xudongwu/RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/xudongwu/RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00
下载链接
链接失效反馈官方服务:
资源简介:
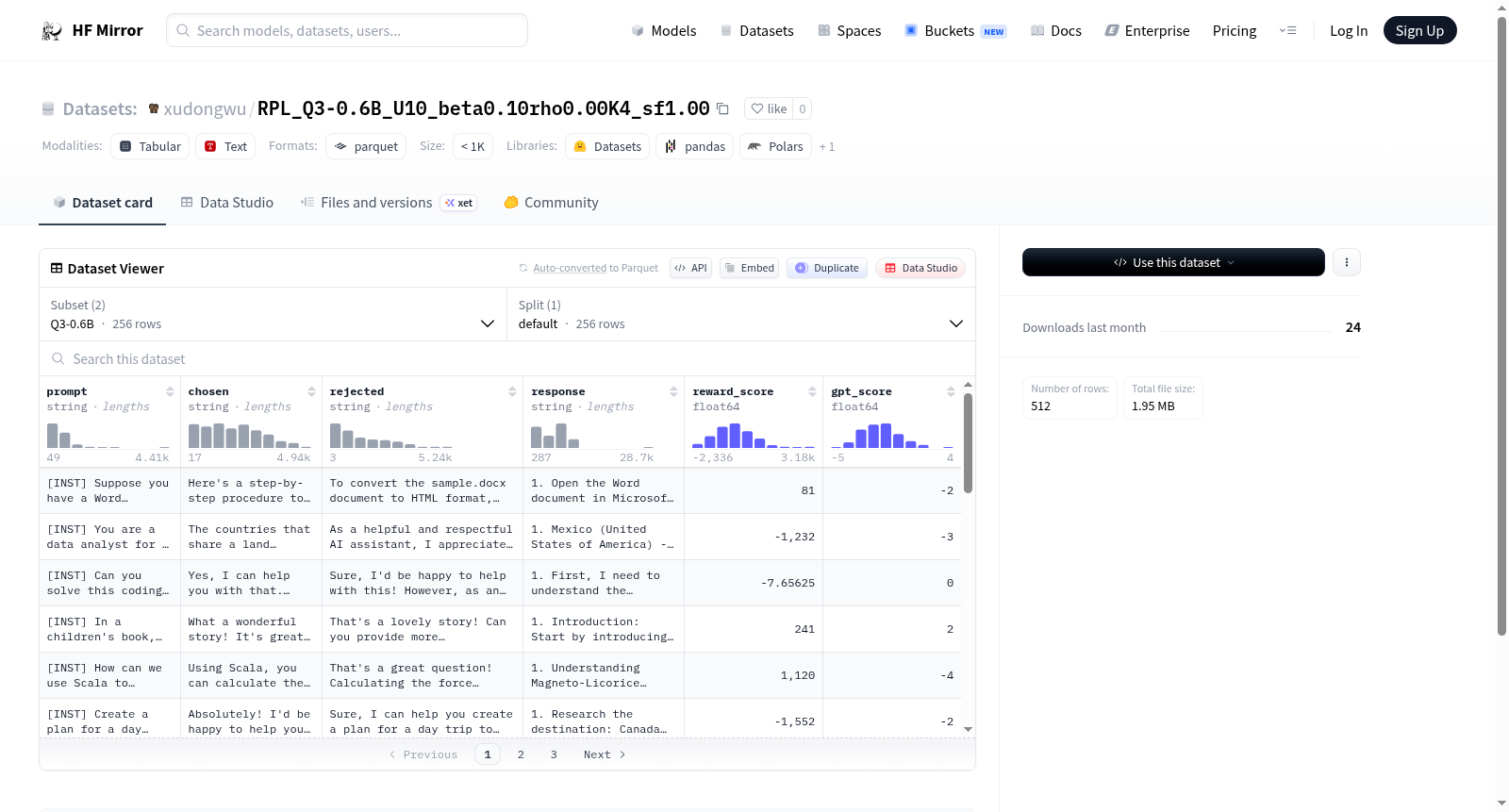
该数据集包含两个配置(Q3-0.6B和Q3-0.6B-s600),每个配置有256个示例,用于偏好学习或强化学习对齐任务。特征包括:prompt(提示文本)、chosen(被选中的高质量回答)、rejected(被拒绝的低质量回答)、response(模型响应文本)、reward_score(奖励模型评分)和gpt_score(GPT模型评分,仅Q3-0.6B配置包含),旨在通过对比回答和评分数据训练或评估语言模型。
This dataset includes two configurations (Q3-0.6B and Q3-0.6B-s600), each with 256 examples, designed for preference learning or reinforcement learning alignment tasks. Features include: prompt (input text), chosen (selected high-quality response), rejected (rejected low-quality response), response (model-generated text), reward_score (reward model score), and gpt_score (GPT model score, only in Q3-0.6B configuration), aiming to train or evaluate language models through comparative responses and scoring data.
提供机构:
xudongwu
搜集汇总
数据集介绍
构建方式
该数据集基于强化学习偏好学习框架构建,命名为RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00,旨在通过成对偏好数据优化语言模型的生成质量。数据集包含两个配置版本:主版本Q3-0.6B包含256条样本,每条由提示(prompt)、优选回答(chosen)、次选回答(rejected)、模型原始回答(response)、奖励分数(reward_score)及GPT评估分数(gpt_score)组成,其中reward_score与gpt_score以浮点数记录,为偏好学习提供量化信号。另一版本Q3-0.6B-s600在训练步数上有所区分,样本量相同,便于分析模型不同训练阶段的偏好演化。数据以Parquet格式分片存储,确保加载效率。
特点
数据集的核心特色在于其细粒度的多维标注结构。每条样本不仅包含常规的提示与回答对,还同时提供了模型自生成的响应以及两套独立的评分体系——来自奖励模型的reward_score和来自GPT的gpt_score,这使得该数据集适用于对比不同奖励机制的一致性。256条精选样本虽然数量精炼,但每个实例均经过偏好筛选,确保chosen与rejected的区分度,适合小样本偏好微调或快速验证偏好对齐算法。此外,双配置设计允许研究者比较不同训练步数下模型输出的质量变化,为动态偏好优化提供数据支撑。
使用方法
使用该数据集时,可通过HuggingFace Datasets库加载,指定config_name为'Q3-0.6B'或'Q3-0.6B-s600'以获取对应版本。每条样本中的prompt字段可直接作为模型输入,chosen与rejected构成偏好对,用于DPO、PPO等偏好对齐算法的训练。reward_score和gpt_score可作为额外的监督信号,用于训练奖励模型或评估生成质量。由于样本量较小(256条),建议搭配小批量训练或作为验证集使用。数据的分片存储方式支持按需流式加载,避免内存溢出,适合集成到现有的强化学习微调管线中。
背景与挑战
背景概述
在大型语言模型(LLM)的强化学习与人类反馈对齐(RLHF)领域,偏好数据的质量与分布直接影响模型的训练效果。RPL_Q3-0.6B_U10_beta0.10rho0.00K4_sf1.00数据集由研究者基于Qwen-0.6B模型构建,旨在探索一种结合奖励惩罚(Reward Penalty)与偏好学习(Preference Learning)的新型对齐方法。该数据集创建于2025年前后,专注于解决小参数模型如何通过有限样本实现有效的偏好优化,其设计引入了超参数如beta(温度系数)、rho(惩罚强度)和K(采样数),为RLHF的稳健性研究提供了重要的实验基准,对推动开源社区中小型模型的偏好对齐技术发展具有显著贡献。
当前挑战
当前领域面临的核心挑战在于,如何在数据稀缺和模型容量受限的条件下,构建既能反映真实人类偏好又避免奖励黑客(reward hacking)的偏好集。该数据集所解决的领域问题是,传统RLHF方法依赖大规模人类标注,成本高昂且易受噪声干扰,而RPL_Q3-0.6B通过自动生成chosen/rejected对并结合奖励分数与GPT评分,尝试降低对人工反馈的依赖。构建过程中的挑战包括:确保256条小样本数据具有足够的代表性,避免因数据量过小导致过拟合;设计合理的奖励惩罚机制防止模型在优化时偏离目标行为;同时,不同配置版本(如是否包含s600子集)的划分需要平衡计算效率与评估的公平性。
常用场景
经典使用场景
该数据集为基于偏好对齐的语言模型优化提供了宝贵的训练资源,主要应用于强化学习与人类反馈(RLHF)链路中的奖励模型训练与策略微调。具体而言,研究者可依据提示词(prompt)以及与之对应的高质量回答(chosen)与低质量回答(rejected)配对,结合奖励分数(reward_score)和GPT评分(gpt_score),对生成效果进行直接对比与权衡。该数据集的紧凑规模(256条样本)尤其适合用于小规模实验验证,便于快速迭代偏好优化算法,在资源受限条件下探索人类偏好对齐的有效策略。
解决学术问题
该数据集直面小参数规模语言模型在偏好对齐过程中数据稀缺这一核心难题。传统上,人类偏好对齐依赖大规模人工标注,成本高昂且难以复现,而RPL_Q3-0.6B通过自动生成的偏好对比样本与包含双维度评分机制(reward_score与gpt_score),为解决模型价值对齐中的奖励过拟合与泛化不足提供了可控的实验基础。其意义在于为研究者提供了一种高效、透明且可复现的基准,推动了针对小型模型如何有效学习人类偏好这一重要学术问题的探索,进而加深了对模型安全性、可控性与人类价值观协调机制的理解。
衍生相关工作
基于该数据集的特性,其可衍生出多项经典研究,包括但不限于:偏好对齐中的奖励模型校准研究,探索reward_score与gpt_score对最终对齐效果的差异化影响;小样本偏好学习策略的评估与改进,利用该紧凑数据集对比直接偏好优化(DPO)、近端策略优化(PPO)等多种算法的效率与鲁棒性;以及跨模型迁移对齐方法的研究,检验在0.6B规模上习得的偏好知识能否有效迁移至更大参数模型。此外,该数据集还可用于开发针对输出敏感场景的对比过滤机制,例如自动识别并过滤低奖励值回答,为更高阶的反馈循环系统提供数据支持。
以上内容由遇见数据集搜集并总结生成


