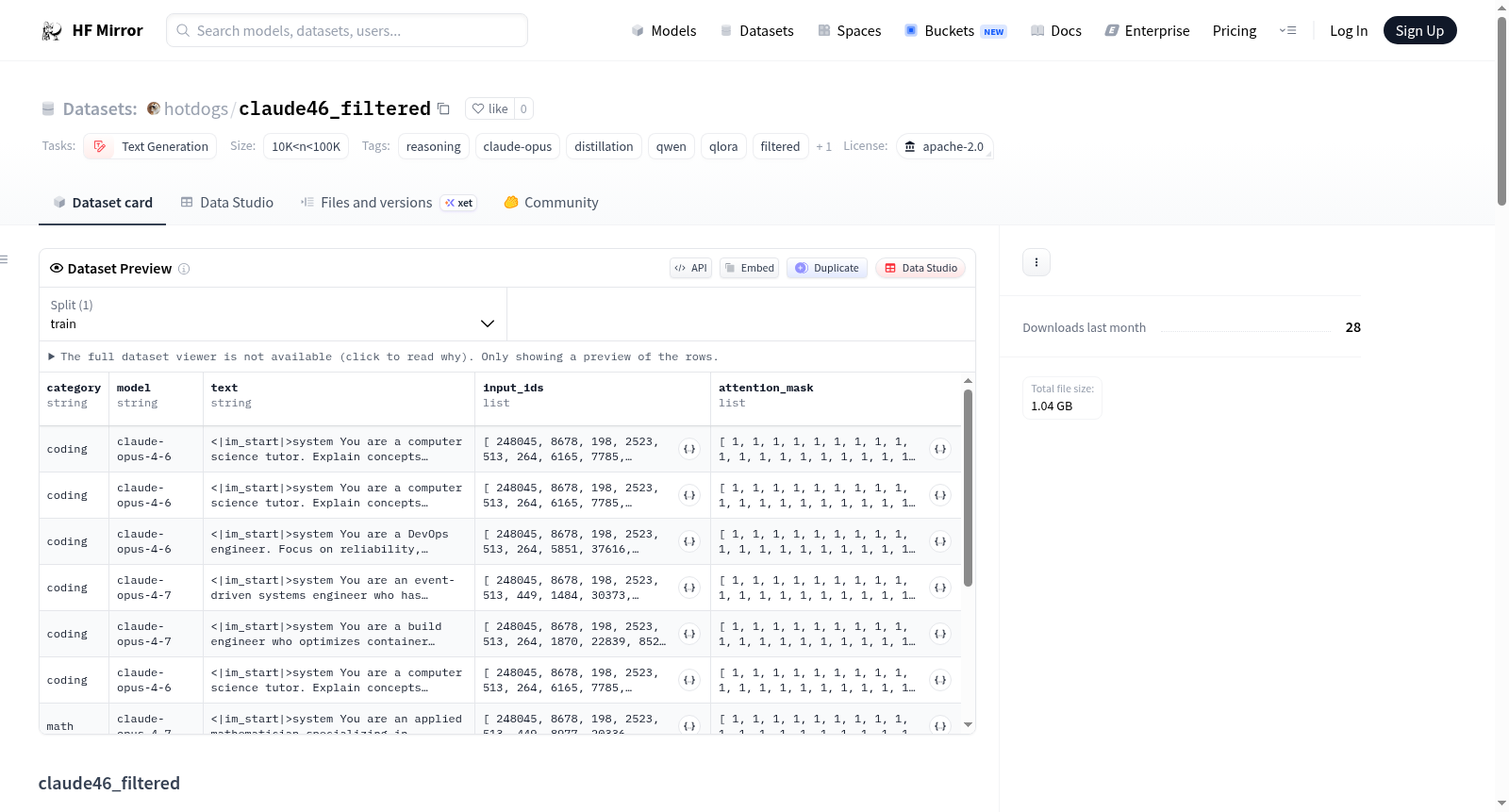
hotdogs/claude46_filtered
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/hotdogs/claude46_filtered
下载链接
链接失效反馈官方服务:
资源简介:
claude46_filtered数据集是从angrygiraffe/claude-opus-4.6-4.7-reasoning-8.7k过滤而来的子集,移除了26%的拒绝回答样本,保留了28,576个干净的推理链样本。这些样本主要来自Claude Opus 4.6和4.7的推理能力蒸馏,涵盖了编码、数学、科学、哲学、创意写作等多个类别。数据集格式为包含角色和内容的对话消息,用于训练基于Qwen3.6-27B变体的无审查推理模型。过滤过程通过识别特定的拒绝模式(如I cannot、as an AI等)来移除不符合要求的样本,确保模型训练时不重新引入拒绝行为。
The claude46_filtered dataset is a filtered subset of angrygiraffe/claude-opus-4.6-4.7-reasoning-8.7k with 9,928 refusals removed, leaving 28,576 clean reasoning examples. These examples are primarily distilled from the reasoning capabilities of Claude Opus 4.6 and 4.7, covering categories such as coding, math, science, philosophy, creative writing, and more. The dataset format consists of messages with roles and content, intended for training uncensored reasoning models based on a variant of Qwen3.6-27B. The filtering process identified and removed refusal patterns (e.g., I cannot, as an AI, etc.) to prevent reintroducing refusal behavior during model training.
提供机构:
hotdogs
搜集汇总
数据集介绍
构建方式
claude46_filtered数据集源自angrygiraffe/claude-opus-4.6-4.7-reasoning-8.7k,经过智能过滤代理UKA的精心筛选与去劣处理。原始数据集包含38,504条来自Claude Opus 4.6和4.7的推理链,覆盖编程、数学、科学、哲学及创意写作等多个领域。为确保训练无审查推理模型的质量,过滤过程通过扫描助手的回答内容,识别并剔除了包含“I cannot”、“as an AI”、“I apologize”等9种拒绝模式的样本,共计移除9,928条(占比26%),最终保留28,576条纯净的推理示例,以统一的消息格式(角色+内容)存储,磁盘占用约996 MB。
特点
该数据集的核心特点在于其专注于无审查推理能力的构建,尤其针对基于abliterated Qwen3.6-27B基座模型的LoRA微调需求。所有样本均为高质量、无拒绝行为的推理链,有效避免了训练数据中残留的回避倾向反向引入基座模型,确保微调后的模型在推理过程中保持零拒绝率。数据涵盖广泛的知识类别,从严谨的编码和数学问题到开放的哲学和创意写作,兼具多样性与深度。此外,数据集格式简洁标准,每条记录包含类别标签、来源模型及多轮对话消息,便于直接用于监督式微调或指令遵循任务。
使用方法
使用者可通过HuggingFace Datasets库便捷加载该数据集,推荐采用load_dataset函数从远程仓库读取,指定split参数为'train'即可获取全部28,576条样本;也可先下载至本地后使用load_from_disk方法加载。数据集以标准消息格式组织,每条记录包含system、user和assistant三轮对话,适配主流的对话模型训练框架。适用于基于QLoRA的高效微调实验,建议在有效批量大小为4的条件下运行约7,144步,遍历整个数据集一个周期,以训练出具备强大推理能力且无审查倾向的Qwen3.6-27B模型变体。
背景与挑战
背景概述
claude46_filtered数据集由UKA团队于近期创建,旨在为大语言模型的无审查推理能力训练提供高质量的蒸馏数据。该数据集源自angrygiraffe收集的Claude Opus 4.6与4.7版本的推理链,原始规模达38,504条样本,涵盖编程、数学、科学、哲学及创意写作等多个领域。核心研究问题聚焦于如何通过知识蒸馏与数据清洗,从顶级闭源模型中提取纯净的推理能力,进而应用于开源模型(如abliterated Qwen3.6-27B)的微调。数据集的发布为开发高性能且无安全限制的推理模型提供了关键资源,对开源社区中模型透明性与可控性的探索具有重要推动作用。
当前挑战
该数据集所解决的领域挑战在于:主流大语言模型普遍内嵌安全对齐机制,导致其在处理敏感话题时产生拒绝回答行为,严重限制了模型在科学研究、创意表达等场景下的实用性与开放性。构建过程中面临的核心困难包括:1) 从Claude Opus的38,504条原始推理链中精准识别并移除9,928条(占比26%)包含拒绝模式的样本,需设计高效的过滤规则以避免误删有效内容;2) 确保清洗后的28,576条样本保持推理链的完整性、连贯性与多样性,防止因过度过滤导致模型能力退化;3) 适配已进行abliteration处理的基座模型,避免训练数据中残留的拒绝模式重新激活模型的安全限制,从而破坏无审查设计的初衷。
常用场景
经典使用场景
在大型语言模型的对齐与推理能力增强研究中,claude46_filtered数据集被经典地用于训练无审查(uncensored)的推理模型。该数据集源自Claude Opus 4.6和4.7的推理链,通过系统性过滤移除约26%的拒绝回答样本,为基于abliterated Qwen3.6-27B的LoRA微调提供了纯净的思维链语料。研究人员利用其28,576条涵盖编程、数学、科学、哲学等领域的消息格式数据,引导模型生成自由且复杂的推理过程,从而提升模型的思维透明度和问题解决能力。
衍生相关工作
claude46_filtered数据集的衍生工作主要围绕无审查推理模型的构建与优化。最具代表性的是基于abliterated Qwen3.6-27B的LoRA适配器训练,该工作利用过滤后的思维链数据实现了0%拒绝率的推理模型。此外,UKA代理(Hermes Agent)的自动筛选流程本身也成为后续研究参考的范例,推动了基于规则模式的拒绝样本识别方法。这些工作共同探索了如何平衡模型的安全约束与推理自由,为开源社区在规约移除(abliteration)和抗审查微调领域奠定了实践基础。
数据集最近研究
最新研究方向
该数据集聚焦于从大型语言模型推理链中剔除拒答行为,服务于无审查推理模型的微调与知识蒸馏。通过滤除Claude Opus 4.6/4.7生成数据中约26%的拒绝回答样本,保留28,576条涵盖编程、数学、科学等领域的纯净推理链,并结合abliterated版本的Qwen3.6-27B作为基座,以QLoRA方式训练零拒答率的推理模型。这一方向回应了当前开源社区对“无审查”与“强推理”能力融合的迫切需求,代表了从直接模型对齐转向后端数据净化与基座改造并行的前沿技术路线,尤其在高风险问答与创意生成场景中具有突破性意义。
以上内容由遇见数据集搜集并总结生成


