Classic_Cars
收藏Hugging Face2025-07-15 更新2025-07-15 收录
下载链接:
https://huggingface.co/datasets/ROSCOSMOS/Classic_Cars
下载链接
链接失效反馈官方服务:
资源简介:
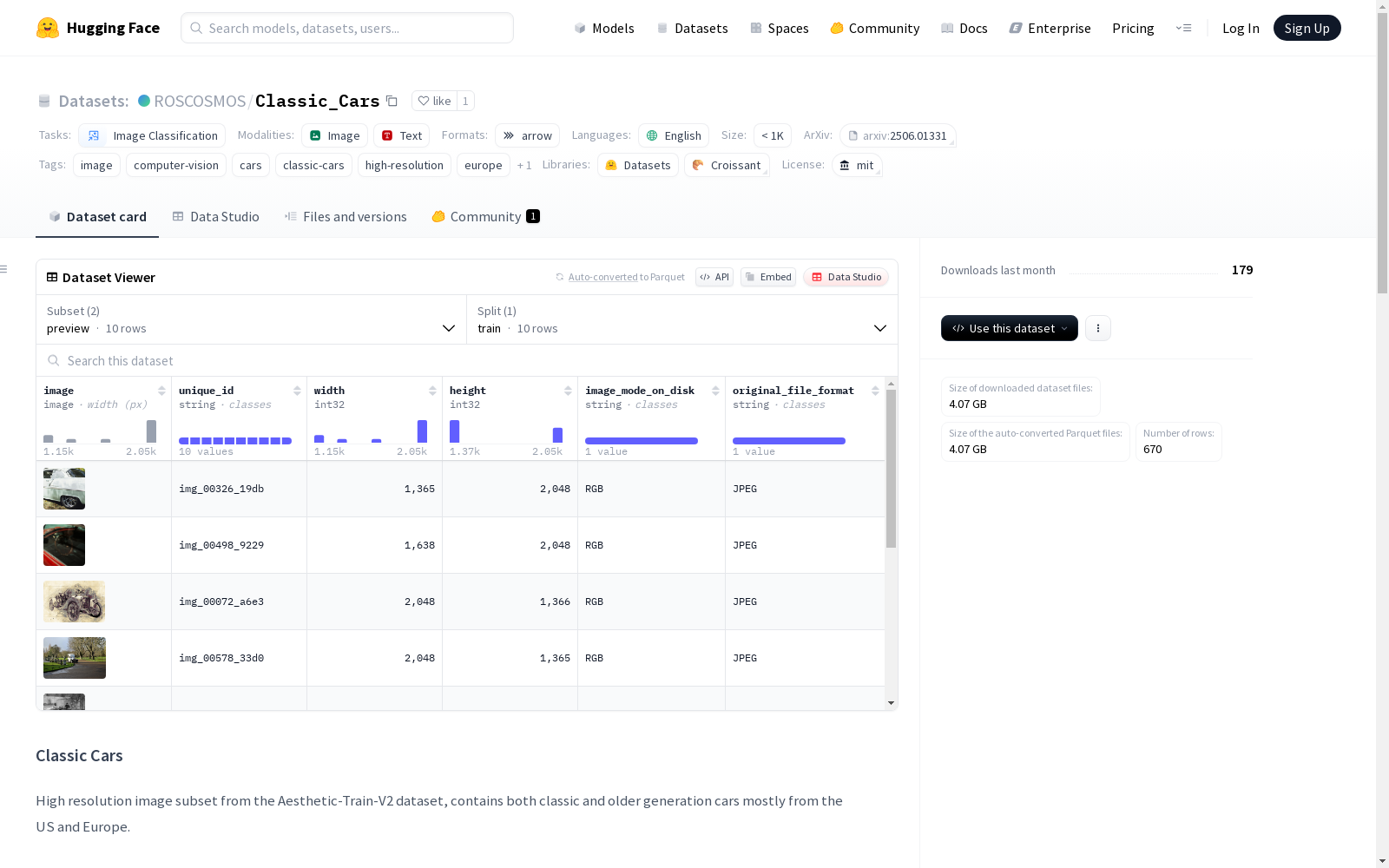
Classic Cars数据集是一个高分辨率图像的子集,主要包含来自美国和欧洲的古典和老一代汽车。这个数据集是从Aesthetic-Train-V2数据集中精选出来的,包含了660张图像,每张图像的平均大小约为5.7 MB压缩后。所有图像都被标准化为RGB模式,并以95%的质量保存,以确保一致性。
创建时间:
2025-07-13
原始信息汇总
数据集概述:Classic Cars
基本信息
- 数据集名称: Classic Cars
- 许可证: MIT
- 标签: 图像、计算机视觉、汽车、经典汽车、高分辨率、欧洲、美国
- 任务类别: 图像分类
- 语言: 英语
- 版本: 1.0.0
- 总图像数: 660
- 平均图像大小: ~5.7 MB(压缩后)
- 主要内容: 经典汽车
- 标准化: 所有图像均标准化为RGB模式,并以95%的质量保存以确保一致性。
数据集结构
配置
- train配置:
- 数据文件:
train/**/*.arrow - 特征:
image: 图像数据unique_id: 唯一标识符width: 图像宽度(像素)height: 图像高度(像素)original_file_format: 原始文件格式image_mode_on_disk: 磁盘上的图像模式
- 数据文件:
- preview配置:
- 数据文件:
preview/**/*.arrow - 特征:
image: 图像数据(适合浏览器的版本)unique_id: 唯一标识符width: 图像宽度(像素)height: 图像高度(像素)image_mode_on_disk: 磁盘上的图像模式original_file_format: 原始文件格式
- 数据文件:
数据集创建与来源
- 原始主数据集:
zhang0jhon/Aesthetic-Train-V2- 链接: https://huggingface.co/datasets/zhang0jhon/Aesthetic-Train-V2
- 原始许可证: MIT
- 筛选方法: CLIP检索/手动筛选
数据集内容
- train分割: 包含完整的高分辨率图像数据和相关元数据,推荐用于模型训练和完整数据分析。
- preview分割: 包含
train分割中的一小部分随机图像,图像经过降采样和重新压缩以适应浏览器预览。
引用
bibtex @inproceedings{zhang2025diffusion4k, title={Diffusion-4K: Ultra-High-Resolution Image Synthesis with Latent Diffusion Models}, author={Zhang, Jinjin and Huang, Qiuyu and Liu, Junjie and Guo, Xiefan and Huang, Di}, year={2025}, booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, } @misc{zhang2025ultrahighresolutionimagesynthesis, title={Ultra-High-Resolution Image Synthesis: Data, Method and Evaluation}, author={Zhang, Jinjin and Huang, Qiuyu and Liu, Junjie and Guo, Xiefan and Huang, Di}, year={2025}, note={arXiv:2506.01331}, }
注意事项
- 偏见考虑: 请注意原始数据集中的固有偏见以及自动筛选和手动筛选过程中可能引入的偏见。
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,高质量图像数据集的构建对模型性能至关重要。Classic_Cars数据集源自Aesthetic-Train-V2大型高分辨率图像库,通过CLIP检索与人工筛选相结合的双重策展方法,精选出660幅经典汽车图像。所有图像均统一转换为RGB模式并以95%质量压缩保存,确保数据格式的一致性。
特点
该数据集以高分辨率图像为核心特色,平均单图尺寸达5.7MB,清晰呈现欧美经典汽车的细节特征。数据采用Apache Arrow格式高效存储,包含图像像素尺寸、原始格式等元数据字段。特别提供预览版本分割,通过降采样处理适配网页端快速浏览,同时保留完整训练集供深度分析使用。
使用方法
研究人员可通过HuggingFace平台直接加载train分割进行图像分类模型训练,利用unique_id字段实现样本追踪。预览分割支持在线可视化检查数据质量。数据集遵循MIT许可协议,使用者需注意原始数据偏差及CLIP筛选可能引入的偏见,建议结合相关论文所述方法进行模型优化。
背景与挑战
背景概述
经典汽车视觉数据集Classic_Cars由Roscosmos团队于2025年构建,源自大规模高分辨率图像数据集Aesthetic-Train-V2的精炼子集。该数据集聚焦于欧美地区经典与老式汽车的高清图像采集,旨在推动计算机视觉领域在细粒度图像分类与高分辨率图像处理方面的研究。通过CLIP检索与人工筛选相结合的双重策展机制,该数据集为超分辨率图像合成与生成模型提供了高质量的基准数据,对自动驾驶系统的历史车型识别与数字文化遗产保护具有重要参考价值。
当前挑战
该数据集核心挑战在于解决经典汽车车型的细粒度分类问题,需区分不同年代、制造商及型号间高度相似的外观特征。构建过程中面临原始数据分布偏差的挑战,欧美车型的过度集中可能导致模型泛化能力受限;高分辨率图像(平均5.7MB)对存储与计算资源提出苛刻要求,且人工筛选过程中主观判断可能引入标注一致性风险。此外,CLIP检索机制的固有偏差需通过多轮人工校验进行补偿,以保障数据质量的可靠性。
常用场景
经典使用场景
在计算机视觉领域,Classic_Cars数据集作为高分辨率图像分类任务的基准数据集,广泛应用于经典车型识别与分类研究。该数据集通过提供660张高质量欧美经典汽车图像,为图像分类模型训练提供了丰富的视觉特征样本,特别适用于深度学习模型在细粒度视觉识别任务中的性能验证。
实际应用
在工业应用层面,该数据集为汽车文化遗产数字化保存提供了技术实现路径,支持博物馆馆藏车辆的数字孪生构建。同时可用于汽车设计领域的风格演化分析,为现代汽车造型设计提供历史参考,并在智能交通系统中辅助实现经典车型的自动识别与分类管理。
衍生相关工作
基于该数据集衍生的经典工作包括Diffusion-4K超高清图像合成框架,该成果在CVPR 2025会议上展示了潜在扩散模型在超高分辨率图像生成领域的突破性进展。后续研究进一步拓展了生成模型在历史车辆图像修复与风格迁移方面的应用,形成了完整的视觉生成技术研究体系。
以上内容由遇见数据集搜集并总结生成


