indonlp/NusaX-senti
收藏Hugging Face2023-01-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/indonlp/NusaX-senti
下载链接
链接失效反馈官方服务:
资源简介:
NusaX-senti是一个高质量的多语言平行语料库,涵盖12种语言,包括印尼语、英语和10种印尼本地语言(如亚齐语、巴厘语、班贾尔语、布吉语、马都拉语、米南加保语、爪哇语、恩加朱语、巽他语和托巴巴塔克语)。该数据集用于三标签(正面、中性、负面)情感分析,支持印尼本地语言、印尼语和英语。数据集由专家生成,通过人工翻译和注释,确保了数据的高质量和平衡性。
NusaX-senti is a high-quality multilingual parallel corpus covering 12 languages, including Indonesian, English, and 10 local Indonesian languages such as Acehnese, Balinese, Banjar, Buginese, Madurese, Minangkabau, Javanese, Ngaju, Sundanese, and Toba Batak. This dataset is designed for three-label (positive, neutral, negative) sentiment analysis tasks, and supports processing across local Indonesian languages, Indonesian, and English. It was compiled by experts via manual translation and annotation, ensuring high data quality and balanced sample distribution.
提供机构:
indonlp
原始信息汇总
数据集概述
数据集名称
- 名称: NusaX-Senti
数据集内容
- 类型: 情感分析数据集
- 语言: 多语言,包括Acehnese, Balinese, Banjarese, Buginese, English, Indonesian, Javanese, Madurese, Minangkabau, Ngaju, Sundanese, Toba Batak
- 标签: 3个情感标签(positive, neutral, negative)
数据集特征
- id: 字符串类型
- text: 字符串类型
- lang: 字符串类型
- label: 分类标签,包括negative, neutral, positive
数据集创建
- 来源: 原始数据,由专家翻译
- 注释过程: 从SmSA数据集筛选,移除不当语言和个人信息,通过分层抽样选择样本并翻译
- 注释者: 印尼语及其对应语言的母语者
数据集使用许可
- 许可: CC-BY-SA-4.0
数据集引用信息
@misc{winata2022nusax, title={NusaX: Multilingual Parallel Sentiment Dataset for 10 Indonesian Local Languages}, author={Winata, Genta Indra and Aji, Alham Fikri and Cahyawijaya, Samuel and Mahendra, Rahmad and Koto, Fajri and Romadhony, Ade and Kurniawan, Kemal and Moeljadi, David and Prasojo, Radityo Eko and Fung, Pascale and Baldwin, Timothy and Lau, Jey Han and Sennrich, Rico and Ruder, Sebastian}, year={2022}, eprint={2205.15960}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
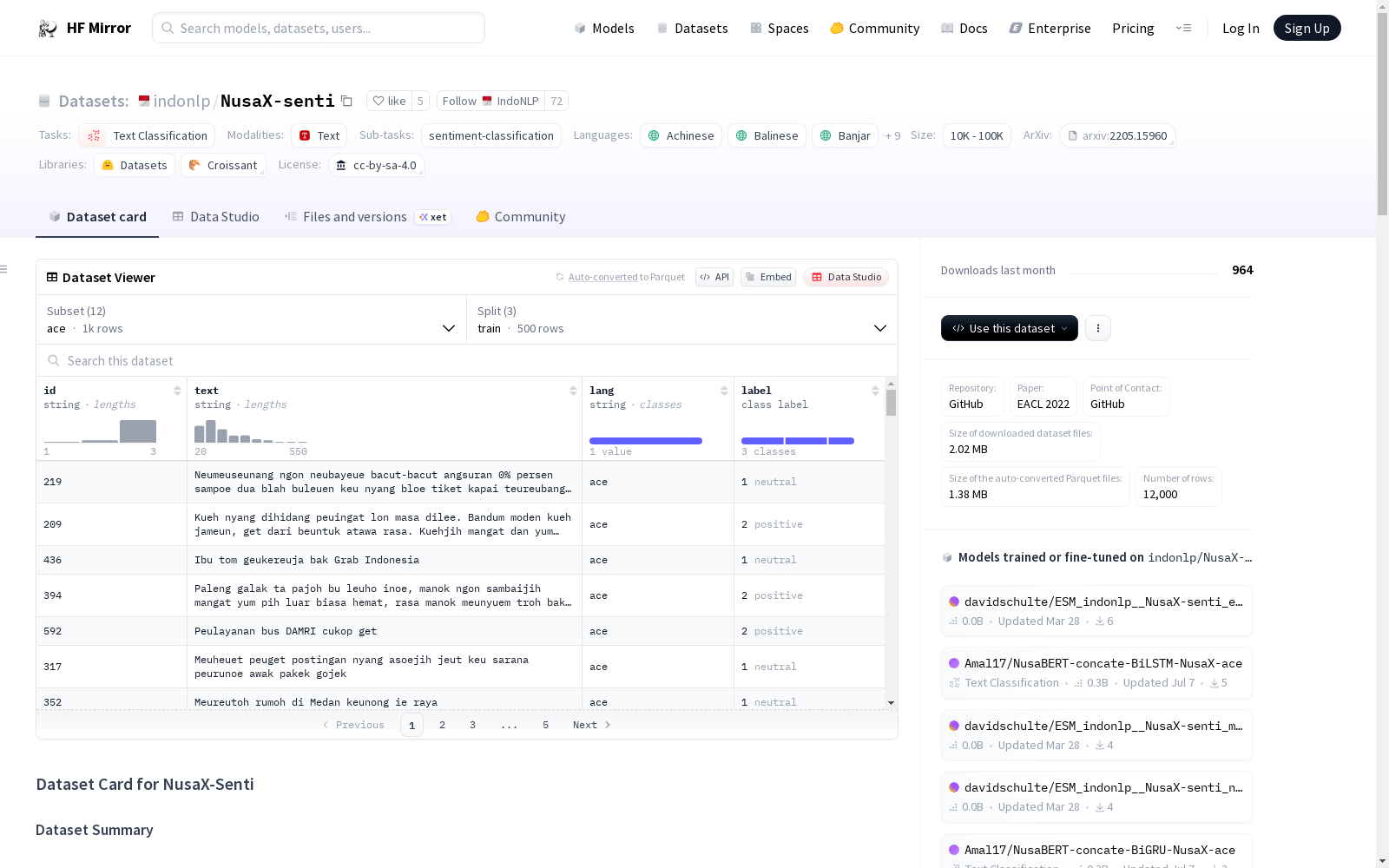
构建方式
NusaX-senti数据集的构建基于对现有最大公开印尼语情感分析数据集SmSA的深入处理。由专家生成的注释,通过 native speakers 对评论和审查进行人工翻译,并经过去个性化信息和平衡标签分布的严格筛选,确保了数据集的高质量和代表性。
使用方法
用户可以通过HuggingFace的datasets库直接加载NusaX-senti数据集。在使用前,需确保遵守CC-BY-SA 4.0许可协议,并在合理的方式下给予适当的归属。该数据集适用于文本分类任务,特别是情感分析领域,可用于模型训练、评估和基准测试。
背景与挑战
背景概述
NusaX-senti数据集,作为一项高质量的多语种平行语料库的分支,旨在解决印度尼西亚众多语言中自然语言处理资源匮乏的问题。该数据集由印度尼西亚和英语,以及10种印度尼西亚本地语言组成,覆盖了阿切恩语、巴厘语、班加里语、布吉语、马达语、米南卡保语、爪哇语、恩加朱语、巽他语和托巴巴塔克语。该数据集的创建始于对印尼语系中未充分代表语言的支持需求,由Winata等人于2022年提出,并在EACL 2022上发表相关论文。NusaX-senti数据集为三标签(积极、中性、消极)的情感分析任务提供了基础资源,对促进相关领域的研究具有重要影响力。
当前挑战
该数据集在构建过程中遇到的挑战包括:首先,由于缺乏足够的本地语言资源,数据收集和标注的质量控制尤为关键;其次,确保数据集中标签分布的平衡性,通过分层抽样方法选取样本并进行翻译;最后,数据集在处理个人和敏感信息时,必须进行严格脱敏。在所解决的领域问题方面,NusaX-senti数据集面临的挑战包括本地语言的情感分析准确性,以及如何减少数据源可能存在的偏见对模型性能的影响。
常用场景
经典使用场景
在自然语言处理领域,尤其是在情感分析任务中,NusaX-senti数据集因其覆盖了多种印尼地方语言及英语而被视为宝贵的资源。其经典的运用场景在于构建和训练多语言情感分析模型,能够理解和判别不同语种文本中的积极、中立或消极情绪,进而提升跨语言情感分析的准确性和泛化能力。
解决学术问题
NusaX-senti数据集解决了学术研究中对于印尼语及地方语言情感分析资源稀缺的问题,为研究提供了高质量的多语言平行语料,有助于促进对这些语言的情感分析算法的开发与评估,对缩小语言资源差距具有重要意义。
实际应用
在实际应用中,NusaX-senti数据集可用于社交媒体监控、市场分析以及客户情感分析等领域,帮助企业和组织理解不同语言用户的态度和偏好,从而做出更为精准的市场策略和决策。
数据集最近研究
最新研究方向
NusaX-senti数据集针对印度尼西亚地区十种本地语言及印度尼西亚语、英语构建了情感分析的三分类(积极、中立、消极)资源,其旨在解决该地区语言在自然语言处理领域资源稀缺的问题。近期研究利用该数据集,深入探讨了跨语言情感分析的模型性能,特别是在低资源语言环境下模型的泛化能力,及其在社会、文化和语言多样性背景下的应用影响。这些研究不仅推动了印度尼西亚本地语言处理技术的发展,也为理解不同语言间情感表达的差异提供了新的视角,具有重要的社会和学术意义。
以上内容由遇见数据集搜集并总结生成


