CBT-Bench
收藏Hugging Face2024-10-19 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/CBT-LLM/CBT-Bench
下载链接
链接失效反馈官方服务:
资源简介:
CBT-Bench是一个基准数据集,旨在评估大型语言模型(LLMs)在辅助认知行为疗法(CBT)方面的熟练程度。该数据集分为三个层次,每个层次关注CBT的不同关键方面,包括基础知识背诵、认知模型理解和治疗性反应生成。目标是评估LLMs在专业心理健康护理各个阶段的支持能力,特别是CBT。数据集包含多个任务和数据文件,如多项选择题、认知扭曲分类和治疗性反应生成练习。
CBT-Bench is a benchmark dataset designed to evaluate the proficiency of Large Language Models (LLMs) in assisting Cognitive Behavioral Therapy (CBT). It is divided into three levels, each focusing on distinct core aspects of CBT: basic knowledge recitation, cognitive model comprehension, and therapeutic response generation. The goal is to assess the capability of LLMs to support various stages of professional mental health care, with a particular focus on CBT. The dataset encompasses multiple tasks and data files, including multiple-choice questions, cognitive distortion classification, and therapeutic response generation exercises.
创建时间:
2024-10-19
原始信息汇总
CBT-Bench Dataset
概述
CBT-Bench 是一个用于评估大型语言模型(LLMs)在辅助认知行为疗法(CBT)中熟练程度的基准数据集。数据集分为三个层次,每个层次关注 CBT 的不同关键方面,包括基础知识背诵、认知模型理解和治疗响应生成。目标是评估 LLMs 在专业心理健康护理各个阶段的支持能力,特别是 CBT。
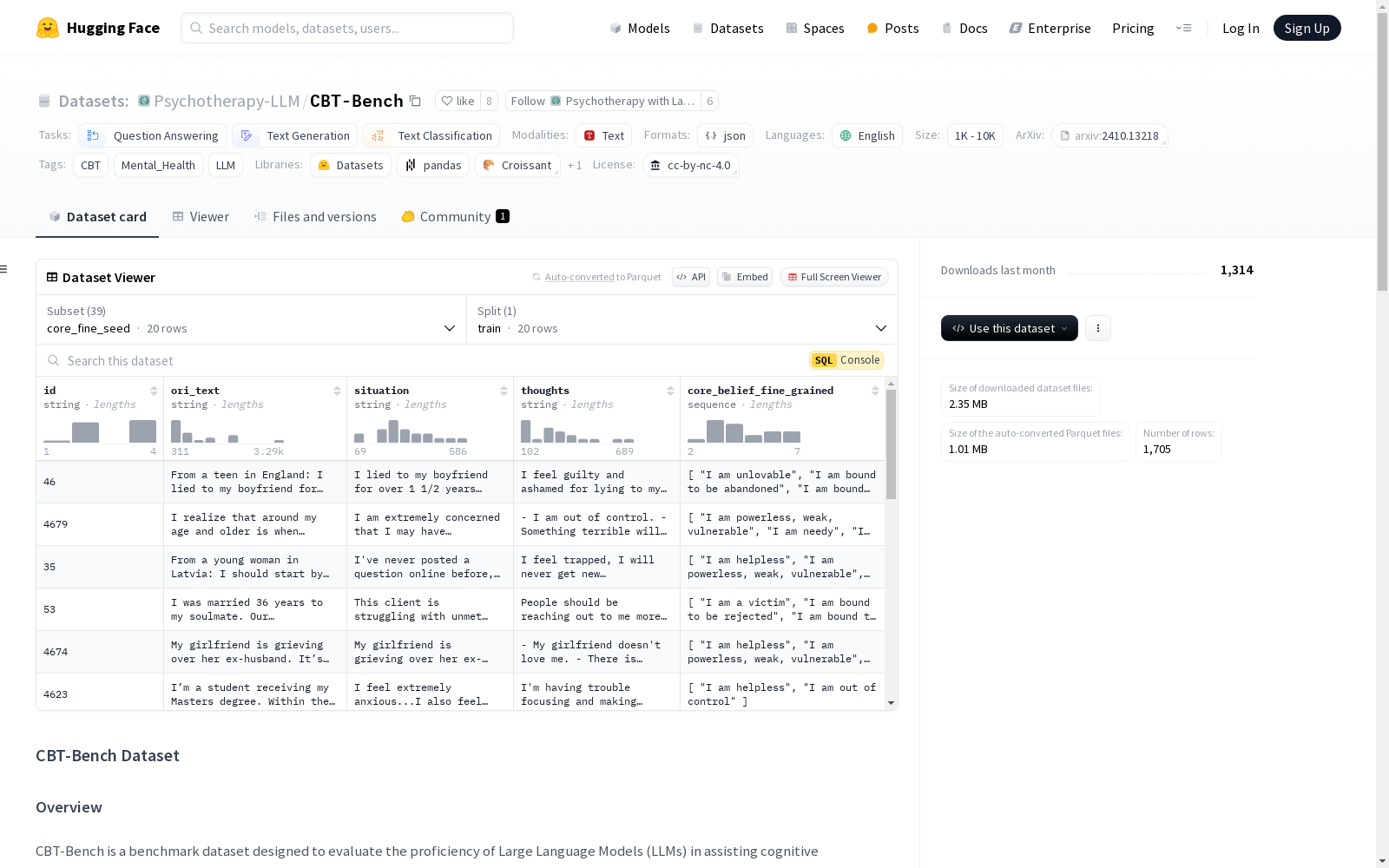
数据集结构
数据集分为三个主要层次,每个层次包含特定任务:
第一层:基础 CBT 知识获取
- 数据集: CBT-QA (
qa_test.json) - 描述: 包含 220 个与 CBT 概念、实用知识、案例研究等相关的多项选择题。
qa_seed.json包含用于训练或上下文学习的保留示例。由于这些是 CBT 考试问题,目前无法披露答案。未来,我们可能会考虑将其转化为排行榜。
第二层:认知模型理解
- 数据集:
- CBT-CD (
distortions_test.json) (认知扭曲分类): 146 个认知扭曲示例,分为十类,如全有或全无思维、个人化、读心术等。 - CBT-PC (
core_major_test.json) (主要核心信念分类): 184 个示例分为三个核心信念(无助、不可爱、无价值)。 - CBT-FC (
core_fine_test.json) (细粒度核心信念分类): 112 个示例进一步分为 19 个细粒度核心信念类别。 distortions_seed.json,core_major_seed.json, 和core_fine_seed.json包含用于训练或上下文学习的保留示例。
- CBT-CD (
第三层:治疗响应生成
- 数据集: CBT-DP (
CBT-DP/) - 描述: 包含 156 个练习,分为十个关键的 CBT 会话方面,涵盖各种治疗场景,难度逐渐增加。除了人类参考外,我们还发布了模型生成内容。
引用
@misc{zhang2024cbtbenchevaluatinglargelanguage, title={CBT-Bench: Evaluating Large Language Models on Assisting Cognitive Behavior Therapy}, author={Mian Zhang and Xianjun Yang and Xinlu Zhang and Travis Labrum and Jamie C. Chiu and Shaun M. Eack and Fei Fang and William Yang Wang and Zhiyu Zoey Chen}, year={2024}, eprint={2410.13218}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2410.13218}, }
搜集汇总
数据集介绍
构建方式
CBT-Bench数据集旨在评估大型语言模型(LLMs)在辅助认知行为疗法(CBT)中的能力。该数据集通过三个层次构建,分别聚焦于CBT的基础知识掌握、认知模型理解以及治疗响应生成。每个层次包含特定的任务,如基础知识的问答、认知扭曲分类、核心信念分类以及治疗场景的生成。数据集的构建基于专业的CBT考试题目和实际治疗案例,确保了数据的专业性和实用性。
特点
CBT-Bench数据集的特点在于其多层次的结构设计,涵盖了CBT的多个关键方面。数据集不仅包含基础知识的问答,还涉及认知扭曲和核心信念的分类任务,以及治疗场景的生成。每个任务都经过精心设计,旨在全面评估LLMs在CBT中的表现。此外,数据集还提供了人类参考和模型生成的对比,便于进行模型性能的详细分析。
使用方法
CBT-Bench数据集的使用方法多样,适用于不同层次的研究需求。对于基础知识的评估,可以使用`qa_test.json`进行问答测试;对于认知模型的理解,可以通过`distortions_test.json`和`core_major_test.json`进行分类任务;对于治疗响应的生成,可以利用`CBT-DP/`中的数据进行场景生成和对比分析。此外,数据集中的`dp-pairwise-comparison.json`提供了模型生成与人类参考的对比,便于进行模型性能的详细评估。
背景与挑战
背景概述
CBT-Bench数据集由Mian Zhang等研究人员于2024年创建,旨在评估大型语言模型(LLMs)在认知行为疗法(CBT)中的辅助能力。该数据集由三个层次构成,分别聚焦于CBT的基础知识掌握、认知模型理解以及治疗反应生成。通过多任务评估,CBT-Bench为LLMs在心理健康领域的应用提供了系统性基准,特别是在CBT这一专业领域。该数据集的发布为研究LLMs在心理健康支持中的潜力提供了重要工具,推动了相关领域的研究进展。
当前挑战
CBT-Bench数据集在构建和应用中面临多重挑战。首先,CBT作为一门专业性极强的心理治疗方法,其知识体系和实践场景的复杂性对数据集的构建提出了高要求,需确保数据的准确性和代表性。其次,数据集的多层次结构要求任务设计具有逻辑性和连贯性,以全面评估LLMs的能力。此外,治疗反应生成任务涉及对复杂情境的模拟,这对模型的生成质量和人类参考的标注提出了高要求。最后,数据集的规模相对较小,可能限制了模型的泛化能力,未来需进一步扩展数据量以提升评估的可靠性。
常用场景
经典使用场景
CBT-Bench数据集在评估大型语言模型(LLMs)在认知行为疗法(CBT)中的辅助能力方面具有经典应用。该数据集通过三个层次的任务,分别测试模型在CBT基础知识掌握、认知模型理解以及治疗反应生成方面的表现。研究人员可以利用该数据集来评估LLMs在心理健康领域的专业支持能力,特别是在CBT治疗过程中的应用效果。
衍生相关工作
CBT-Bench数据集的发布推动了相关领域的研究进展。基于该数据集,研究人员开发了多种改进LLMs在CBT中应用的模型和方法。例如,一些研究专注于提高模型在认知扭曲分类中的准确性,另一些则致力于优化治疗反应生成的多样性和适用性。这些工作不仅丰富了LLMs在心理健康领域的研究成果,还为未来的AI辅助治疗提供了新的思路和方向。
数据集最近研究
最新研究方向
CBT-Bench数据集在认知行为疗法(CBT)领域的最新研究方向主要集中在评估大型语言模型(LLMs)在心理健康支持中的实际应用。随着LLMs在自然语言处理领域的快速发展,其在心理治疗辅助中的潜力逐渐显现。CBT-Bench通过三个层次的任务设计,系统地评估了LLMs在CBT基础知识掌握、认知模型理解以及治疗反应生成等方面的表现。特别是在治疗反应生成层次,数据集通过对比人类参考与模型生成的结果,深入探讨了LLMs在复杂治疗场景中的适用性与局限性。这一研究方向不仅推动了LLMs在心理健康领域的应用,也为未来开发更智能、更个性化的心理治疗工具提供了重要参考。
以上内容由遇见数据集搜集并总结生成


