audiobooks
收藏Hugging Face2025-05-13 更新2025-05-14 收录
下载链接:
https://huggingface.co/datasets/yasalma/audiobooks
下载链接
链接失效反馈官方服务:
资源简介:
Tatar Audiobooks是一个包含塔塔尔语的有声书数据集,适用于文本到语音、自动语音识别和音频到音频等任务。数据集共有170个小时的对齐有声书,来自tatkniga.ru网站,共有20位说话者参与,其中4位说话者贡献了17+小时音频。所有书籍均可免费访问,大部分属于公共领域。
Tatar Audiobooks is a Tatar-language audiobook dataset designed for tasks including text-to-speech, automatic speech recognition, and audio-to-audio processing. The dataset contains 170 hours of aligned audiobook content, sourced from the tatkniga.ru website, with contributions from 20 speakers, four of whom have contributed over 17 hours of audio. All included books are freely accessible, and most of them are in the public domain.
创建时间:
2025-05-05
原始信息汇总
数据集概述
基本信息
- 数据集名称: Tatar Audiobooks
- 数据集地址: https://huggingface.co/datasets/yasalma/audiobooks
- 语言: 鞑靼语 (tt)
- 许可证: CC-BY-4.0
- 数据规模: 1K<n<10K
数据集内容
- 数据类型: 音频和文本
- 特征:
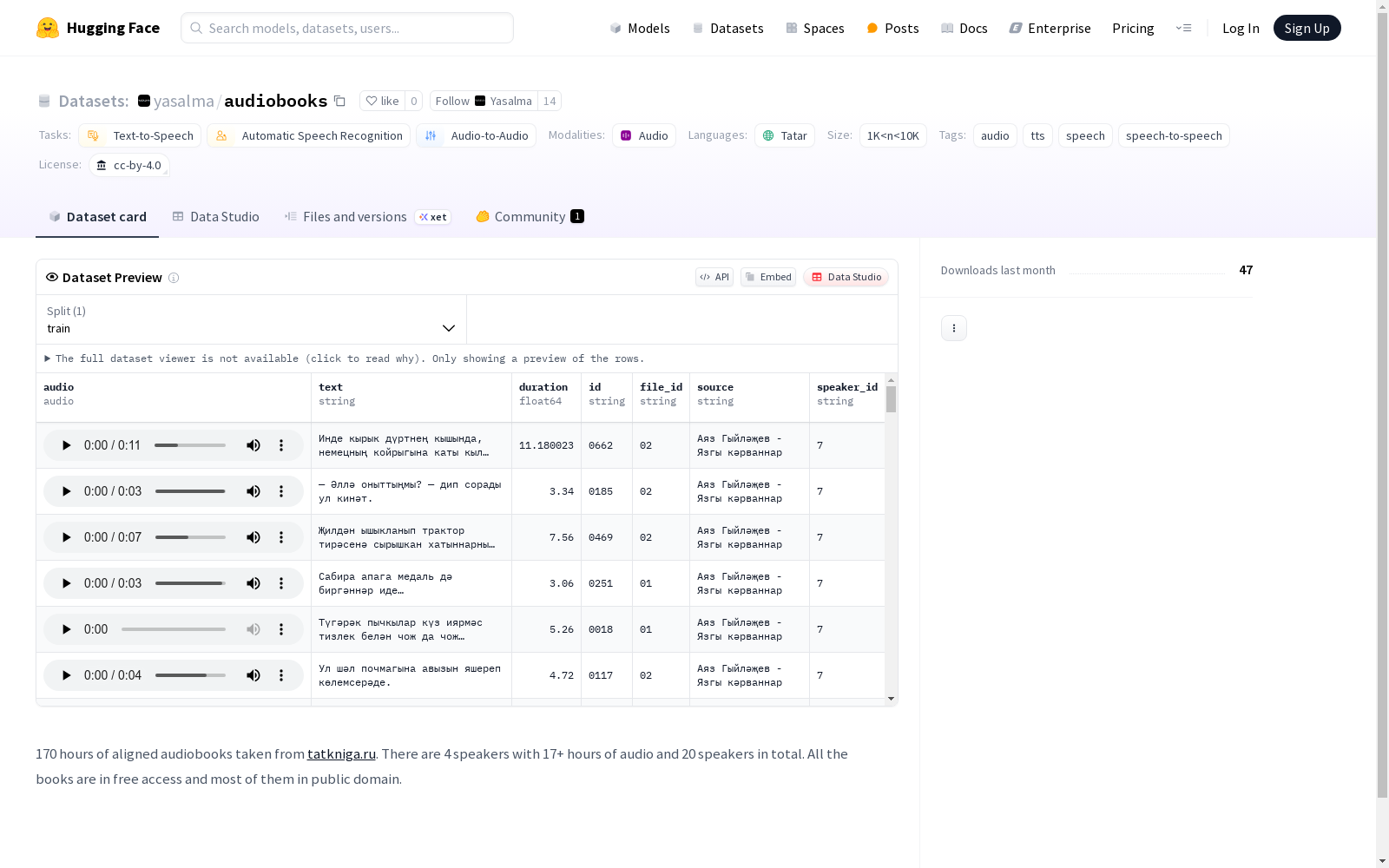
audio: 音频数据text: 文本数据duration: 音频时长 (float64)id: 唯一标识符 (string)file_id: 文件标识符 (string)source: 数据来源 (string)speaker_id: 说话者标识符 (string)
- 数据来源: tatkniga.ru
数据集结构
- 配置名称: audiobooks
- 数据文件:
train: 训练集 (路径: /train.parquet)
数据集描述
- 总时长: 170小时
- 说话者数量: 20人 (其中4人每人有17+小时的音频)
- 内容: 来自公开访问的鞑靼语有声读物,大多数属于公共领域
任务类别
- 文本到语音 (Text-to-Speech)
- 自动语音识别 (Automatic Speech Recognition)
- 音频到音频 (Audio-to-Audio)
标签
- audio
- tts
- speech
- speech-to-speech
搜集汇总
数据集介绍
构建方式
该数据集源自公开资源平台tatkniga.ru,通过系统化采集鞑靼语有声读物构建而成。研究人员采用专业音频对齐技术,将170小时语音内容与对应文本精确匹配,涵盖20位朗读者样本,其中4位核心朗读者每人贡献超过17小时素材。数据以标准化parquet格式存储,包含音频波形、文本转录、时长等结构化字段,所有素材均符合知识共享许可协议要求。
使用方法
研究者可通过HuggingFace数据集接口直接加载parquet格式数据流,音频特征提取建议采用Librosa或Torchaudio工具包。针对文本到语音任务,建议以说话人ID为分组依据划分训练验证集;语音识别任务则需注意方言变体的标注处理。实验环境中推荐使用16kHz采样率保持数据一致性,对于计算资源受限的情况,可利用duration字段进行时长筛选以构建子集。
背景与挑战
背景概述
Tatar Audiobooks数据集由tatkniga.ru平台公开的鞑靼语有声读物构建而成,专注于低资源语言的语音与文本处理研究。该数据集收录了总计170小时的语音文本对齐数据,涵盖20位发音人的朗读内容,其中4位发音人提供了超过17小时的语音样本。作为面向自动语音识别(ASR)和文本转语音(TTS)任务的多模态语料库,其以CC-BY-4.0协议开放的特性,为鞑靼语这一突厥语族语言的数字资源建设提供了重要基础。数据集内嵌的发音人多样性及公版图书的文本来源,对保护语言文化遗产和开发包容性语音技术具有显著价值。
当前挑战
构建鞑靼语有声读物数据集面临双重挑战:在领域问题层面,低资源语言的语音数据稀缺导致发音人招募困难,且突厥语族的黏着语特性对语音识别模型的形态学处理能力提出特殊要求;在技术实现层面,原始音频与文本的精确对齐需要克服书籍版本差异带来的文本偏移问题,同时需平衡不同发音人的录音质量与方言变体。多说话人场景下的语音一致性保持,以及公版书籍中古旧词汇与现代语音系统的映射,均为数据清洗与标注过程中的实质性障碍。
常用场景
经典使用场景
在语音合成与识别领域,Tatar Audiobooks数据集凭借其170小时的高质量对齐音频文本数据,成为研究鞑靼语语音特性的重要资源。该数据集最典型的应用场景包括训练端到端的文本转语音系统,其中4位主要发音人超过17小时的录音为构建个性化声学模型提供了充足素材。音频与文本的精确对齐特性,使其特别适合用于研究音素时长预测、韵律建模等语音合成关键技术。
解决学术问题
该数据集有效解决了低资源语言语音技术研究中的数据匮乏问题。针对鞑靼语这类突厥语系语言,学术界长期缺乏标准化的语音语料库,阻碍了语音识别准确率提升和合成自然度改进的研究。通过提供多发音人、跨文本类型的语音样本,研究者能够深入探究黏着语的音系特征,开发适应复杂形态学的语音处理算法,填补了该语言在计算语言学领域的空白。
实际应用
在实际应用层面,该数据集支撑的语音技术可服务于鞑靼语地区的智能语音助手开发。教育领域可基于此构建有声读物自动生成系统,促进少数民族语言文化的数字化传承。医疗辅助场景中,语音识别模块能帮助构建鞑靼语诊疗语音录入系统。多发音人数据特性尤其适合开发面向视障人士的个性化语音导航应用。
数据集最近研究
最新研究方向
在语音技术领域,Tatar语种资源的稀缺性使得该数据集成为低资源语音处理研究的重要素材。当前研究聚焦于跨语言语音合成与识别模型的迁移学习,通过该数据集的4名主要发音人长达17小时的优质对齐数据,探索小样本条件下的声学建模优化方案。随着多模态交互技术的兴起,该数据集在语音克隆和语音风格转换任务中展现出独特价值,特别是其包含的20名发音人数据为说话人特征解耦研究提供了实验基础。近期研究进一步挖掘其在语音翻译系统中的潜力,结合文本与音频的对齐特性,推动端到端语音到语音转换技术在少数民族语言中的落地应用。
以上内容由遇见数据集搜集并总结生成


