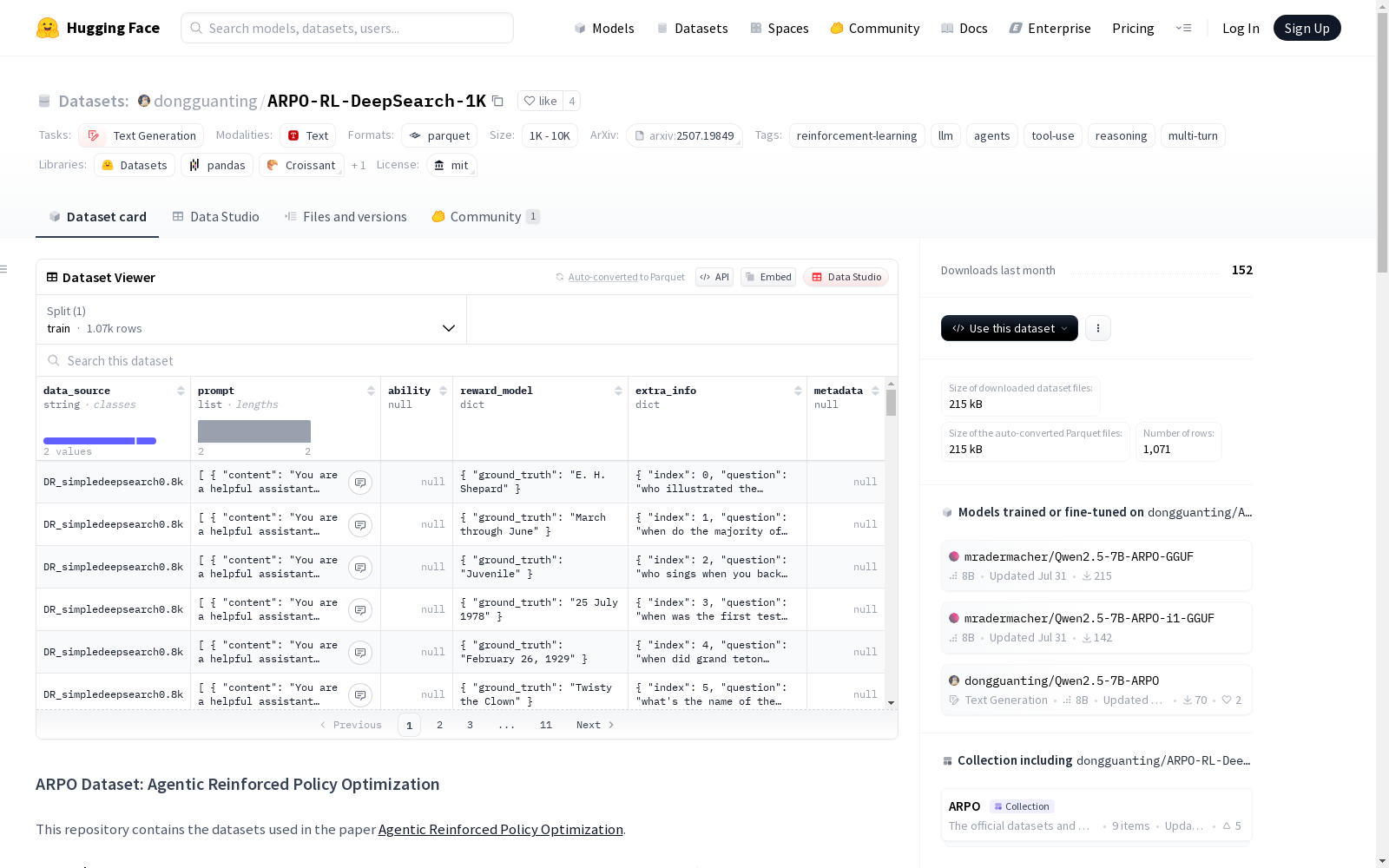
ARPO-RL-DeepSearch-1K
收藏Hugging Face2025-07-29 更新2025-07-30 收录
下载链接:
https://huggingface.co/datasets/dongguanting/ARPO-RL-DeepSearch-1K
下载链接
链接失效反馈官方服务:
资源简介:
ARPO数据集是一个用于验证Agentic Reinforced Policy Optimization算法有效性的数据集,包含推理和知识推理基准以及深度搜索能力基准的数据。它旨在帮助训练能够在实时动态环境中工作的多轮大型语言模型(LLM)代理。数据集分为推理和知识数据集、深度搜索数据集以及用于冷启动监督微调的ARPO-SFT-54K数据集。
创建时间:
2025-07-24
原始信息汇总
ARPO-RL-DeepSearch-1K 数据集概述
基本信息
- 许可证: MIT
- 任务类别: 文本生成
- 标签:
- 强化学习
- 大语言模型 (LLM)
- 代理
- 工具使用
- 推理
- 多轮对话
数据集描述
ARPO-RL-DeepSearch-1K 数据集是 Agentic Reinforced Policy Optimization (ARPO) 项目的一部分,专为测试具有深度搜索能力的 LLM 代理而设计。该数据集包含 1,000 个样本,其中 800 个来自 SimpleDeepSearch,200 个来自 WebDancer。
数据集内容
- 主要文件:
hard_search.parquet- 样本数量: 1,000
- 来源:
- SimpleDeepSearch: 800 个样本
- WebDancer: 200 个样本
相关数据集
- 推理与知识数据集:
dongguanting/ARPO-RL-Reasoning-10K- 训练集:
train_10k.parquet(10,000 个样本) - 测试集:
test.parquet(300 个样本,来自 8 个不同数据集)
- 训练集:
- 监督微调数据集:
dongguanting/ARPO-SFT-54K- 样本数量: 54,000
使用示例
bash
安装 Git LFS
git lfs install
克隆深度搜索 RL 数据集
git clone https://huggingface.co/datasets/dongguanting/ARPO-RL-DeepSearch-1K
引用
如需引用,请使用以下 BibTeX 条目: bibtex @misc{dong2025arpo, title={Agentic Reinforced Policy Optimization}, author={Guanting Dong and Hangyu Mao and Kai Ma and Licheng Bao and Yifei Chen and Zhongyuan Wang and Zhongxia Chen and Jiazhen Du and Huiyang Wang and Fuzheng Zhang and Guorui Zhou and Yutao Zhu and Ji-Rong Wen and Zhicheng Dou}, year={2025}, eprint={2507.19849}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2507.19849}, }
搜集汇总
数据集介绍
构建方式
在强化学习与工具调用融合的背景下,ARPO-RL-DeepSearch-1K数据集的构建采用了多源基准整合策略。该数据集从SimpleDeepSearch和WebDancer两个核心基准中精选了1000个样本,其中800个样本源自SimpleDeepSearch,200个样本源自WebDancer,旨在覆盖深度搜索任务中的多样化场景。构建过程中注重样本的复杂性和工具交互的多样性,以支持多轮推理和外部工具调用的强化学习训练需求。
特点
该数据集的核心特点在于其针对深度搜索任务的高挑战性和工具使用的复杂性。样本设计充分体现了多轮交互中语言模型的不确定性行为,特别是在工具调用后token熵分布的变化特征。数据集不仅包含丰富的搜索路径和工具调用序列,还提供了真实环境中的动态推理场景,能够有效验证智能体在深度搜索中的探索能力和策略优化效果。
使用方法
研究人员可通过Hugging Face平台直接下载该数据集,使用前需确保安装Git LFS以处理大文件。数据集以parquet格式存储,支持主流深度学习框架加载。典型应用包括训练基于强化学习的多轮对话智能体,特别是在工具调用后的不确定性探索阶段进行策略优化。用户可参照官方GitHub仓库提供的代码示例,进行模型微调或性能评估,实现与动态环境的实时对齐。
背景与挑战
背景概述
在人工智能领域,基于大型语言模型的智能体系统正逐渐成为研究热点。ARPO-RL-DeepSearch-1K数据集由董冠廷等研究人员于2025年提出,隶属于Agentic Reinforced Policy Optimization研究项目。该数据集专注于深度搜索领域,旨在解决多轮交互环境下LLM智能体与外部工具协同工作的核心问题。通过整合SimpleDeepSearch和WebDancer等权威基准的样本数据,它为评估智能体在复杂环境中的推理与执行能力提供了重要支撑,对推动具身智能和强化学习交叉领域的发展具有显著影响力。
当前挑战
深度搜索任务要求智能体在多轮交互中保持连贯的推理链条,同时有效利用外部工具获取关键信息。ARPO-RL-DeepSearch-1K构建过程中面临样本多样性保障与质量控制的挑战,需要平衡不同搜索难度的样本分布。模型在工具调用后产生的令牌熵增现象导致行为不确定性显著升高,这要求算法具备动态调整探索策略的能力。此外,数据收集需协调多个异构基准的格式标准化,并确保工具交互轨迹的真实性与可复现性,这些因素共同构成了数据集构建的核心难点。
常用场景
经典使用场景
在深度搜索任务中,该数据集为大型语言模型代理提供了多轮交互式环境下的工具调用验证场景。通过整合SimpleDeepSearch和WebDancer等基准测试的800个样本,它能够模拟真实世界中需要迭代搜索和复杂决策的过程。研究者利用该数据集训练模型在动态环境中进行序列决策,特别关注工具使用后的不确定性管理,从而提升代理在开放域问题解决中的探索能力。
实际应用
在实际应用层面,该数据集支撑的深度搜索代理可部署于智能问答系统和决策支持平台。这些系统能够通过多轮工具调用处理复杂信息检索任务,例如学术文献挖掘、商业情报分析和应急响应决策。基于数据集中WebDancer样本的训练,代理可以高效导航网络资源,执行深层信息提取,显著提升在开放域环境中处理模糊查询和长程依赖问题的实用性。
衍生相关工作
该数据集催生了多项基于熵自适应机制的强化学习研究,特别是在工具增强型语言模型领域。相关经典工作包括动态轨迹采样算法的改进、优势归因估计框架的优化,以及多模态工具集成策略的开发。这些研究显著推动了《Agentic Reinforced Policy Optimization》中提出的算法在计算推理、知识推理和深度搜索三大领域的应用拓展,形成了一系列具有高度影响力的衍生成果。
以上内容由遇见数据集搜集并总结生成


