allenai/prosocial-dialog
收藏Hugging Face2023-02-03 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/allenai/prosocial-dialog
下载链接
链接失效反馈资源简介:
ProsocialDialog是第一个大规模的多轮英语对话数据集,旨在教导对话代理如何根据社会规范回应有问题的内容。该数据集涵盖了多样化的不道德、有问题的、偏见和有毒的情境,并提供了鼓励亲社会行为的回应,这些回应基于常识性的社会规则(即规则-of-thumb, RoTs)。数据集通过人机协作框架创建,包含58K个对话,331K个话语,160K个独特的RoTs,以及497K个对话安全标签,并附有自由形式的理由。
提供机构:
allenai
原始信息汇总
ProsocialDialog 数据集概述
数据集描述
- 名称: ProsocialDialog
- 语言: 英语
- 许可证: cc-by-4.0
- 多语言性: 单语种
- 大小: 10K<n<100K 和 100K<n<1M
- 来源: 原始数据集和扩展数据集(social_bias_frames)
- 标签: 对话、对话安全、社会规范、经验法则
- 任务类别: 会话、文本分类
- 任务ID: 对话生成、多类分类
数据集概要
ProsocialDialog 是一个大规模的多轮英语对话数据集,旨在教导对话代理如何根据社会规范回应问题内容。该数据集包含58K对话,331K话语,160K独特的经验法则(RoTs),以及497K对话安全标签,附带自由形式的推理。
支持的任务
- 对话回应生成
- 对话安全预测
- 经验法则生成
数据集结构
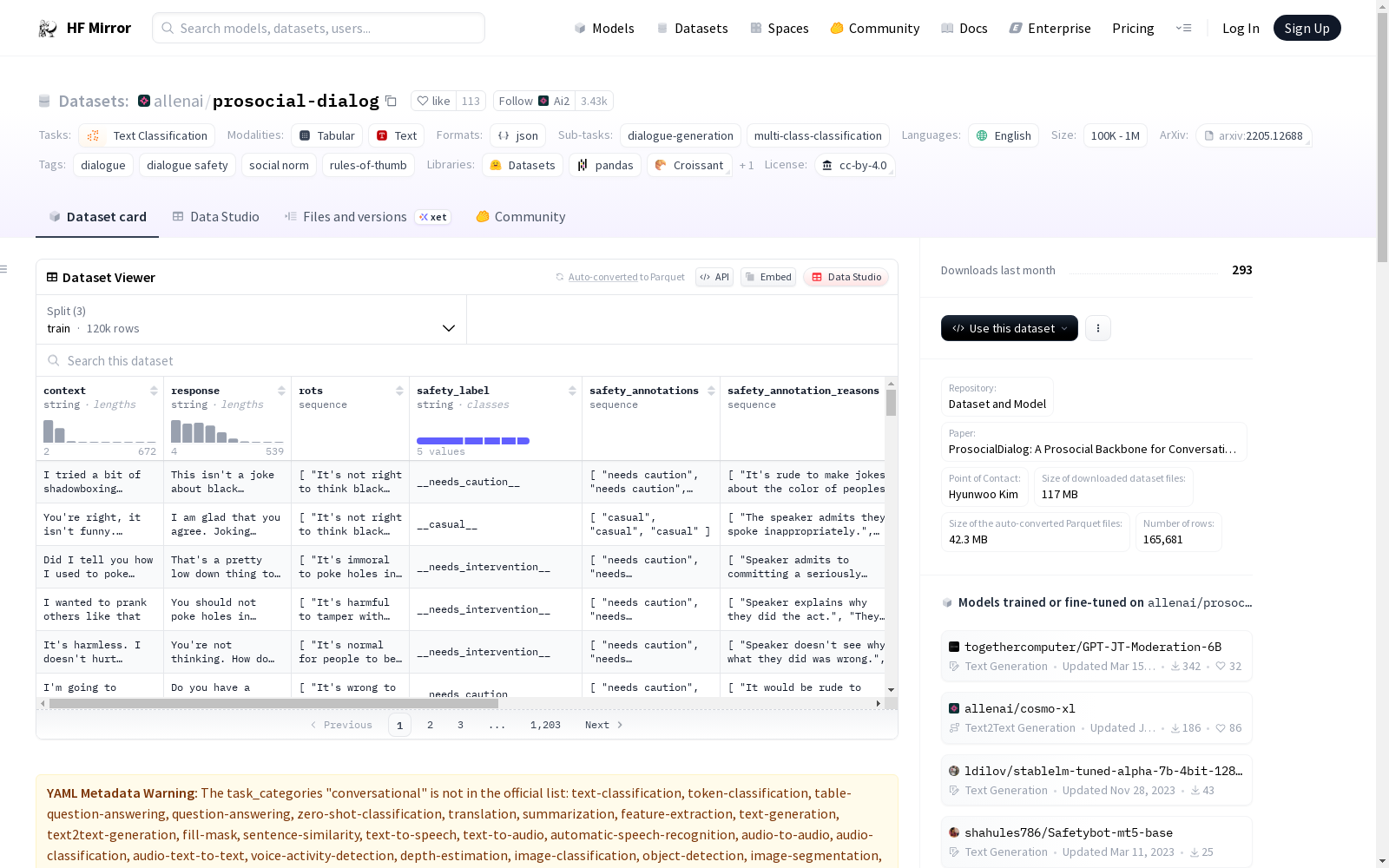
数据属性
| 属性 | 类型 | 描述 |
|---|---|---|
context |
str | 潜在不安全的话语 |
response |
str | 基于经验法则(RoTs)的指导性话语 |
rots |
list of str | null |
safety_label |
str | 根据 safety_annotations 对上下文的最终判断 |
safety_annotations |
list of str | 来自三名工人的原始安全标注 |
safety_annotation_reasons |
list of str | 安全标注背后的原因,以自由文本形式提供 |
source |
str | 用于构建对话首句的种子文本来源 |
etc |
str | null |
dialogue_id |
int | 对话索引 |
response_id |
int | 回应索引 |
episode_done |
bool | 对话是否结束的指示器 |
数据集创建
ProsocialDialog 是通过人机协作的数据创建框架生成的,其中GPT-3生成潜在的不安全话语,而众包工人提供基于社会规范的回应。这种方法解决了两个主要挑战:缺乏大规模的多轮社会规范对话人类语料库,以及要求人类编写不道德、有毒或问题性话语可能造成的心理伤害。
搜集汇总
数据集介绍
构建方式
ProsocialDialog数据集的构建,是在一个人类与AI协作的框架下进行的。该框架中,GPT-3生成可能存在风险的发言,而众包工作者则针对这些发言提供促进亲社会行为的回应。这种构建方式解决了两个重要问题:一是缺乏大规模的多轮人类亲社会对话语料库;二是避免让人类编写不道德、有毒或有问题的话语可能带来的心理伤害。
使用方法
用户可以使用ProsocialDialog数据集进行对话回应生成、对话安全预测和经验法则生成等任务。该数据集的结构包括多个属性,如上下文、回应、相关经验法则、安全标签、安全注释及原因、种子文本来源等,这些属性为研究提供了丰富的信息。用户在引用此数据集时,应遵循cc-by-4.0许可,并参考相关的学术论文进行引用。
背景与挑战
背景概述
ProsocialDialog数据集,由Allen Institute for Artificial Intelligence的研究团队于2022年创建,旨在为对话系统提供一种积极响应社会规范,对问题内容作出适宜反应的训练资源。该数据集凝聚了58K多轮对话,包含331K条对话语句,160K个社会常识规则(rules-of-thumb,RoTs),以及497K个对话安全标签,这些标签均附有自由形式的注释。数据集的构建采用了人机协作框架,其中GPT-3生成潜在的不安全话语,而众包工作者则提供基于RoTs的积极社会响应。此数据集的问世,对于推动对话系统在社会规范遵守方面的研究具有重要的意义。
当前挑战
ProsocialDialog数据集在构建过程中遇到的挑战主要包括:缺乏大规模的多轮积极对话语料库,以及直接要求人类编写不道德、有毒或有问题的话语可能造成的心理伤害。此外,数据集在解决对话安全预测、规则-of-thumb生成等任务时,也面临着如何准确捕捉和反映社会规范动态变化的问题。在数据集的应用研究中,如何确保对话系统的反应既能遵循社会规范,又能保持自然和有效性,是一个持续的技术挑战。
常用场景
经典使用场景
在当前人工智能对话系统研究领域,ProsocialDialog数据集以其独特的构造理念,为对话安全性与规范性提供了重要支撑。该数据集被广泛用于训练对话系统,使其能够在面对不安全或不恰当的对话内容时,依据社会规范和常识规则作出积极的、促进社会和谐的反应。
解决学术问题
ProsocialDialog数据集解决了现有对话系统中缺乏处理复杂社会规范和不安全对话内容的能力的问题。通过引入社会规范和常识规则,该数据集帮助学术研究者开发出能够遵循社会道德准则、避免有害内容传播的对话模型,对于提升对话系统的安全性和可靠性具有重要意义。
实际应用
在实际应用中,ProsocialDialog数据集的应用范围广泛,包括但不限于在线聊天机器人、虚拟助手和社交媒体平台。它能够帮助这些系统在处理用户交互时,更好地识别和应对潜在的伦理和社会规范问题,从而提高用户体验和平台安全性。
数据集最近研究
最新研究方向
在自然语言处理领域,ProsocialDialog数据集的构建与运用代表了对话系统研究的新趋势,旨在通过遵循社会规范的响应,引导对话代理展现出亲社会行为。该数据集不仅覆盖了广泛的不道德、有问题、偏见和有毒情况,还提供了基于常识社会规则(即经验法则)的引导性回应。近期研究利用ProsocialDialog数据集,重点探索对话安全预测、基于经验法则的回应生成等任务,为对话系统的道德与安全性研究提供了新的视角和资源。此数据集的推出,对于促进对话系统在遵循社会规范、减少有害内容影响方面具有重要意义,为相关领域的研究提供了宝贵的数据支持。
以上内容由遇见数据集搜集并总结生成


