsonl`, `korean_stories.jsonl`) containing the narrative backgrounds. Each line mirrors the fields of the tag database and adds:
* `responses`: A single string containing 5 numbered stories (prefixed `1.`, `2.`, ..., `5.`) separated by blank lines, which can be split on the numeric prefix to recover individual stories.
## 🚀 Usage
Download the full repository:
```bash
huggingface-cli download JiashengGuo/ExpressEdit --repo-type=dataset --local-dir ./ExpressEdit
```
Load the tag database and English stories in Python:
```python
import json
with open("danbooru_expression_tags_full.jsonl") as f:
tags = [json.loads(line) for line in f]
with open("english_stories.jsonl") as f:
stories = [json.loads(line) for line in f]
# Access the first tag
print(tags[0]["tag"], "-", tags[0]["definition"])
```
## 📜 Citation
If you find this dataset helpful in your research, please cite:
```bibtex
@article{tang2026expressedit,
title={ExpressEdit: Fast Editing of Stylized Facial Expressions with Diffusion Models in Photoshop},
author={Tang, Kenan and Guo, Jiasheng and Lin, Jeffrey and Qin, Yao},
journal={arXiv preprint arXiv:2604.03448},
year={2026}
}
```
## 🙏 Acknowledgements
The expression tags, definitions, and alternative tags are sourced from the [Danbooru](https://danbooru.donmai.us/) and [Pixiv Encyclopedia](https://dic.pixiv.net/en/) communities. The example stories were generated with Gemini 3 Flash.
提供机构:
JiashengGuo
搜集汇总
数据集介绍
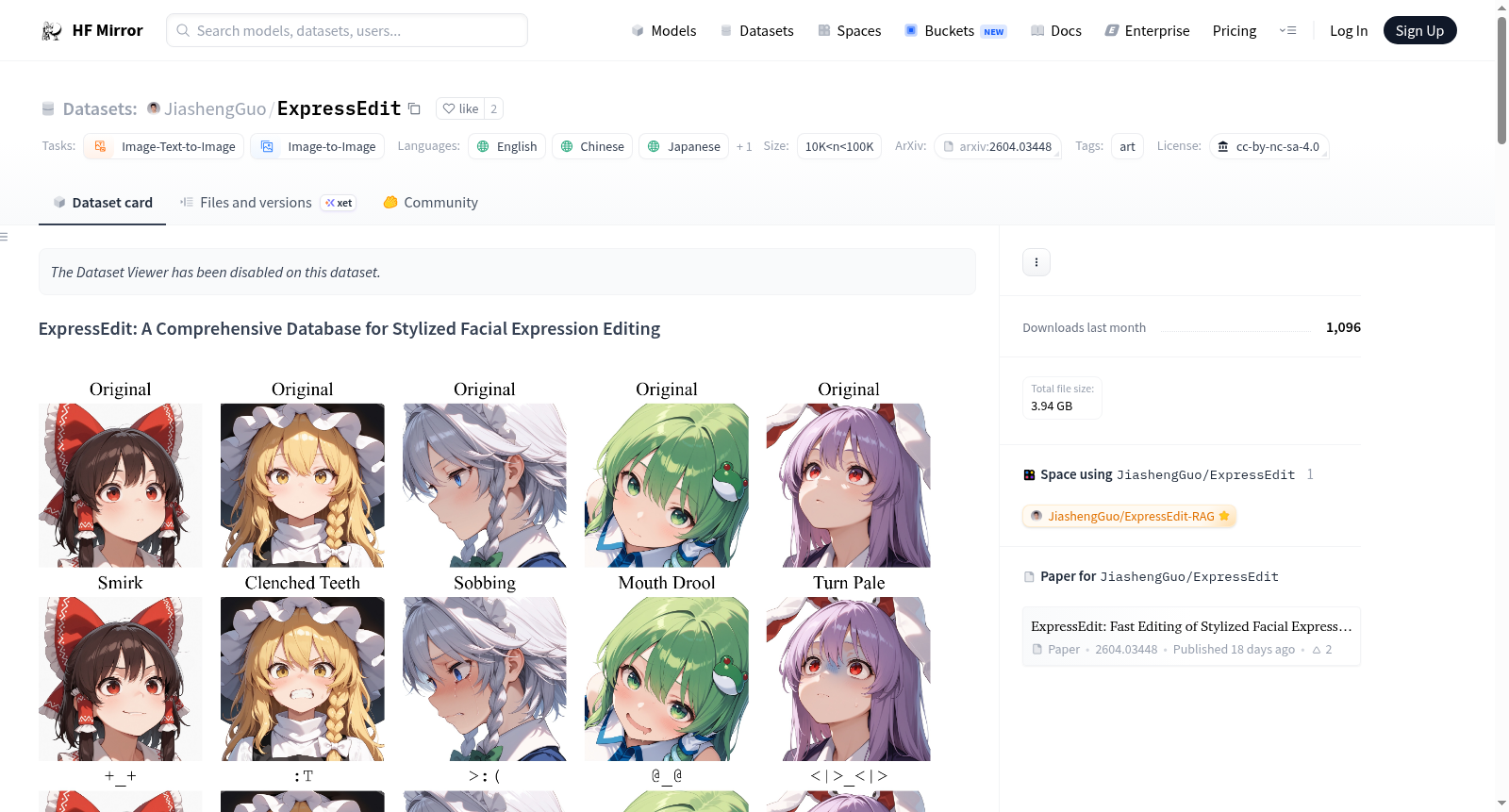
构建方式
在数字艺术创作领域,精准捕捉角色情感表达是提升叙事深度的关键。ExpressEdit数据集的构建始于对Danbooru官方面部与眼部标签的精心筛选,剔除了不适宜内容,最终确立了135个核心表情标签。每个标签均附有官方定义及适用情境说明,并扩展出包括Pixiv标签与多语言翻译在内的332个替代标签。为丰富数据维度,团队利用Gemini 3 Flash模型为每个标签生成了涵盖中、英、日、韩四种语言的示例故事,累计达2700条。同时,基于5个原始角色图像,通过不同随机种子自动生成了3375张风格化编辑图像,系统化构建了从文本意图到视觉呈现的映射体系。
特点
该数据集的核心特征在于其结构化的多模态设计,巧妙融合了语义标签、叙事文本与视觉范例。135个表情标签均标注了是否无需Photoshop液化等变形操作即可可靠编辑的标志,其中100个标签被标识为可直接应用,显著降低了专业工作流的操作门槛。数据集提供了跨语言的替代标签与示例故事,支持中、英、日、韩四语检索,增强了其在全球化创作环境中的适用性。生成的3375张图像以标准化命名规则组织,清晰展示了不同随机种子下同一标签对角色风格、眼部位置与嘴型产生的多样化影响,为风格化表达提供了可量化的视觉参考基准。
使用方法
用户可通过Hugging Face命令行工具下载完整数据集至本地目录,利用Python加载核心的JSONL元数据文件,便捷访问标签定义、替代标签及故事内容。数据集主要支持检索增强生成应用场景:用户可借助视觉语言模型,将自由形式的叙事意图或编辑指令与数据库中的结构化表情标签进行匹配,从而将模糊的用户需求转化为图像生成模型可精准理解的提示格式,有效缓解多模态生成模型因提示词敏感性导致的图像质量下降问题。此外,丰富的生成图像可作为风格化表情编辑的视觉基准,辅助研究者分析与评估不同标签对二次元角色面部特征的塑造规律。
背景与挑战
背景概述
在视觉叙事艺术领域,角色面部表情的精准刻画是传递情感与故事内涵的核心要素。随着人工智能图像编辑技术的演进,研究者们致力于开发能够辅助艺术家进行风格化表情编辑的工具。在此背景下,由研究人员于2026年创建的ExpressEdit数据集应运而生,其核心研究问题聚焦于如何将自由形式的叙事意图映射为结构化的生成标签,从而克服现有扩散模型在编辑过程中引入的全局噪声与像素漂移问题。该数据集通过整合来自Danbooru和Pixiv社区的135个表情标签,并辅以多语言示例故事与图像,为风格化面部表情编辑提供了系统的数据支持,推动了生成式模型在专业图像编辑工作流程中的集成与应用。
当前挑战
ExpressEdit数据集旨在应对风格化面部表情编辑领域的两大核心挑战。其一,现有AI图像编辑模型依赖文本提示生成图像,但用户往往难以构思精确的表情描述,导致提示质量不稳定,进而引发模型输出的图像质量下降与语义偏差,这限制了模型在专业创作环境中的实用性。其二,在数据构建过程中,研究人员需从海量社区标签中手动筛选适用于表情生成的标签,并过滤不当内容,同时为每个标签标注是否无需后期变形处理,这一过程涉及跨语言翻译与语义对齐,确保了数据集的多样性与可靠性,但亦对标注的准确性与一致性提出了较高要求。
常用场景
经典使用场景
在数字艺术创作领域,ExpressEdit数据集为风格化面部表情编辑提供了关键支持。其最经典的使用场景在于结合检索增强生成技术,艺术家或设计师可通过输入自由形式的叙事意图,系统自动从包含135个表情标签的数据库中检索最匹配的结构化标签,进而驱动扩散模型生成精确且风格一致的面部表情图像。这一流程显著降低了传统基于文本提示的编辑中对用户描述能力的依赖,实现了从创意叙事到视觉呈现的高效转化。
衍生相关工作
围绕ExpressEdit数据集,已衍生出若干经典研究工作。其核心论文《ExpressEdit: Fast Editing of Stylized Facial Expressions with Diffusion Models in Photoshop》系统阐述了数据集构建方法与插件实现。数据集所倡导的叙事意图到结构化标签的映射范式,为后续基于检索的表情编辑、跨语言多模态生成以及可控扩散模型的研究提供了基础。此外,其开源工具链也激励了社区在专业软件集成与人性化AI创作界面方向的进一步探索。
数据集最近研究
最新研究方向
在数字艺术创作与视觉叙事领域,面部表情的精准编辑是提升角色表现力的关键。ExpressEdit数据集通过构建一个包含135个结构化表情标签的数据库,将自由形式的叙事意图映射为可操作的生成指令,有效缓解了多模态生成模型对提示词的敏感性。当前研究聚焦于利用检索增强生成技术,将用户的故事片段自动匹配至合适的表情标签,从而优化图像编辑流程,减少人工干预。这一方向不仅推动了AI辅助创作工具在专业软件中的集成,也为表情风格化提供了可量化的视觉基准,促进了艺术创作与人工智能技术的深度融合。
以上内容由遇见数据集搜集并总结生成


