Maitreyajayaraj/data_dogri_Agrade_v1_07.json
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://hf-mirror.com/datasets/Maitreyajayaraj/data_dogri_Agrade_v1_07.json
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
---
提供机构:
Maitreyajayaraj
搜集汇总
数据集介绍
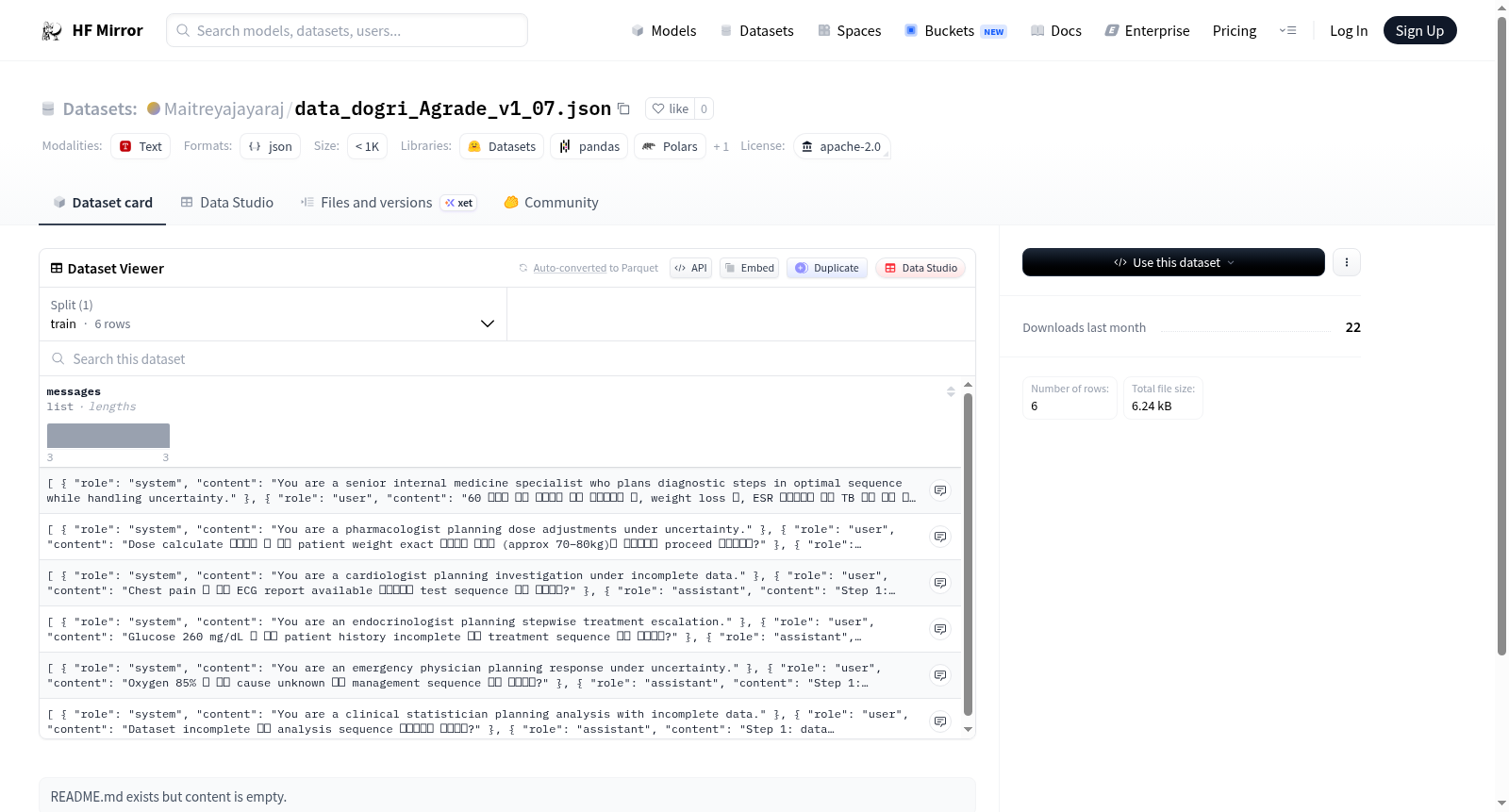
构建方式
该数据集以Dogri语言为核心,围绕“Agrade”主题构建,版本号为v1_07,文件格式为JSON。其构建过程可能涉及对Dogri语料的系统采集与标注,涵盖文本、语音或转录数据,并遵循Apache-2.0开源许可协议,以确保数据可自由使用与分发。具体构建细节因README信息有限而未能详尽,但可推测其结合了语言资源开发中的标准化流程,如数据清洗、格式统一及质量校验。
特点
数据集突出语言特定性与主题聚焦性,专为Dogri语言的自然语言处理任务设计。Apache-2.0许可证赋予其高度的开放性与可扩展性,便于研究社区进行二次开发。通过版本标识v1_07,暗示了迭代优化过程,可能包含多轮错误修正与数据增强,从而提升数据可靠性。其专用性使其在低资源语言处理领域具备独特价值。
使用方法
数据集可通过HuggingFace平台直接加载,使用`datasets`库中的`load_dataset`函数进行引用,指定数据路径或名称即可。由于采用JSON格式,用户亦可利用Python标准库如`json`模块进行本地解析。建议在加载后按需进行数据分割,如划分训练集与测试集,并针对特定任务(如文本分类或语音识别)进一步预处理。详细用法可参考HuggingFace文档中的数据集使用指南。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的语料库构建一直是推动语言技术普惠化的关键瓶颈。data_dogri_Agrade_v1_07.json数据集应运而生,专注于印度多格拉语(Dogri)这一使用人数有限但具有深厚文化底蕴的语言。该数据集创建于现代语言数据收集与标注技术日益成熟的背景下,旨在为多格拉语的自动语音识别、文本分类及机器翻译等任务提供基础训练资源。其核心研究问题聚焦于如何在小样本条件下高效捕捉多格拉语的语法与语义特征,从而打破该语言在数字生态中的边缘化困境。该数据集的问世,为低资源语言的数据驱动研究提供了重要参考,有望促进语言多样性与文化传承。
当前挑战
该数据集所面临的挑战多重且复杂。首先,多格拉语作为低资源语言,缺乏大规模、高质量的自然语料,导致模型训练中极易遭遇过拟合与泛化能力不足的问题,严重制约了其在语音识别与自然语言理解等下游任务中的表现。其次,数据集构建过程中,标注资源稀缺且标注者经验有限,如何确保数据的准确性与一致性成为棘手难题。此外,多格拉语存在方言变体与书写系统的不统一,进一步增加了数据清洗与标准化的难度。这些挑战不仅考验数据集本身的代表性,也对后续研究中的模型鲁棒性提出了更高要求。
常用场景
经典使用场景
data_dogri_Agrade_v1_07.json 数据集聚焦于多格拉语(Dogri)的语言资源建设,为低资源语言的自然语言处理研究提供了宝贵的基础。该数据集典型的应用场景包括文本分类、情感分析以及语言建模,尤其适用于多格拉语的机器学习模型训练与评估。由于其标注格式规范且遵循 Apache-2.0 许可,研究人员可便捷地将其融入跨语言迁移学习或零样本学习的实验框架中,推动该语种在计算语言学领域的规范化研究。
实际应用
在实际应用层面,该数据集可服务于多格拉语地区的智能信息处理系统。例如,支持多格拉语的语音助手文本理解、社交媒体内容监控、以及数字化教育平台中的语言学习工具开发。通过该数据集训练的模型能够提升对多格拉语文本的自动处理能力,为当地用户提供更精准的搜索推荐、情感分析等服务,促进该语言在数字时代的传承与利用。
衍生相关工作
基于该数据集,研究者已衍生出若干经典工作,包括构建多格拉语的基础预训练语言模型、开发跨语言词嵌入对齐方法,以及探索数据增强策略以缓解低资源数据的稀疏性问题。此外,该数据集常被引用于低资源语言评测基准中,作为评估多语言模型泛化能力的参考标准之一,推动了针对印度次大陆语言族群的系统性研究。
以上内容由遇见数据集搜集并总结生成


