OG
收藏OG 数据集概述
数据集信息
特征
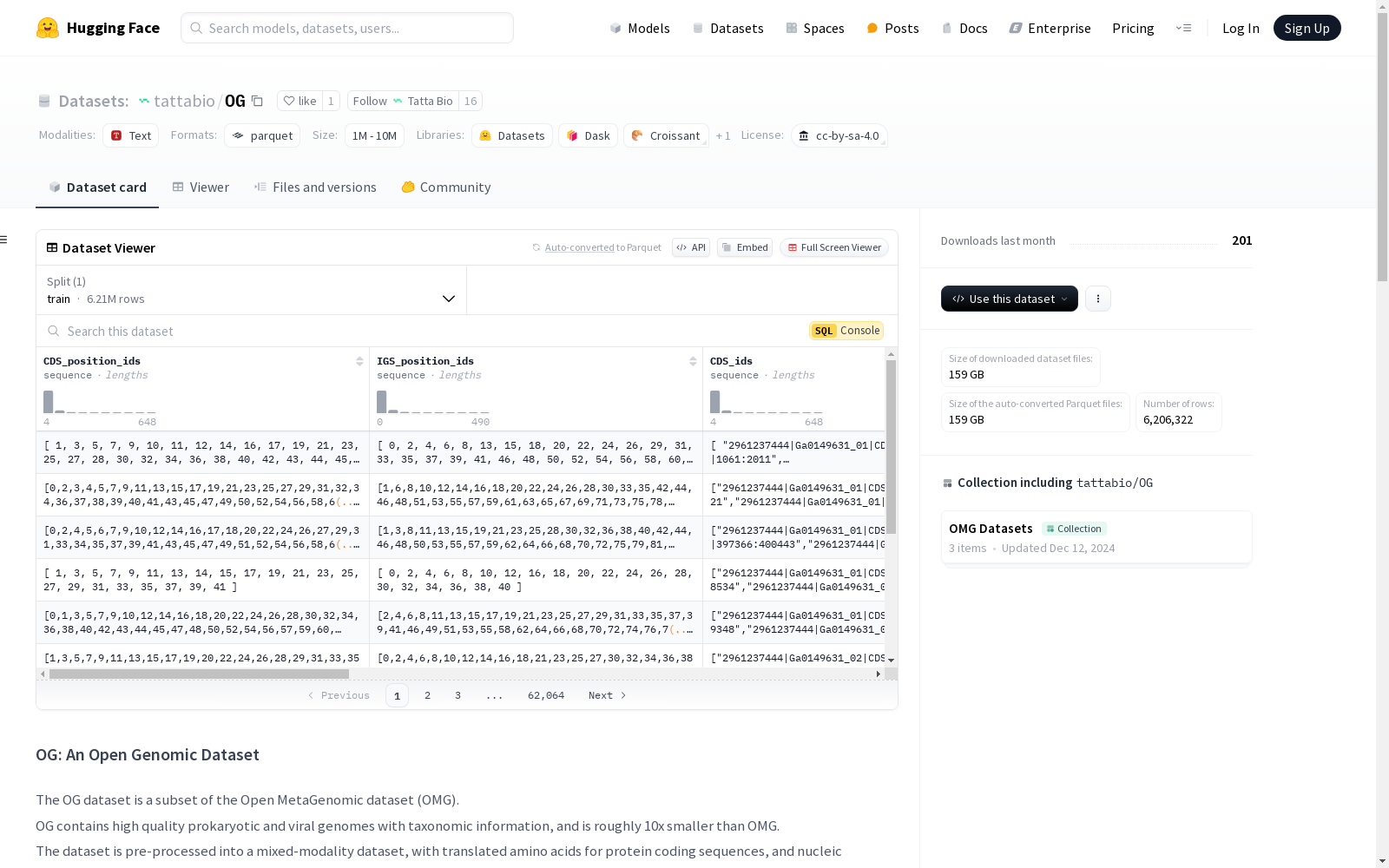
- CDS_position_ids: 整数序列,表示每个CDS元素在支架中的位置。
- IGS_position_ids: 整数序列,表示每个IGS元素在支架中的位置。
- CDS_ids: 字符串序列,表示每个CDS元素的标识符。
- IGS_ids: 字符串序列,表示每个IGS元素的标识符。
- CDS_seqs: 大字符串序列,表示氨基酸CDS序列。
- IGS_seqs: 大字符串序列,表示核苷酸IGS序列。
- CDS_orientations: 布尔序列,表示每个CDS的方向,
True表示正向链,False表示反向链。
分割
- train: 包含6206322个样本,占用219511418153字节。
大小
- 下载大小: 158645205736字节
- 数据集大小: 219511418153字节
配置
- default: 包含训练数据文件,路径为
data/train-*。
许可证
- cc-by-sa-4.0
数据集描述
OG数据集是Open MetaGenomic数据集(OMG)的一个子集,包含高质量的原核生物和病毒基因组,并带有分类信息。该数据集经过预处理,包含蛋白质编码序列的翻译氨基酸和间基因序列的核苷酸。
使用方法
python import datasets ds = datasets.load_dataset(tattabio/OG)
数据格式
每行数据表示一个基因组支架,包含氨基酸编码序列(CDS)和核苷酸间基因序列(IGS)的有序列表。
| 特征 | 描述 | 示例 |
|---|---|---|
CDS_seqs |
氨基酸CDS序列的字符串列表 | [MALTKVEKRNR..., MLGIDNIERVK..., MATIKVKQVR..., MNLSNIKPAS...] |
IGS_seqs |
核苷酸IGS序列的字符串列表 | [AATTTAAGGAA, TTTTAAAAGTATCGAAAT, TTTTTAAAGAAAA] |
CDS_position_ids |
CDS元素位置的整数列表 | [1, 3, 5, 6] |
IGS_position_ids |
IGS元素位置的整数列表 | [0, 2, 4] |
CDS_ids |
CDS元素的字符串标识符列表 | `[7000000126 |
IGS_ids |
IGS元素的字符串标识符列表 | `[7000000126 |
CDS_orientations |
CDS方向的布尔列表 | [True, True, True, False] |
CDS和IGS的ID字段格式为:sample_accession|contig_id|feature_type|gene_id|strand|start:end
引用
@article{Cornman2024, title = {The OMG dataset: An Open MetaGenomic corpus for mixed-modality genomic language modeling}, url = {https://www.biorxiv.org/content/early/2024/08/17/2024.08.14.607850}, DOI = {10.1101/2024.08.14.607850}, publisher = {Cold Spring Harbor Laboratory}, author = {Cornman, Andre and West-Roberts, Jacob and Camargo, Antonio Pedro and Roux, Simon and Beracochea, Martin and Mirdita, Milot and Ovchinnikov, Sergey and Hwang, Yunha}, year = {2024}, }