qinchuanhui/UDA-QA
收藏Hugging Face2024-06-13 更新2024-06-25 收录
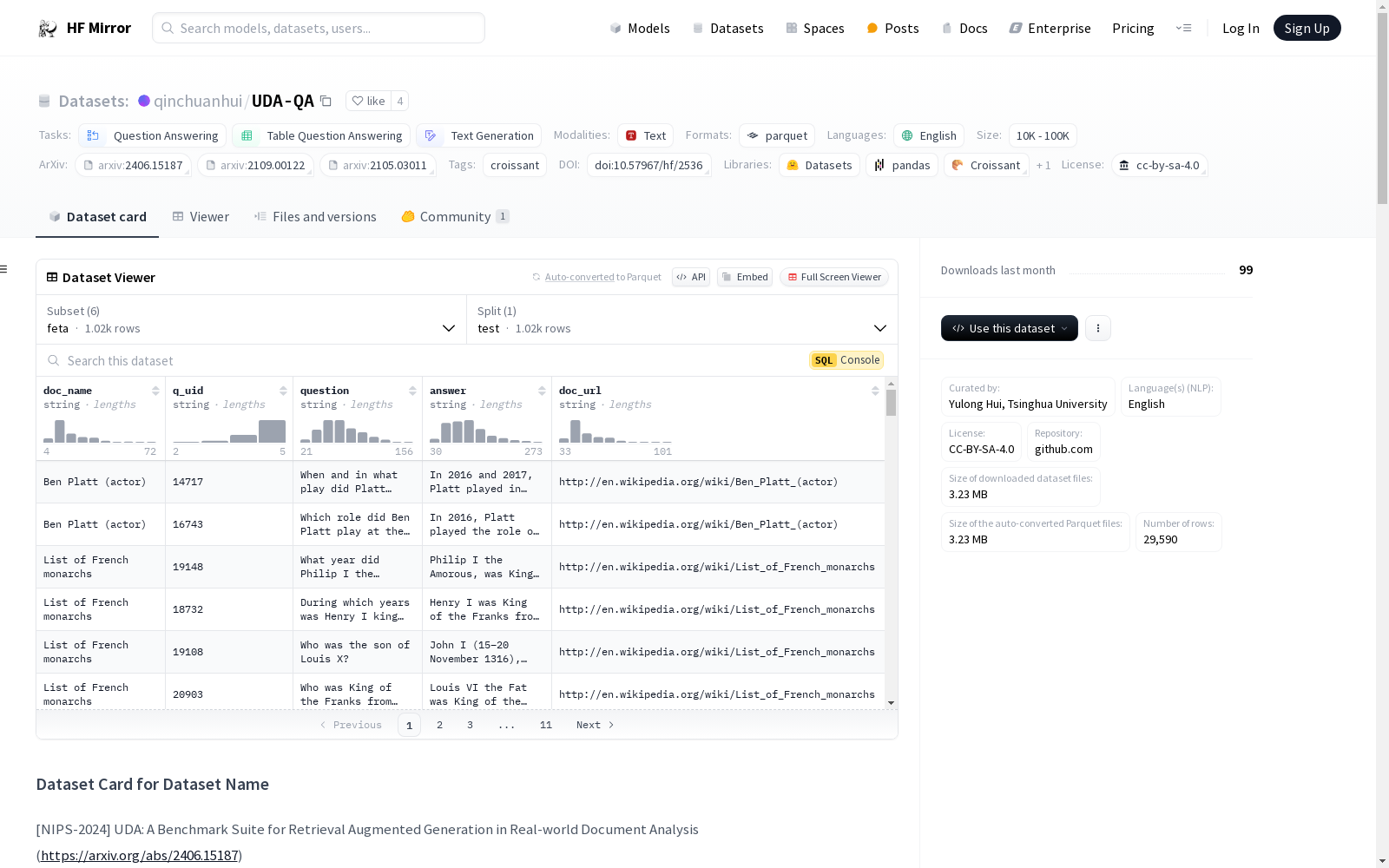
下载链接:
https://hf-mirror.com/datasets/qinchuanhui/UDA-QA
下载链接
链接失效反馈官方服务:
资源简介:
UDA(非结构化文档分析)是一个用于现实世界文档分析中检索增强生成(RAG)的基准套件。UDA数据集中的每个条目都组织为*文档-问题-答案*三元组,其中问题从文档中提出,并附有相应的真实答案。文档以其原始文件格式保留,未进行解析或分段;它们包括文本和表格数据,反映了现实世界分析场景的复杂性。
UDA (Unstructured Document Analysis) is a benchmark suite for retrieval-augmented generation (RAG) in real-world document analysis. Each entry in the UDA dataset is organized as *document-question-answer* triples, where questions are formulated from the corresponding documents and paired with their ground-truth answers. Documents are preserved in their original file formats without parsing or segmentation; they contain both textual and tabular data, reflecting the complexity of real-world document analysis scenarios.
提供机构:
qinchuanhui
原始信息汇总
数据集概述
基本信息
- 许可证: CC-BY-SA-4.0
- 任务类别:
- 问答
- 表格问答
- 文本生成
- 语言: 英语
- 标签: croissant
- 数据集名称: UDA-QA
- 数据集大小: 10K<n<100K
配置名称
- feta
- nq
- paper_text
- paper_tab
- fin
- tat
数据集详情
配置详情
feta
- 特征:
doc_name: 字符串q_uid: 字符串question: 字符串answer: 字符串doc_url: 字符串
nq
- 特征:
doc_name: 字符串q_uid: 字符串question: 字符串short_answer: 字符串long_answer: 字符串doc_url: 字符串
paper_text
- 特征:
doc_name: 字符串q_uid: 字符串question: 字符串answer_1: 字符串answer_2: 字符串answer_3: 字符串
paper_tab
- 特征:
doc_name: 字符串q_uid: 字符串question: 字符串answer_1: 字符串answer_2: 字符串answer_3: 字符串
fin
- 特征:
doc_name: 字符串q_uid: 字符串question: 字符串answer_1: 字符串answer_2: 字符串
数据文件
- feta:
split: testpath: feta/test*
- nq:
split: testpath: nq/test*
- paper_text:
split: testpath: paper_text/test*
- paper_tab:
split: testpath: paper_tab/test*
- fin:
split: testpath: fin/test*
- tat:
split: testpath: tat/test*
数据集描述
UDA (Unstructured Document Analysis) 是一个用于增强生成 (RAG) 在实际文档分析中的基准套件。每个条目都组织为一个 文档-问题-答案 三元组,其中问题从文档中提出,并附有相应的真实答案。文档保留其原始文件格式,没有解析或分割;它们包含文本和表格数据,反映了现实世界分析场景的复杂性。
数据集结构
描述性统计
| 子数据集 (folder_name) | 来源领域 | 文档格式 | 文档数量 | Q&A 数量 | 平均字数 | 平均页数 | Q&A 类型 |
|---|---|---|---|---|---|---|---|
| FinHybrid (fin) | 财务报告 | 788 | 8190 | 76.6k | 147.8 | 算术 | |
| TatHybrid (tat) | 财务报告 | 170 | 14703 | 77.5k | 148.5 | 抽取式, 计数, 算术 | |
| PaperTab (paper_tab) | 学术论文 | 307 | 393 | 6.1k | 11.0 | 抽取式, 是/否, 自由形式 | |
| PaperText (paper_text) | 学术论文 | 1087 | 2804 | 5.9k | 10.6 | 抽取式, 是/否, 自由形式 | |
| FetaTab (feta) | 维基百科 | PDF & HTML | 878 | 1023 | 6.0k | 14.9 | 自由形式 |
| NqText (nq) | 维基百科 | PDF & HTML | 645 | 2477 | 6.1k | 14.9 | 抽取式 |
数据字段
| 字段名称 | 字段值 | 描述 | 示例 |
|---|---|---|---|
| doc_name | 字符串 | 源文档名称 | 1912.01214 |
| q_uid | 字符串 | 问题的唯一ID | 9a05a5f4351db75da371f7ac12eb0b03607c4b87 |
| question | 字符串 | 提出的问题 | which datasets did they experiment with? |
| answer 或 answer_1, answer_2 或 short_answer, long_answer | 字符串 | 真实答案/答案 | Europarl, MultiUN |
附加说明: 某些子数据集可能有多个真实答案,答案组织为 answer_1, answer_2(在 FinHybrid, PaperTab 和 PaperText 中)或 short_answer, long_answer(在 NqText 中);在 TatHybrid 子数据集中,答案组织为一个序列,由于涉及多跨度 Q&A 类型。此外,某些子数据集可能有独特的数据字段。例如,doc_url 在 FetaTab 和 NqText 中描述维基百科 URL 页面,而 answer_type 和 answer_scale 在 TatHybrid 中提供扩展答案参考。
搜集汇总
数据集介绍
构建方式
UDA-QA数据集的构建基于多个公开的问答数据集,这些数据集均由人工参与者标注。构建过程中,研究人员进行了源文档的识别、分类、过滤和数据转换等关键步骤。数据集中的每个条目以“文档-问题-答案”三元组的形式组织,文档保留了原始文件格式,未进行解析或分割,涵盖了文本和表格数据,反映了现实世界文档分析的复杂性。
特点
UDA-QA数据集的特点在于其多样化的文档类型和问答形式。数据集包含来自金融报告、学术论文和维基百科的文档,涵盖了算术、抽取式、计数等多种问答类型。每个子数据集具有独特的字段结构,例如`doc_url`字段描述维基百科页面,`answer_type`和`answer_scale`字段提供扩展的答案参考。此外,部分子数据集支持多答案形式,如`answer_1`、`answer_2`或`short_answer`、`long_answer`,进一步增强了数据集的实用性。
使用方法
UDA-QA数据集主要用于问答任务,特别是针对非结构化文档的问答。使用前需从`src_doc_files`文件夹下载源文档文件。数据集还可用于评估检索策略的有效性,以及直接评估大语言模型在数值推理和表格推理任务中的表现。通过`extended_qa_info`文件夹中的证据,用户可进一步解析非结构化PDF文档,探索更复杂的文档分析场景。
背景与挑战
背景概述
UDA-QA数据集由清华大学的研究人员Yulong Hui等人于2024年创建,旨在为真实世界文档分析中的检索增强生成(RAG)提供一个基准测试套件。该数据集以文档-问题-答案三元组的形式组织,涵盖了从学术论文到财务报告等多种文档类型,反映了现实世界中复杂的数据分析场景。UDA-QA的创建不仅推动了自然语言处理领域在文档理解方面的研究,还为评估大型语言模型在数值推理和表格推理中的表现提供了重要工具。
当前挑战
UDA-QA数据集在构建过程中面临多重挑战。首先,文档的多样性和复杂性使得数据收集和标注变得极为困难,尤其是财务报告和学术论文等非结构化文档的处理。其次,数据集中包含多种问答类型,如提取式、算术式和自由式问答,这对模型的泛化能力提出了更高要求。此外,文档的原始格式保留增加了数据处理的复杂性,尤其是在多模态数据(如文本和表格)的融合方面。这些挑战不仅考验了数据集的构建技术,也为后续研究提供了丰富的探索空间。
常用场景
经典使用场景
UDA-QA数据集在自然语言处理领域中被广泛应用于问答系统的开发和评估。该数据集通过提供文档-问题-答案三元组,支持对非结构化文档的深度分析,尤其是在金融报告和学术论文等复杂文本中的应用。研究人员可以利用该数据集训练和测试模型,以提高模型在真实世界文档中的问答准确性和理解能力。
解决学术问题
UDA-QA数据集解决了在非结构化文档中进行问答任务时面临的多个学术挑战。通过提供多样化的文档类型和复杂的问题形式,该数据集帮助研究人员评估和提升模型在数值推理、表格推理和多跨度问答等任务中的表现。此外,该数据集还为检索增强生成(RAG)技术提供了基准,推动了文档理解领域的研究进展。
衍生相关工作
UDA-QA数据集衍生了许多相关研究工作,特别是在检索增强生成(RAG)和文档理解领域。基于该数据集,研究人员开发了多种先进的问答模型,如基于深度学习的多模态模型和基于检索的生成模型。这些模型不仅在UDA-QA数据集上取得了显著的性能提升,还被广泛应用于其他文档问答任务中,推动了自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


