RealFactBench
收藏arXiv2025-06-14 更新2025-06-19 收录
下载链接:
https://github.com/kalendsyang/RealFactBench.git
下载链接
链接失效反馈官方服务:
资源简介:
RealFactBench是一个用于评估大型语言模型(LLMs)和多媒体大型语言模型(MLLMs)在现实世界事实核查任务中能力的综合基准。该数据集由6000条高质量声明组成,这些声明来自权威来源,涵盖了多媒体内容和多个领域。RealFactBench包含三个任务:知识验证、谣言检测和事件验证,旨在评估模型在不同事实核查任务中的能力。数据集还包括了一个新的评估指标——未知率(UnR),用于评估模型处理不确定性的能力。通过在7个LLMs和4个MLLMs上的广泛实验,该基准揭示了模型在现实世界事实核查中的局限性,并为进一步研究提供了有价值的见解。
RealFactBench is a comprehensive benchmark for evaluating the capabilities of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) in real-world fact-checking tasks. This dataset consists of 6,000 high-quality claims sourced from authoritative sources, covering multimedia content and multiple domains. RealFactBench encompasses three tasks: knowledge verification, rumor detection, and event verification, which aim to assess models' performance across diverse fact-checking scenarios. The dataset also introduces a novel evaluation metric, Uncertainty Rate (UnR), to evaluate models' ability to handle uncertainty. Through extensive experiments conducted on 7 LLMs and 4 MLLMs, this benchmark reveals the limitations of current models in real-world fact-checking and provides valuable insights for further research.
提供机构:
香港大学, 清华大学, 蚂蚁集团, 伦敦大学学院, 香港大学, 香港大学, 蚂蚁集团, 蚂蚁集团, 香港大学
创建时间:
2025-06-14
搜集汇总
数据集介绍
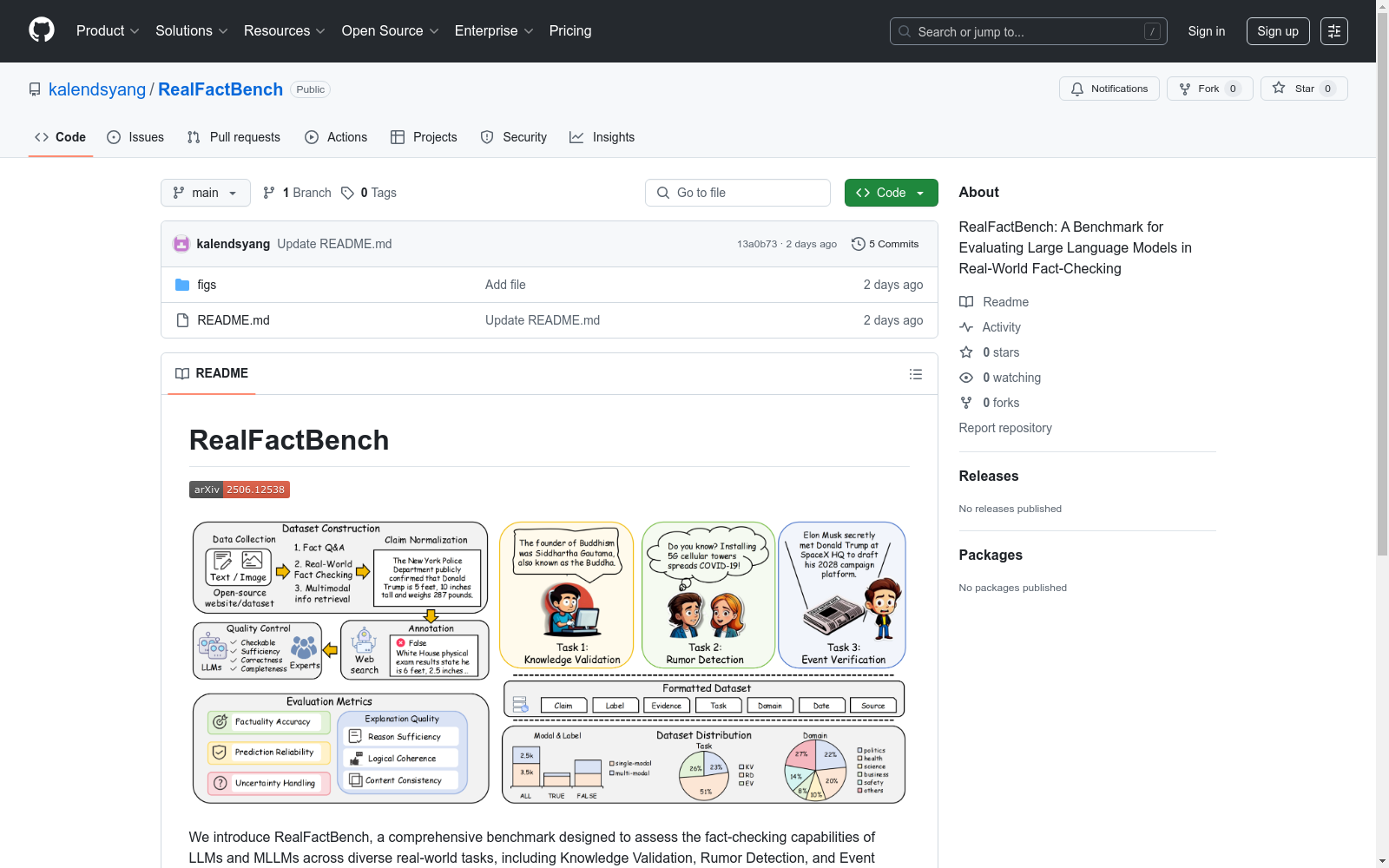
构建方式
在信息过载的时代,虚假或误导性内容在社会、经济、政治和医疗等多个领域广泛传播,亟需可靠且可扩展的事实核查系统。RealFactBench的构建遵循系统且严格的流程,以确保数据集的可靠性、多样性和对现实世界事实核查场景的适用性。构建过程包括四个关键阶段:数据收集、声明标准化、标注和质量控制。数据收集阶段整合了来自权威来源的人类验证数据集和收集数据,确保覆盖静态知识和动态事实核查场景。声明标准化阶段将声明标准化为模型可消费的陈述,确保一致性和统一评估。标注阶段为每个声明标注二元标签(TRUE/FALSE),并从可信来源检索支持证据。质量控制阶段结合了自动验证和专家审查的多级验证流程,确保每个声明的证据基础和事实核查相关性。
使用方法
RealFactBench的使用方法包括三个主要任务:知识验证、谣言检测和事件验证。知识验证任务评估模型对广泛认可和无可争议事实的掌握能力,如科学原理、历史数据和地理信息。谣言检测任务要求模型识别和分析通过公共渠道传播的虚假或误导性信息,运用逻辑推理和批判性思维检测不一致性。事件验证任务则聚焦于核查报道事件的准确性,模型需从多个来源收集信息、评估来源可靠性并进行交叉验证。评估框架采用四维矩阵:事实准确性、预测可靠性、不确定性处理和解释质量,全面评估模型在多样化现实世界事实核查场景中的能力。用户可通过统一提示模板进行模型评估,确保结果的可比性和可重复性。
背景与挑战
背景概述
RealFactBench是由香港大学、清华大学、蚂蚁集团和伦敦大学学院等机构的研究团队于2025年推出的一个综合性基准测试,旨在评估大型语言模型(LLMs)和多模态大型语言模型(MLLMs)在现实世界事实核查任务中的能力。该数据集包含6000个高质量声明,涵盖知识验证、谣言检测和事件验证三大任务,数据源自权威平台并经过严格处理,涉及政治、健康、科学等多个领域。RealFactBench的推出填补了现有基准测试在评估模型处理多模态内容和动态信息方面的不足,为开发更可靠的事实核查系统提供了重要工具。
当前挑战
RealFactBench面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,该数据集旨在解决现实世界中虚假或误导性内容广泛传播的问题,特别是在多模态内容和动态信息场景下的模型评估不足。构建过程中的挑战包括:1) 多模态数据的收集与对齐,确保文本和视觉内容的一致性;2) 动态信息的时效性处理,要求数据集能够反映不断演变的知识和事件;3) 评估指标的设计,特别是新引入的未知率(UnR)指标,需要平衡模型的保守性和过度自信行为。
常用场景
经典使用场景
RealFactBench作为评估大语言模型(LLMs)和多模态大语言模型(MLLMs)在现实世界事实核查任务中性能的基准,其经典使用场景包括知识验证、谣言检测和事件验证。通过整合来自权威来源的6K高质量多模态数据样本,该数据集能够全面测试模型在静态知识检索和动态信息分析中的表现。特别是在处理涉及政治、健康和科学等领域的复杂虚假信息时,RealFactBench通过引入未知率(UnR)等创新指标,为模型在不确定性处理方面的能力提供了精细化评估。
解决学术问题
RealFactBench解决了现有事实核查基准在数据表示、评估协议和场景覆盖方面的三大局限性。它通过整合多模态内容和真实世界事件,填补了传统文本基准在复杂输入模拟上的不足;通过UnR指标量化模型对不确定性的处理,纠正了随机猜测导致的评估偏差;同时支持结合外部检索工具的测试框架,推动了动态环境下的模型性能研究。这些创新为LLMs在知识错误、推理缺陷等核心问题的改进提供了可量化的研究基础。
实际应用
在实际应用中,RealFactBench能够支持自动化事实核查系统的开发与优化。新闻机构可利用其评估模型对突发新闻的真实性判断能力,社交媒体平台可基于谣言检测任务优化内容审核算法。医疗领域通过事件验证任务测试模型对疫情相关声明的核查效果,而政治领域则借助多模态分析识别深度伪造内容。该数据集特别适用于需要实时性、多源交叉验证的场景,如选举期间虚假信息的快速响应。
数据集最近研究
最新研究方向
在信息爆炸的时代,虚假或误导性内容的广泛传播已成为全球性挑战。RealFactBench作为评估大语言模型(LLMs)和多模态大语言模型(MLLMs)在现实世界事实核查能力的综合性基准,近期研究聚焦于三个前沿方向:一是多模态信息融合在复杂事实核查场景中的应用,特别是在处理图文混合的社交媒体内容时,模型需同时分析文本语义和视觉证据的一致性;二是动态知识更新机制的研究,针对事件验证等时效性强的任务,探索结合外部检索工具实现实时知识补充的有效方法;三是模型不确定性量化指标的优化,通过提出的Unknown Rate(UnR)等新型评估维度,深入分析模型在证据不足或知识边界情况下的决策可靠性。这些研究方向直接回应了当前AI事实核查系统在应对实时谣言、跨模态虚假信息等社会热点问题时的核心挑战,为构建更稳健的可解释性核查系统提供了重要方法论支撑。
相关研究论文
- 1RealFactBench: A Benchmark for Evaluating Large Language Models in Real-World Fact-Checking香港大学, 清华大学, 蚂蚁集团, 伦敦大学学院, 香港大学, 香港大学, 蚂蚁集团, 蚂蚁集团, 香港大学 · 2025年
以上内容由遇见数据集搜集并总结生成


