talking-to-chatbots-unwrapped-chats
收藏Hugging Face2024-12-23 更新2024-12-24 收录
下载链接:
https://huggingface.co/datasets/reddgr/talking-to-chatbots-unwrapped-chats
下载链接
链接失效反馈官方服务:
资源简介:
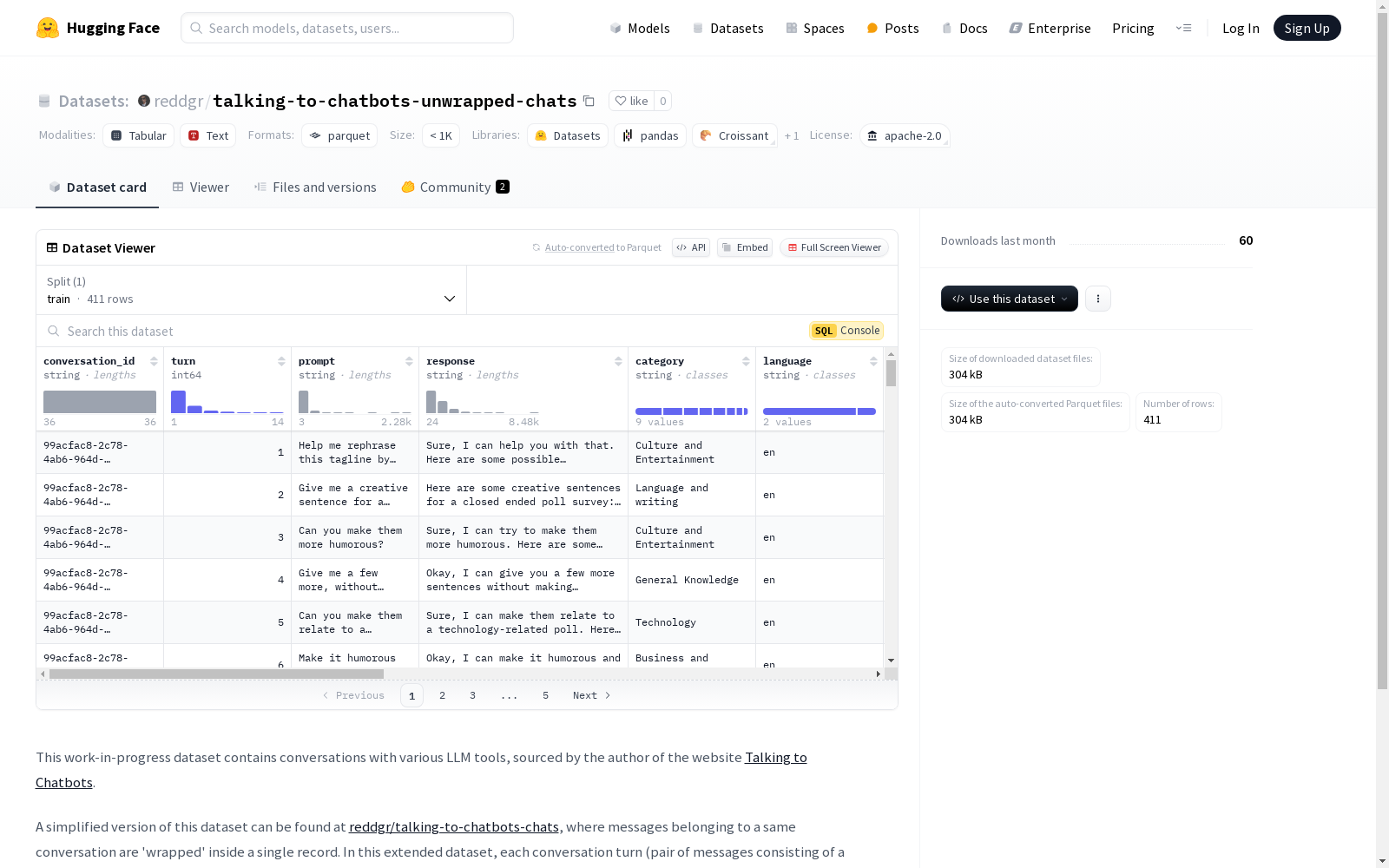
该数据集包含与各种LLM工具的对话,数据来源于作者的网站'Talking to Chatbots'。每个对话轮次(由用户提示和LLM响应组成的消息对)都作为单独的记录呈现,并附有通过'reddgr'系列模型计算的额外指标和分类标签。此外,还提供了一个简化版本的数据集,其中属于同一对话的消息被包装在一个记录中。
This dataset contains conversations with various LLM tools, sourced from the author's website 'Talking to Chatbots'. Each conversation turn, which is a message pair consisting of a user prompt and an LLM response, is presented as a separate record, accompanied by additional metrics and classification labels calculated using the 'reddgr' family of models. Additionally, a simplified version of the dataset is provided, where messages belonging to the same conversation are wrapped into a single record.
创建时间:
2024-12-19
原始信息汇总
数据集概述
数据集信息
- 许可证: Apache 2.0
- 数据集大小: 591774 字节
- 下载大小: 303885 字节
特征信息
- conversation_id: 字符串类型,表示对话的唯一标识符。
- turn: 整数类型,表示对话的轮次。
- prompt: 字符串类型,表示用户的输入。
- response: 字符串类型,表示聊天机器人的响应。
- category: 字符串类型,表示对话的分类。
- language: 字符串类型,表示对话的语言。
- pred_label_rq: 字符串类型,表示使用rq模型预测的标签。
- prob_rq: 浮点数类型,表示rq模型预测的概率。
- pred_label_tl: 字符串类型,表示使用tl模型预测的标签。
- prob_tl: 浮点数类型,表示tl模型预测的概率。
- model_family: 字符串类型,表示模型家族。
- message_tag: 字符串类型,表示消息标签。
- date: 时间戳类型,表示对话的日期和时间。
- turns: 整数类型,表示对话的总轮次。
- source: 字符串类型,表示数据来源。
- conversation_tag: 字符串类型,表示对话标签。
数据分割
- train: 训练集,包含411个样本,占用591774字节。
配置
- config_name: default
- data_files:
- split: train
- path: data/train-*
- data_files:
数据集描述
该数据集包含与各种大型语言模型工具的对话,数据来源为Talking to Chatbots网站。与简化版本reddgr/talking-to-chatbots-chats不同,该扩展数据集将每个对话轮次(用户提示和聊天机器人响应的组合)作为单独的记录,并包含额外的指标和分类标签,这些标签是通过reddgr系列模型计算得出的。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于与多种大型语言模型(LLM)工具的对话,这些对话数据来源于[Talking to Chatbots](https://talkingtochatbots.com)网站。与简化的版本不同,此扩展数据集将每个对话轮次(即用户提示和LLM响应的组合)作为单独的记录呈现,并附加了由'reddgr'系列模型计算的分类标签和指标,如请求问题(rq)和测试学习(tl)的预测标签及其概率。
特点
该数据集的显著特点在于其详细记录了每个对话轮次的独立信息,包括用户提示、LLM响应、分类标签、语言类型、模型家族等。此外,数据集还包含了对话的时间戳、来源和标签信息,使得研究者能够深入分析对话的动态过程和模型性能。
使用方法
研究者可以通过加载该数据集,利用其中的对话轮次进行模型评估、对话生成策略的研究或分类任务的训练。数据集中的分类标签和概率值为研究提供了丰富的标注信息,有助于深入理解模型在不同对话场景中的表现。此外,数据集的结构化设计使得数据处理和分析更加高效。
背景与挑战
背景概述
随着自然语言处理技术的迅猛发展,对话系统,尤其是基于大型语言模型(LLM)的聊天机器人,已成为人工智能领域的重要研究方向。'talking-to-chatbots-unwrapped-chats'数据集由'Talking to Chatbots'网站的作者创建,旨在提供一个包含与多种LLM工具对话的详细记录的数据集。该数据集不仅记录了用户与聊天机器人的交互,还通过'reddgr'系列模型对对话进行了分类和分析,如请求/问题(rq)和测试/学习(tl)等标签。这一数据集的发布为研究者提供了丰富的资源,以深入探讨聊天机器人在不同情境下的表现及其潜在的改进空间。
当前挑战
尽管'talking-to-chatbots-unwrapped-chats'数据集为对话系统研究提供了宝贵的资源,但其构建和应用过程中仍面临诸多挑战。首先,对话数据的多样性和复杂性使得分类和标签的准确性成为一个难题,尤其是在处理多轮对话时,如何保持上下文的一致性尤为关键。其次,数据集的规模相对较小,可能限制其在大型模型训练中的应用效果。此外,随着聊天机器人技术的不断进步,如何持续更新和扩展数据集以反映最新的技术发展,也是一个亟待解决的问题。
常用场景
经典使用场景
该数据集的核心应用场景在于分析和评估大型语言模型(LLM)在对话系统中的表现。通过记录用户与LLM之间的交互,研究者可以深入探讨模型在处理不同类型问题时的响应质量、连贯性及准确性。此外,数据集中的分类标签和概率值为对话系统的自动化评估提供了丰富的量化指标,有助于优化模型的对话策略和用户交互体验。
解决学术问题
该数据集为解决对话系统中的多个学术问题提供了宝贵的资源。首先,它为研究者提供了大量真实的对话数据,有助于深入分析LLM在不同情境下的表现,从而推动对话系统的行为建模和性能优化。其次,数据集中的分类标签和概率值为对话内容的自动标注和分类提供了基准,推动了对话系统在语义理解和意图识别方面的研究进展。
衍生相关工作
基于该数据集,研究者已开展了一系列相关工作,包括对话系统的自动化评估框架、对话内容的语义分类模型以及对话策略的优化算法。这些工作不仅推动了对话系统在理论研究上的进展,还为实际应用中的对话系统提供了技术支持。此外,数据集的公开也为其他研究者提供了丰富的实验数据,促进了对话系统领域的开放研究和合作。
以上内容由遇见数据集搜集并总结生成


