err-video-news-transcribed
收藏Hugging Face2026-03-31 更新2026-04-01 收录
下载链接:
https://huggingface.co/datasets/TalTechNLP/err-video-news-transcribed
下载链接
链接失效反馈官方服务:
资源简介:
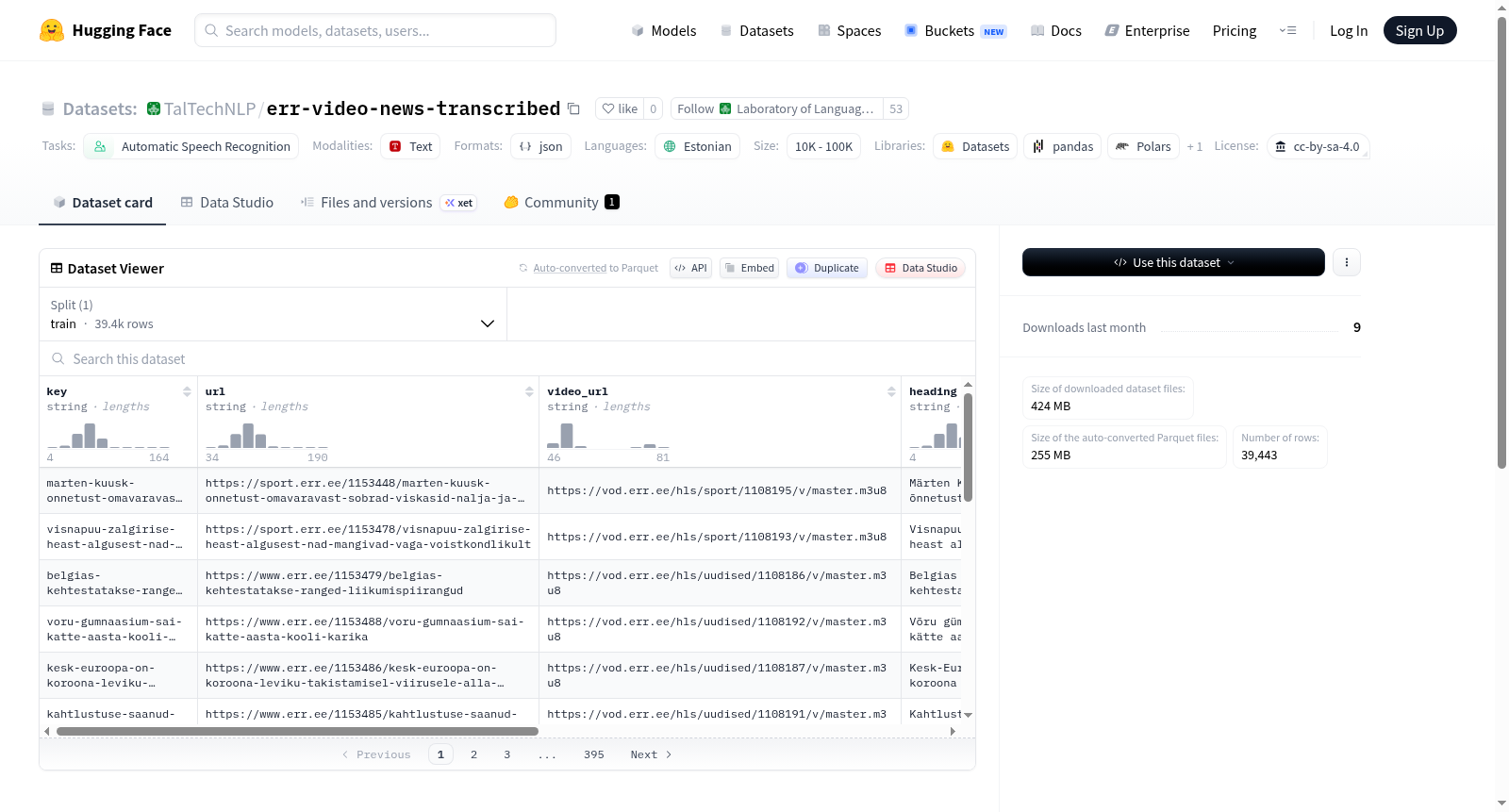
Transcribed ERR Video News Dataset 是一个包含爱沙尼亚国家广播公司(ERR)视频新闻故事转录文本的数据集。该数据集包含约40,000个新闻故事,总时长约4000小时。转录文本是通过自动语音识别技术(gemini-3-flash-preview)生成的,并使用了上下文偏置技术以提高识别质量,平均词错误率(WER)约为5%。数据集经过严格过滤,仅保留视频中主要为爱沙尼亚语的故事,排除了大量非爱沙尼亚语或音乐的内容。每个新闻故事提供标题、导语文本、新闻正文以及视频新闻故事的转录文本。为避免版权问题,数据集中不包含音频或视频数据,但提供了每个故事原始视频的网页链接。该数据集适用于自动语音识别(ASR)任务及其他与爱沙尼亚语相关的自然语言处理研究。
提供机构:
Laboratory of Language Technology at Tallinn University of Technology
创建时间:
2026-03-30
原始信息汇总
Transcribed ERR Video News Dataset 概述
数据集基本信息
- 许可证:cc-by-sa-4.0
- 任务类别:自动语音识别
- 语言:爱沙尼亚语 (et)
数据来源与内容
- 数据来源于爱沙尼亚国家广播公司 (https://www.err.ee/) 的视频新闻报道。
- 包含约 40,000 个新闻故事,总时长约 4000 小时。
- 转录文本通过语音识别系统 (gemini-3-flash-preview) 自动生成,并使用了基于同主题文本新闻故事的上下文偏置技术以提高自动语音识别质量。
- 转录的平均词错误率约为 5%。
- 数据集经过严格过滤,仅保留视频内容主要为爱沙尼亚语语音的新闻故事,已移除包含大量非爱沙尼亚语语音和/或音乐的新闻片段。
数据字段说明
每个新闻故事提供以下信息:
- 标题 (heading)
- 导语文本 (leadin text)
- 文本新闻故事正文 (main body of the textual news story)
- 视频新闻故事转录文本 (transcript of the video news story)
- 字幕 (subtitles):内容与“转录”字段相同,但以 VTT 格式分段,每个字幕块代表一个句子。句子/字幕的开始和结束时间通过强制对齐获得。
数据使用说明
- 为避免版权问题,数据集中不包含音频/视频数据。
- 为每个故事提供了可爬取原始视频的网页链接。
- 如需下载音频帮助,请联系 tanel.alumae@taltech.ee。
搜集汇总
数据集介绍
构建方式
在爱沙尼亚语语音识别研究领域,数据集的构建往往依赖于大规模的真实媒体语料。本数据集以爱沙尼亚国家广播公司的视频新闻报道为原始素材,通过自动化流程进行转录。具体而言,研究者首先从官方网站采集了约四万条新闻故事,对应总时长约四千小时。随后运用先进的语音识别模型进行自动转写,并创新性地结合了对应文本新闻的上下文信息进行偏置处理,以提升识别准确率。转录完成后,数据集经过了严格过滤,剔除了包含大量非爱沙尼亚语对话或背景音乐的片段,确保了语料的语言纯净度与适用性。
使用方法
本数据集主要服务于自动语音识别及相关自然语言处理任务的研究与开发。使用者可将其直接用于爱沙尼亚语语音识别模型的训练与评估,其低词错误率的转录文本可作为高质量的监督信号。数据集中的多文本字段(标题、导语、正文、转录文本)为研究跨模态理解、新闻摘要生成或文本增强提供了丰富的素材。VTT格式的字幕及其时间戳信息,特别适用于需要精细时间对齐的研究,如语音合成、视频内容分析或字幕生成。研究人员可根据提供的网页链接获取原始音视频,以构建完整的音-文配对数据,从而拓展其在端到端语音处理等更广泛领域的应用。
背景与挑战
背景概述
随着自动语音识别技术的快速发展,多语言语音数据的稀缺性成为制约模型性能提升的关键瓶颈。在此背景下,爱沙尼亚国家广播公司(ERR)的视频新闻转录数据集应运而生,由塔尔图大学的研究团队主导构建,旨在为爱沙尼亚语语音识别研究提供大规模、高质量的标注资源。该数据集收录了约四万条新闻视频的自动转录文本,总时长接近四千小时,核心研究问题聚焦于如何利用上下文偏置技术提升低资源语言的识别准确率,其发布显著推动了波罗的海区域语言的信息处理研究,为跨媒体内容分析奠定了数据基础。
当前挑战
该数据集致力于解决爱沙尼亚语自动语音识别中的低资源语言建模挑战,其核心难题在于如何在语音信号混杂音乐或非爱沙尼亚语片段时保持转录的纯净度与准确性。构建过程中,研究团队面临双重考验:一方面需通过智能过滤机制剔除含大量非目标语言或背景噪音的视频片段,确保数据集的语音质量;另一方面,在未直接包含音视频文件以规避版权风险的约束下,如何通过提供原始视频链接维持数据可复现性,成为工程实施中的显著障碍。
常用场景
经典使用场景
在自动语音识别领域,该数据集为爱沙尼亚语语音处理研究提供了宝贵的资源。其核心应用场景在于训练和评估端到端语音识别模型,特别是针对新闻广播这类正式、清晰的口语风格。研究者可利用其大规模转录文本与视频新闻的对应关系,开发更精准的声学与语言模型,优化在特定领域词汇和语境下的识别性能。
解决学术问题
该数据集有效解决了低资源语言语音识别研究中数据稀缺的瓶颈问题。通过提供约4000小时的高质量自动转录文本,它支持了爱沙尼亚语语音识别基准的建立,促进了跨语言模型迁移学习、领域自适应以及上下文偏置技术的研究。其约5%的词错误率标注为模型性能评估提供了可靠依据,推动了语音识别鲁棒性与准确性的学术探索。
实际应用
在实际应用中,该数据集支撑了爱沙尼亚语媒体内容的智能化处理。基于其转录文本,可开发自动字幕生成系统,提升新闻视频的可访问性,服务于听障群体。同时,它也为媒体机构的新闻内容索引、归档和语义检索提供了数据基础,助力构建高效的音视频内容管理系统,促进信息传播的自动化与智能化。
数据集最近研究
最新研究方向
在自动语音识别领域,基于爱沙尼亚语广播新闻的转录数据集正推动多模态与低资源语言处理的前沿探索。研究者利用该数据集,结合上下文偏置技术提升ASR准确性,将词错误率控制在约5%,显著优化了新闻视频的实时字幕生成与跨语言检索应用。当前热点集中于利用强制对齐方法实现精细化的时间戳标注,以支持音视频内容的结构化分析与可访问性增强,同时规避版权限制通过链接原始数据源促进开放研究。这一进展不仅强化了低资源语言在数字媒体中的技术包容性,也为多语言新闻档案的智能处理奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


