PhysVidBench
收藏arXiv2025-07-22 更新2025-07-23 收录
下载链接:
https://cyberiada.github.io/PhysVidBench
下载链接
链接失效反馈官方服务:
资源简介:
PhysVidBench是一个用于评估文本到视频(T2V)模型中物理常识推理能力的基准数据集。该数据集由383个精心挑选的提示组成,重点关注工具使用、材料属性和程序交互,这些都是在物理合理性至关重要的领域。每个提示都用于生成视频,并通过一个三阶段的评估流程进行评估,包括从提示中制定基于物理的问题、用视觉语言模型对生成的视频进行字幕标注,以及使用语言模型仅根据字幕回答几个涉及物理的问题。PhysVidBench通过强调当前T2V评估中被忽视的可用性和工具介导行为,提供了一个结构化的、可解释的框架,用于评估生成视频模型中的物理常识。
PhysVidBench is a benchmark dataset designed to evaluate physical commonsense reasoning capabilities in text-to-video (T2V) models. This dataset comprises 383 carefully curated prompts, focusing on three core domains where physical plausibility is paramount: tool use, material properties, and procedural interaction. Each prompt is used to generate videos, which are then evaluated via a three-stage assessment workflow: formulating physics-based questions from the original prompts, generating captions for the generated videos using vision-language models, and using large language models (LLMs) to answer multiple physics-related questions solely based on the generated captions. By highlighting the usability and tool-mediated behaviors that have been neglected in current T2V evaluations, PhysVidBench provides a structured, interpretable framework for assessing physical commonsense in video generation models.
提供机构:
Koç University, Istanbul, Turkey; Koç University ˙I¸s Bank Artificial Intelligence Center (KUIS AI), Istanbul, Turkey; Hacettepe University, Ankara, Turkey
创建时间:
2025-07-22
原始信息汇总
PhysVidBench 数据集概述
数据集基本信息
- 名称: PhysVidBench
- 开发团队:
- Baris Sarper Tezcan*, Enes Sanli*, Erkut Erdem, Aykut Erdem (* equal contributions)
- 机构: 1 Koç University (土耳其), 2 Hacettepe University (土耳其)
- 目标: 评估文本到视频(T2V)生成模型在物理常识推理方面的能力
核心内容
- 基准规模: 包含383个精心设计的提示(prompts)
- 评估维度: 7个物理常识维度
- 动作与程序理解(AU)
- 力与运动(FM)
- 基础物理(FP)
- 材料交互与转换(MT)
- 物体属性与功能(OP)
- 空间推理(SR)
- 时间动态(TD)
评估方法
- 三阶段评估流程:
- 从提示中制定基于物理的问题
- 使用视觉语言模型为生成视频添加字幕
- 让语言模型仅基于字幕回答物理相关问题
评估模型
- 测试模型 (共12个):
- CogVideoX (2B/5B)
- Sora
- Veo-2
- Cosmos (7B/14B)
- Hunyuan Video
- LTX-Video
- MAGI-1
- VideoCrafter2
- Wan2.1 (1.3B/14B)
关键发现
- 最佳表现模型: Wan2.1 (14B) 平均得分33.9
- 普遍弱点: 空间推理(SR)和时间动态(TD)维度表现最差
- 提示影响: 上采样提示(upsampled prompts)普遍比基础提示表现更好
- 模型规模: 更大模型通常表现更好,但规模不是决定因素
数据可视化
- 提供雷达图展示Top 5模型在基础提示和上采样提示下的表现对比
相关资源
- 论文: PhysVidBench
- GitHub: 链接
- Huggingface数据集: 链接
搜集汇总
数据集介绍
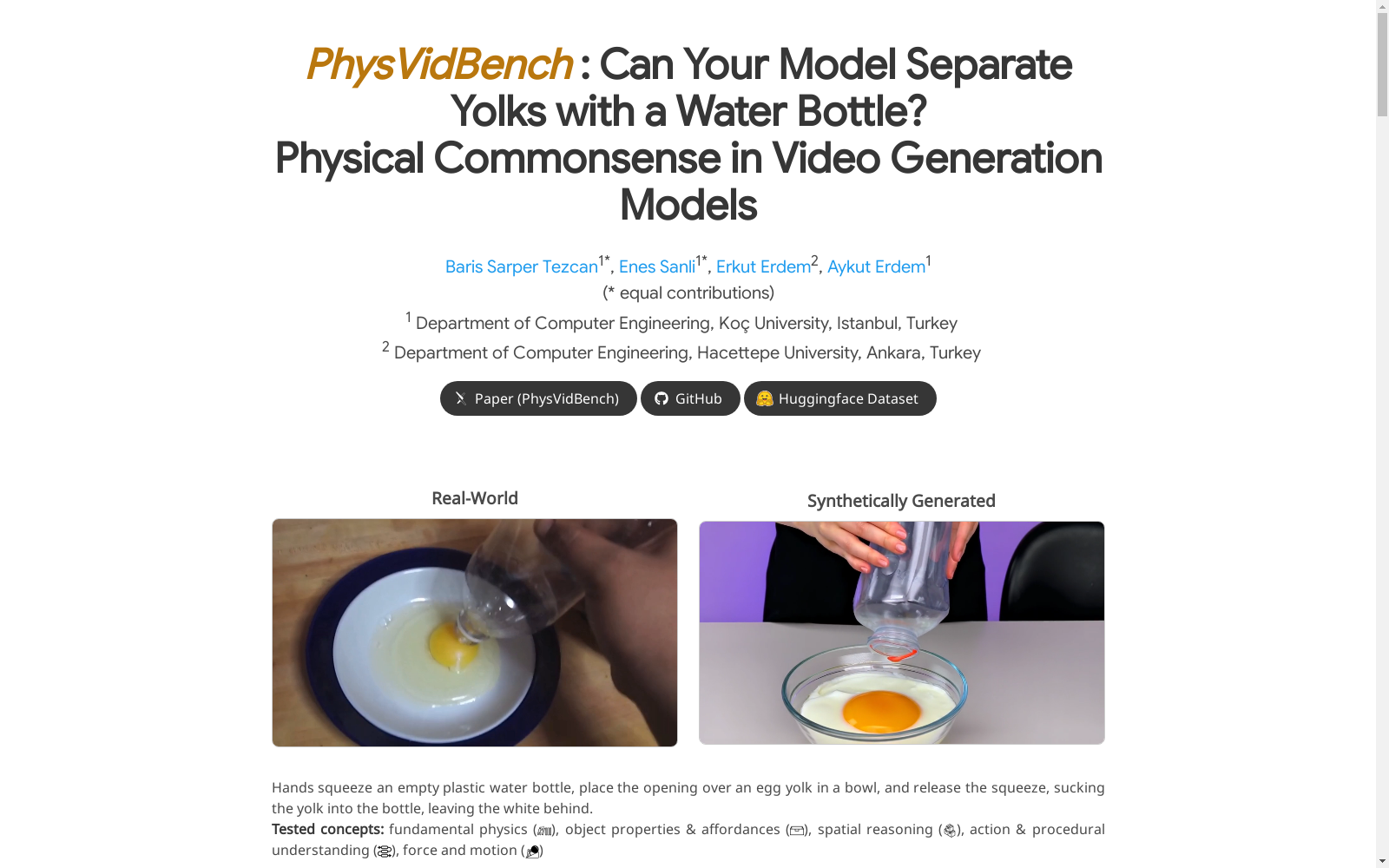
构建方式
PhysVidBench数据集的构建采用了多阶段流程,首先从PIQA数据集中筛选出涉及工具使用和物体功能性的物理常识问题,随后通过大语言模型将这些解决方案转化为简洁的视频生成提示。在此基础上,进一步通过提示增强技术,增加物理细节和因果结构,最终形成383个基础提示及其对应的增强版本。每个提示均围绕日常物理场景设计,强调工具介导的交互和物体功能性。
使用方法
使用PhysVidBench数据集时,首先根据提供的提示生成视频,随后通过三阶段评估流程进行物理常识推理能力的测试。第一阶段从增强提示生成物理相关问题,第二阶段利用视频字幕模型生成密集字幕,第三阶段通过语言模型基于字幕回答问题。这种间接评估策略有效减少了直接视频评估中的幻觉问题,提供了更可靠和可解释的物理常识评分。
背景与挑战
背景概述
PhysVidBench是由Koç大学和Hacettepe大学的研究团队于2025年提出的一个专注于评估文本到视频(T2V)生成模型物理常识理解能力的基准数据集。该数据集包含383个精心设计的提示,涵盖了工具使用、材料属性和程序交互等关键物理常识维度。PhysVidBench的创建旨在解决当前T2V模型在生成视频时常常违反物理常识的问题,例如因果关系、物体行为和工具使用等方面。该数据集通过三阶段评估流程(问题生成、视频描述和语言模型回答)为相关领域提供了一个结构化、可解释的评估框架,显著推动了生成视频模型的物理常识理解研究。
当前挑战
PhysVidBench面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,该数据集旨在解决T2V模型在生成物理合理视频方面的不足,特别是工具使用、物体功能和材料交互等复杂场景中的物理常识推理。在构建过程中,研究团队需要精心设计提示以确保其物理合理性,同时开发可靠的评估流程以避免视觉语言模型(VLM)评分中的幻觉问题。此外,数据集的评估还需要处理空间推理和时间动态等难以建模的物理常识维度,这些维度对当前T2V模型构成了显著挑战。
常用场景
经典使用场景
PhysVidBench作为评估文本到视频生成模型物理常识理解能力的基准,其经典使用场景主要集中在测试模型对工具使用、材料属性和程序性交互的物理合理性理解。通过精心设计的383个提示,该数据集能够系统地评估模型在生成视频时是否遵循基本的物理规律,如因果性、对象行为和工具使用的合理性。这些场景特别强调日常生活中的物理互动,如使用塑料水瓶分离蛋黄、用牙签在糖霜上绘制波浪线等,从而全面检验模型在复杂物理交互中的表现。
解决学术问题
PhysVidBench解决了当前文本到视频生成模型在物理常识理解上的关键学术问题。现有模型虽然在视觉质量和时间连贯性上有所突破,但在生成物理合理的视频时仍存在明显不足。该数据集通过引入基于物理常识的评估维度(如力和运动、对象属性与功能、空间推理等),填补了现有基准在工具使用和对象功能理解上的空白。其间接评估策略(基于视频描述的问答)有效规避了直接视觉语言模型评分中的幻觉问题,为研究社区提供了一个结构化、可解释的评估框架,推动了物理常识推理在生成模型中的研究进展。
实际应用
PhysVidBench的实际应用场景广泛涉及需要物理合理性验证的领域。在机器人任务规划中,该数据集可评估模拟环境生成的视频是否符合真实世界的物理约束;在教育内容生成领域,能检验教学视频中工具使用和材料交互的正确性;在虚拟现实和增强现实应用中,可确保虚拟对象的物理行为与用户直觉一致。此外,自动驾驶系统的仿真测试也可通过该基准验证场景生成的物理合理性,从而提高AI系统在真实环境中的可靠性。
数据集最近研究
最新研究方向
随着文本到视频(T2V)生成技术的快速发展,PhysVidBench数据集的提出填补了当前评估体系在物理常识理解方面的空白。该数据集聚焦于工具使用、材料属性和程序性交互等核心维度,通过精心设计的383个提示词构建了一个系统化的评估框架。最新研究揭示了当前T2V模型在空间推理和时间动力学等复杂物理场景中的显著短板,即使最先进的模型在这些维度上的表现仍显不足。值得注意的是,提示词增强技术能有效激发模型的潜在物理推理能力,特别是对于大型模型而言。该数据集通过引入基于字幕的问答评估管道,避免了直接视觉语言模型评分带来的幻觉问题,为视频生成模型的物理常识理解提供了可解释、可靠的评估基准。相关研究正在推动生成模型在机器人、具身智能等需要真实物理交互的应用场景中的发展。
相关研究论文
- 1Can Your Model Separate Yolks with a Water Bottle? Benchmarking Physical Commonsense Understanding in Video Generation ModelsKoç University, Istanbul, Turkey; Koç University ˙I¸s Bank Artificial Intelligence Center (KUIS AI), Istanbul, Turkey; Hacettepe University, Ankara, Turkey · 2025年
以上内容由遇见数据集搜集并总结生成


