llm-jp/llm-jp-4-8b-thinking-dpo-data
收藏Hugging Face2026-04-24 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/llm-jp/llm-jp-4-8b-thinking-dpo-data
下载链接
链接失效反馈官方服务:
资源简介:
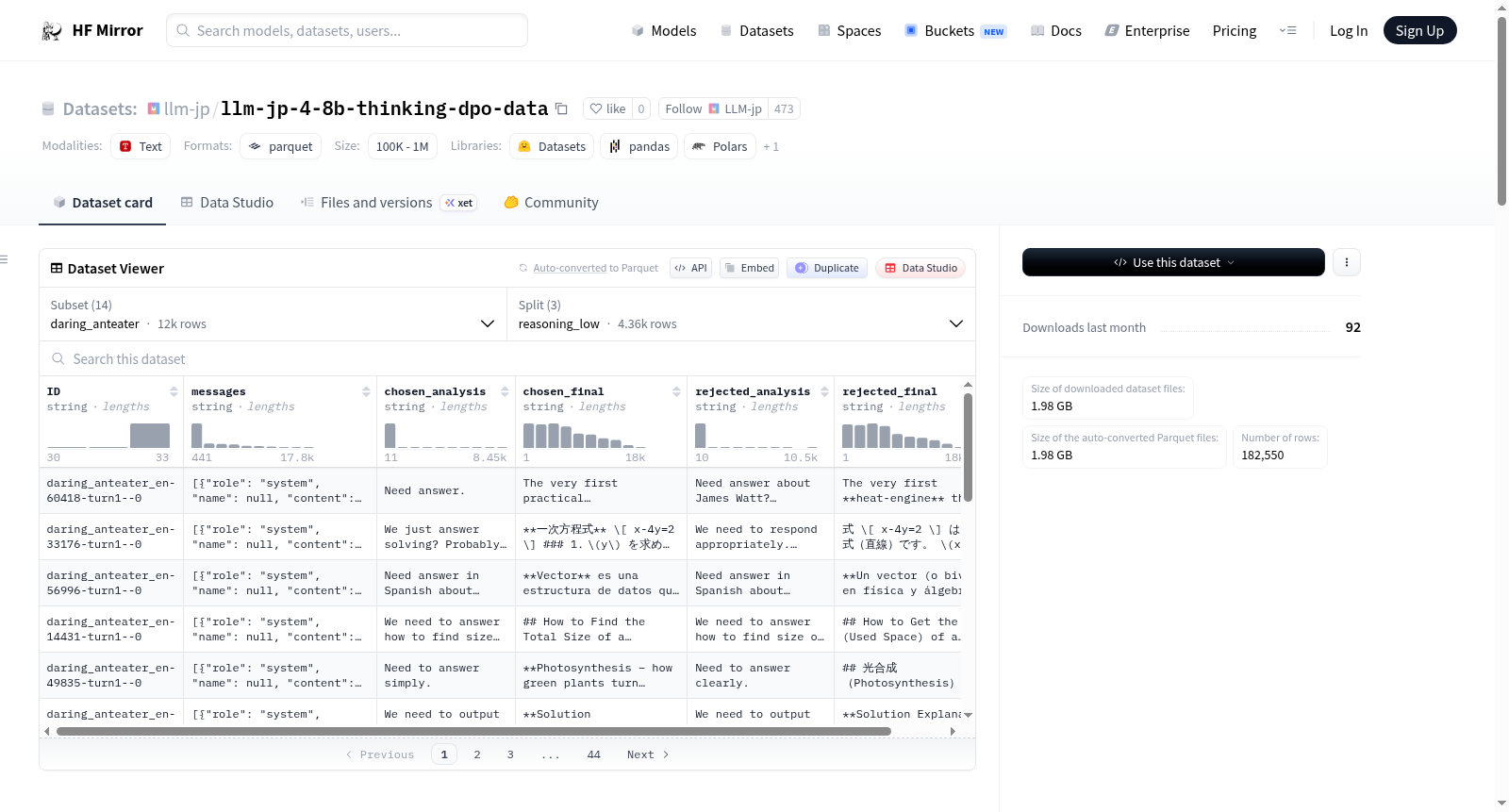
该数据集名为llm-jp-4-8b-thinking-dpo-data,是一个用于训练llm-jp-4-8b-thinking模型的直接偏好优化(DPO)数据集。数据集包含针对给定提示的配对响应(选择的和拒绝的),并根据不同的推理努力设置(低、中、高)进行分类。响应是通过监督微调模型生成的,并由gpt-oss-120b进行评估。数据集从多个来源编译而成,具有不同的许可证,其中一些由于重新分发限制而未包含在内。数据集包括多个配置,具有详细的特征和分割。
This dataset, named llm-jp-4-8b-thinking-dpo-data, is a Direct Preference Optimization (DPO) dataset used to train the llm-jp-4-8b-thinking model. It consists of paired responses (chosen and rejected) for given prompts, categorized into different reasoning effort settings (low, medium, high). The responses are generated using a supervised fine-tuned model and evaluated by gpt-oss-120b. The dataset is compiled from various sources with different licenses, some of which are not included due to redistribution restrictions. The dataset includes multiple configurations with detailed features and splits.
提供机构:
llm-jp
搜集汇总
数据集介绍
构建方式
在大型语言模型偏好对齐的研究领域中,llm-jp-4-8b-thinking-dpo-data数据集通过系统化的方法构建而成。该数据集整合了来自多个开源数据源的多样化指令与对话数据,包括daring_anteater、flan、jaster以及多个日语维基百科提取任务和数学推理数据集。针对每个输入提示,研究团队利用经过监督微调的模型生成包含分析过程和最终答案的候选回复对,随后借助gpt-oss-120b等先进模型进行自动化评估与偏好标注,从而形成被采纳(chosen)与被拒绝(rejected)的响应配对,为直接偏好优化提供了高质量的训练样本。
特点
该数据集在构建思路上展现出鲜明的结构化特征,其核心在于为每个对话上下文同时提供优选与次选的响应路径,并细致记录了模型在推理过程中的中间分析步骤与最终结论。数据按照推理复杂度被划分为低、中、高三个层级,使得模型训练能够针对不同难度的任务进行梯度优化。此外,数据集融合了数学推导、代码生成、多轮对话以及跨语言任务等多种模态,覆盖了广泛的应用场景,为提升模型在复杂推理与指令遵循方面的能力提供了多维度的监督信号。
使用方法
在大型语言模型的直接偏好优化训练流程中,该数据集可直接用于训练类似llm-jp-4-8b-thinking的模型。使用者可通过HuggingFace数据集库加载特定的配置项,例如daring_anteater或llmjp_magpie_sft_v1.0,并依据研究需求选择不同推理难度等级的分支数据。每条数据样本均包含完整的消息历史、成对的分析与最终答案,训练时可将chosen_final与rejected_final作为正负样本对输入损失函数。研究人员亦可结合不同数据源的特性进行混合训练或针对性微调,以探索模型在特定领域如日语处理或逻辑推理上的性能边界。
背景与挑战
背景概述
在大型语言模型(LLM)的指令微调与对齐研究领域,直接偏好优化(DPO)已成为一种关键方法,旨在使模型输出更符合人类价值观与复杂推理需求。llm-jp-4-8b-thinking-dpo-data数据集应运而生,专为训练llm-jp-4-8b-thinking模型而构建。该数据集整合了来自多个知名开源项目的数据源,包括NVIDIA的Daring-Anteater、AllenAI的FLAN变体以及llm-jp社区自研的日语语料等,覆盖了聊天、数学、编码及多轮对话等多种任务类型。其核心研究问题在于通过高质量的偏好对数据,提升模型在复杂推理场景下的判断能力与输出质量,从而推动日语及多语言大模型在遵循指令与逻辑严谨性方面的发展。
当前挑战
该数据集致力于解决大模型对齐中偏好学习的核心挑战,即如何精准区分不同推理路径的优劣,并引导模型生成兼具逻辑性与合规性的回答。构建过程中的首要挑战在于数据源的异构性与质量把控,需从十余种不同领域与许可协议的原始数据中筛选、清洗并构造一致的偏好对。其次,偏好标注的可靠性构成另一难题,依赖GPT-OSS-120B等先进模型进行自动评估,其评判标准的一致性、偏差控制以及对日语等特定语言语境的理解深度均直接影响数据质量。此外,数据集的规模与多样性平衡亦需审慎考量,以确保模型在不同推理难度级别上均能获得有效训练。
常用场景
经典使用场景
在大型语言模型对齐研究领域,直接偏好优化(DPO)已成为微调模型以符合人类偏好的关键范式。该数据集作为llm-jp-4-8b-thinking模型的训练基础,其经典使用场景在于为日语及多语言指令遵循与推理任务提供高质量的偏好对数据。通过整合来自daring_anteater、flan、jaster等多个知名数据源的多样化内容,并依据推理复杂度划分为低、中、高三个层级,该数据集能够系统性地训练模型区分更优与次优的响应,从而提升模型在复杂问题解答中的逻辑一致性与准确性。
解决学术问题
该数据集主要致力于解决大型语言模型对齐中的核心学术问题,即如何在没有显式奖励模型的情况下,通过偏好数据直接优化模型策略以产生更符合人类价值观的响应。它通过提供包含分析过程与最终答案的成对偏好数据,为研究社区探索DPO、对比学习等先进对齐算法在日语及跨语言场景下的有效性提供了基准。其意义在于推动了语言模型从单纯模仿向可解释、可控制推理的演进,为构建更安全、可靠且具备深层认知能力的AI系统奠定了数据基础。
衍生相关工作
围绕该数据集衍生的经典工作主要包括llm-jp系列模型的持续迭代与优化,例如基于DPO训练的llm-jp-4-8b-thinking模型本身已成为日语大模型研究的重要基准。同时,该数据集的结构设计启发了后续多个日语偏好数据集的构建方法,促进了如WizardLM8x22B逻辑数学编码、Nemotron系列指令遵循数据等资源的整合与再利用。这些工作共同推动了日语NLP社区在模型对齐、多轮对话及复杂推理任务上的算法创新与性能提升。
以上内容由遇见数据集搜集并总结生成


