OBI-Bench
收藏github2024-12-04 更新2024-12-06 收录
下载链接:
https://github.com/zijianchen98/OBI-Bench
下载链接
链接失效反馈官方服务:
资源简介:
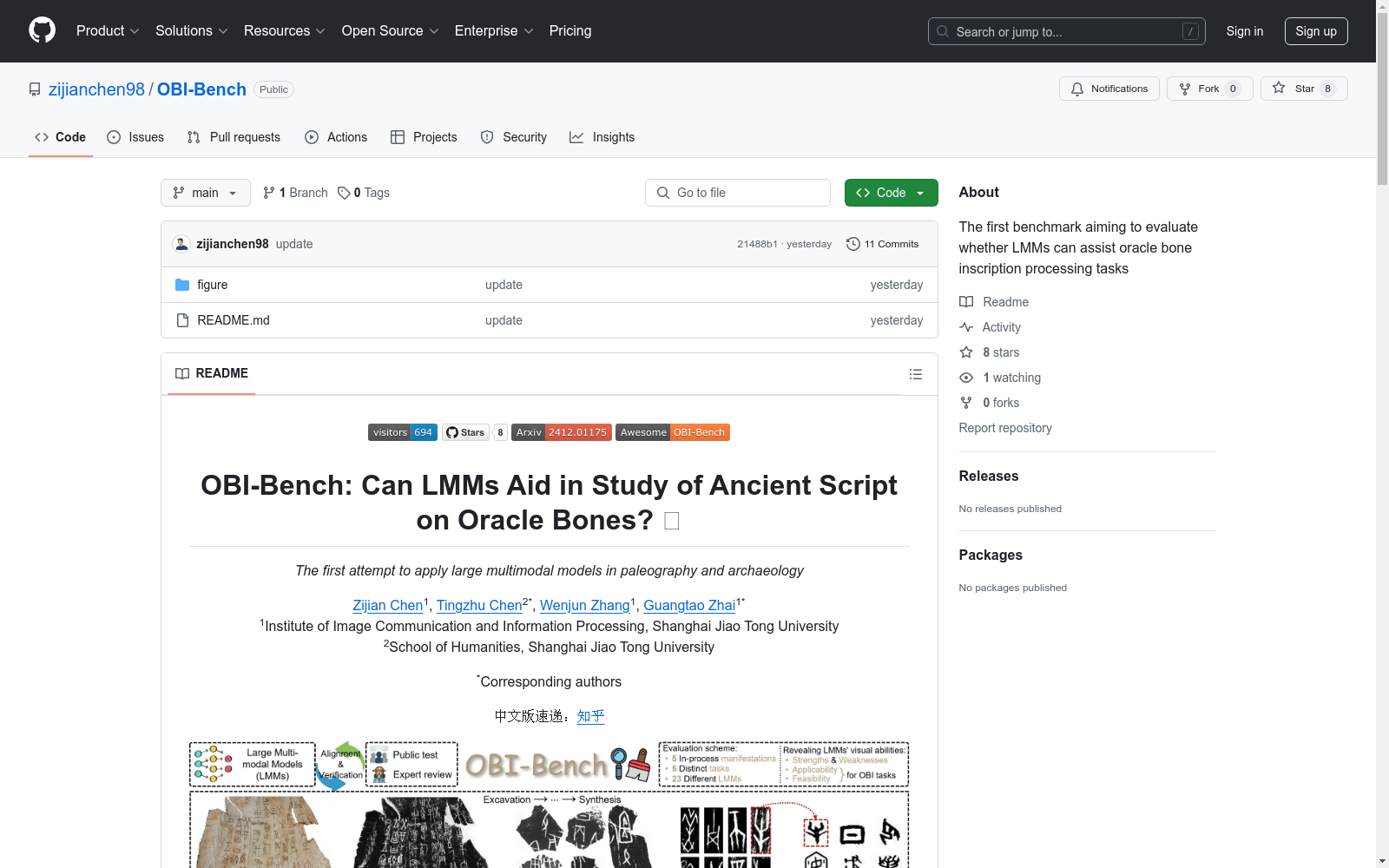
OBI-Bench是一个旨在评估大型多模态模型(LMMs)是否能辅助甲骨文处理任务的基准数据集。它包含五个任务:甲骨文字符识别、碎片文本重组、字符分类、图像检索和甲骨文解读。数据集收集了来自11个不同来源的5,523张甲骨文图像,并提出了原始甲骨文识别(O2BR)数据集和甲骨文重组(OBI-rejoin)数据集。
OBI-Bench is a benchmark dataset designed to evaluate whether large multimodal models (LMMs) can assist with oracle bone script processing tasks. It comprises five core tasks: oracle bone character recognition, fragment text reconstruction, character classification, image retrieval, and oracle bone script interpretation. The dataset contains 5,523 oracle bone script images collected from 11 distinct sources, and introduces two newly constructed sub-datasets: the Original Oracle Bone Recognition (O2BR) dataset and the Oracle Bone Rejoin (OBI-rejoin) dataset.
创建时间:
2024-12-02
原始信息汇总
OBI-Bench 数据集概述
概述
OBI-Bench 是一个应用于甲骨文研究的开放数据集,旨在通过大型多模态模型(LMMs)来辅助古代文字的研究。数据集包含五个主要任务:
- 识别:从原始甲骨或拓片中定位密集的甲骨文文字。
- 重组:将碎片化的文本片段重构为连贯的文本。
- 分类:将单个字符分类为其对应的含义。
- 检索:根据给定的甲骨文图像返回相关结果。
- 解译:解释甲骨文以进行历史和文化研究。
数据集发布
- 发布时间:2024年12月2日
- GitHub仓库:OBI-Bench
数据集来源
数据集收集了来自11个不同来源的5,523张甲骨文图像。由于缺乏公开的甲骨文识别和重组数据集,数据集提出了**原始甲骨识别(O2BR)数据集和甲骨文重组(OBI-rejoin)**数据集。
基准模型
数据集选择了23个最新的主流LMMs进行评估,包括6个专有LMMs和17个开源LMMs。
性能基准
数据集提供了五个任务的性能基准结果,包括:
- 识别任务
- 重组任务
- 分类任务
- 检索任务
- 解译任务
数据集待发布
- 原始甲骨识别(O2BR)数据集:即将发布
- 甲骨文重组(OBI-rejoin)数据集:即将发布
联系信息
- 作者:Zijian Chen
- 邮箱:zijian.chen@sjtu.edu.cn
引用
@misc{chen2024obibench, title={OBI-Bench: Can LMMs Aid in Study of Ancient Script on Oracle Bones?}, author={Zijian Chen and Tingzhu Chen and Wenjun Zhang and Guangtao Zhai}, year={2024}, eprint={2412.01175}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2412.01175}, }
搜集汇总
数据集介绍
构建方式
OBI-Bench数据集的构建基于对甲骨文(Oracle Bone Inscriptions, OBI)的深入研究,汇集了来自11个不同来源的5,523张OBI图像。该数据集旨在解决甲骨文研究中的五个关键任务:识别、重组、分类、检索和解译。为了填补现有数据集的空白,研究团队特别创建了原始甲骨文识别(O2BR)数据集和OBI-rejoin数据集,以支持这些任务的实现。
特点
OBI-Bench数据集的显著特点在于其多任务导向的设计,涵盖了甲骨文研究的多个阶段,从图像识别到文本重组,再到字符分类和历史解译。此外,该数据集还包含了多种字体和风格的甲骨文图像,确保了数据的多样性和广泛性。通过引入大型多模态模型(LMMs),OBI-Bench为考古学和古文字学研究提供了新的工具和方法。
使用方法
使用OBI-Bench数据集时,研究者可以针对五个主要任务进行模型训练和评估,包括甲骨文图像的识别、碎片文本的重组、字符的分类、基于图像的检索以及历史文化的解译。数据集提供了详细的图像来源和标注信息,便于研究者进行数据预处理和模型开发。此外,数据集还提供了多个基准模型和评估结果,供研究者参考和比较。
背景与挑战
背景概述
OBI-Bench数据集由上海交通大学的Zijian Chen、Tingzhu Chen、Wenjun Zhang和Guangtao Zhai等研究人员于2024年创建,旨在探索大型多模态模型(LMMs)在甲骨文研究中的应用。该数据集是首次尝试将LMMs应用于古文字学和考古学领域,旨在通过五个具体任务——识别、重组、分类、检索和解读,来解决甲骨文研究中的关键问题。这一创新不仅推动了人工智能技术在文化遗产保护中的应用,也为古文字学研究提供了新的工具和方法。
当前挑战
OBI-Bench数据集在构建过程中面临多重挑战。首先,由于公开的甲骨文识别数据集稀缺,研究人员不得不自行收集和创建原始甲骨文识别(O2BR)数据集和甲骨文重组(OBI-rejoin)数据集。其次,甲骨文的多阶段字体变化和复杂性增加了分类和解读任务的难度。此外,如何有效评估和比较不同LMMs在甲骨文任务中的表现,也是一个重要的研究挑战。这些挑战不仅涉及技术层面的算法优化,还包括对甲骨文历史和文化背景的深入理解。
常用场景
经典使用场景
在古文字学与考古学领域,OBI-Bench数据集的经典使用场景主要集中在甲骨文的研究与分析。该数据集通过提供甲骨文图像及其相关任务,如识别、拼接、分类、检索和解译,为学者们提供了一个系统化的工具。这些任务不仅有助于自动化处理大量甲骨文数据,还能辅助研究人员在历史和文化研究中更深入地理解甲骨文的含义和背景。
解决学术问题
OBI-Bench数据集解决了古文字学研究中长期存在的数据处理难题。传统上,甲骨文的识别和解译依赖于人工,效率低下且易出错。该数据集通过引入大规模多模态模型,显著提升了甲骨文处理的自动化水平,从而加速了学术研究的进程。此外,数据集的多任务设计使得研究人员能够更全面地探索甲骨文的各个方面,为古文字学研究提供了新的视角和方法。
衍生相关工作
OBI-Bench数据集的发布激发了大量相关研究工作。许多学者和研究团队基于该数据集开发了新的算法和模型,以进一步提升甲骨文处理的精度和效率。例如,有研究者利用数据集中的图像数据进行深度学习模型的训练,取得了显著的识别和分类效果。此外,数据集的多任务设计也为跨学科研究提供了丰富的资源,促进了人工智能与古文字学的深度融合。
以上内容由遇见数据集搜集并总结生成


