AUDETER
收藏arXiv2025-09-05 更新2025-11-24 收录
下载链接:
https://hf-mirror.com/datasets/wqz995/AUDETER
下载链接
链接失效反馈官方服务:
资源简介:
AUDETER是一个大规模、高度多样化的深度伪造音频数据集,旨在用于深度伪造音频检测的全面评估和稳健开发。它由超过4500小时的合成音频组成,由11个最新的TTS模型和10个声码器生成,共有300万个音频片段,使其成为规模最大的深度伪造音频数据集。数据集包括来自不同人类语音语料库的真实音频样本以及由这些样本生成的相应伪造音频,旨在模拟开放世界中的各种域偏移,并支持对深度伪造音频检测模型的全面评估。
AUDETER is a large-scale, highly diverse deepfake audio dataset designed for comprehensive evaluation and robust development of deepfake audio detection systems. Composed of over 4,500 hours of synthesized audio generated by 11 state-of-the-art TTS models and 10 vocoders, the dataset contains 3 million audio clips, making it the largest deepfake audio dataset to date. The dataset includes both genuine audio samples sourced from diverse human speech corpora and corresponding fake audio generated from these samples. It aims to simulate various domain shifts in the open world and support comprehensive evaluation of deepfake audio detection models.
提供机构:
澳大利亚墨尔本大学计算机与信息系统学院
创建时间:
2025-09-05
搜集汇总
数据集介绍
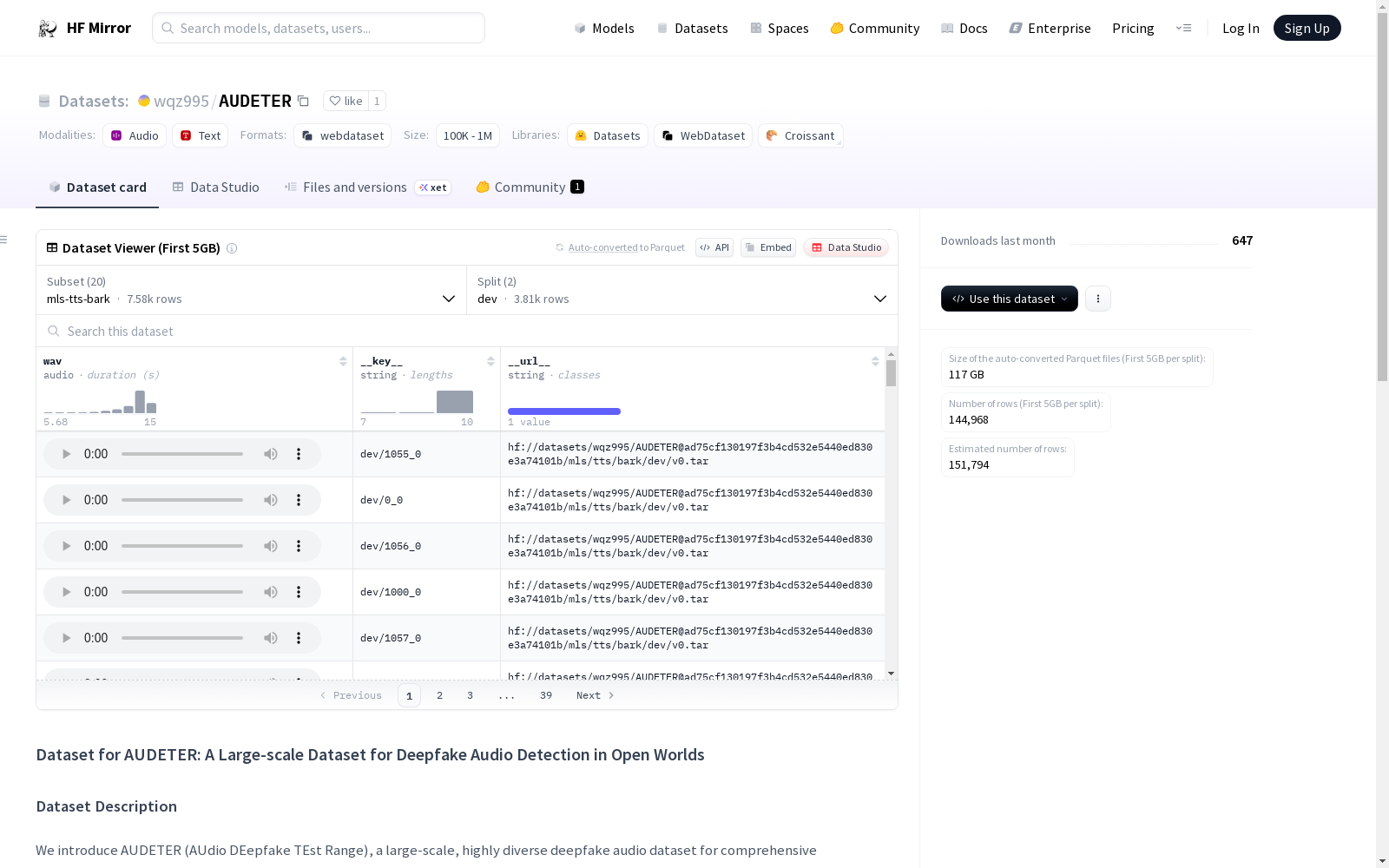
构建方式
在语音合成技术快速演进的背景下,AUDETER数据集通过集成21种前沿语音合成系统构建而成,涵盖11种文本到语音模型和10种声码器。该数据集采用双轨生成策略:文本到波形合成路径利用TTS系统处理来自四个真实语音语料库的转录文本,生成对应的合成音频;声码器路径则对原始真实音频进行波形重构。所有合成音频均基于相同的脚本与真实语音配对,确保了数据结构的系统性和平衡性,总规模达到4682小时,包含300万音频片段。
特点
AUDETER以其前所未有的规模与多样性著称,深度融合了来自不同录音环境、口音特征和语言风格的真实语音样本,覆盖广播级专业录音、众包朗读语音及多语言有声书等场景。合成音频囊括了基于大语言模型的最新TTS系统与高保真神经声码器,其可视化分析表明在声学特征空间中呈现出远超现有数据集的分布广度。该数据集通过严格的智能度与自然度评估,确保合成语音在语义保真度和听觉感知上接近人类水平,为开放环境下的泛化检测研究提供了关键支撑。
使用方法
研究者可通过组合不同的子集模块,系统模拟真实场景中的域偏移问题,例如将Common Voice与People's Speech子集作为训练数据,再以In-the-Wild子集进行跨域评估。数据集支持迭代式测试协议,每次将真实音频与特定合成版本配对检测,全面评估模型对未知合成模式的适应性。其标准化结构便于实施平衡批处理策略,在训练过程中均匀采样各类合成模式,同时支持大规模音频骨干网络的预训练与微调,为构建通用深度伪造检测器提供数据基础。
背景与挑战
背景概述
随着语音生成技术的飞速发展,合成音频的逼真度已达到以假乱真的程度,对数字内容真实性构成严峻挑战。AUDETER数据集由墨尔本大学与新加坡管理大学的研究团队于2025年联合创建,旨在解决开放场景下深度伪造音频检测的泛化性问题。该数据集汇集了来自4大人声语料库的真实语音,并采用21种前沿语音合成系统生成超过4500小时的300万条音频样本,其规模与多样性均超越现有基准。通过系统化构建平行数据对,该资源为开发面向未知合成方法与声学特征的通用检测模型提供了重要基础。
当前挑战
在领域问题层面,现有检测模型面临开放世界泛化困境:当测试样本来自训练时未见的语音合成系统或具有新颖声学特征的人声时,模型性能显著下降,误报率居高不下。构建过程中需应对双重挑战:其一需平衡大规模数据生成的计算成本与质量保障,2000小时GPU资源投入凸显工程复杂度;其二需确保跨语料库音频的语义对齐与声学多样性,同时维持合成音频在可懂度与自然度方面接近人类水平,这对质量评估体系设计提出更高要求。
常用场景
经典使用场景
在语音合成技术快速发展的背景下,AUDETER数据集为深度伪造音频检测提供了系统化评估框架。该数据集通过整合21种最新语音合成系统生成的4682小时合成音频,覆盖了文本到语音转换和声码器重构两种主流伪造模式,构建了包含300万音频片段的大规模测试基准。研究者可利用其平衡的数据结构,在统一脚本下对比不同合成系统的声学特征差异,模拟开放环境中可能遇到的新型伪造攻击。
解决学术问题
AUDETER有效解决了深度伪造音频检测中的领域泛化难题。传统方法在训练-测试领域偏移时性能显著下降,而该数据集通过融合4大人声语料库和21种合成系统,突破了封闭集二元分类的局限。实验表明,基于AUDETER训练的模型在跨域测试中将等错误率降低至4.17%,较基线提升44.1%-51.6%,为构建适应未知合成系统的通用检测器提供了数据基础。
衍生相关工作
基于AUDETER的基准测试催生了多项创新研究。XLR+R+A架构通过结合预训练音频骨干网络与评分头,在跨域检测中实现5.05%等错误率。后续工作进一步探索了自监督预训练策略,利用数据规模优势构建对未知合成模式的泛化能力。这些研究推动了基于数据中心的深度伪造检测范式转型,为应对持续演进的语音合成技术奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


