Deepthink-Reasoning
收藏官方服务:
资源简介:
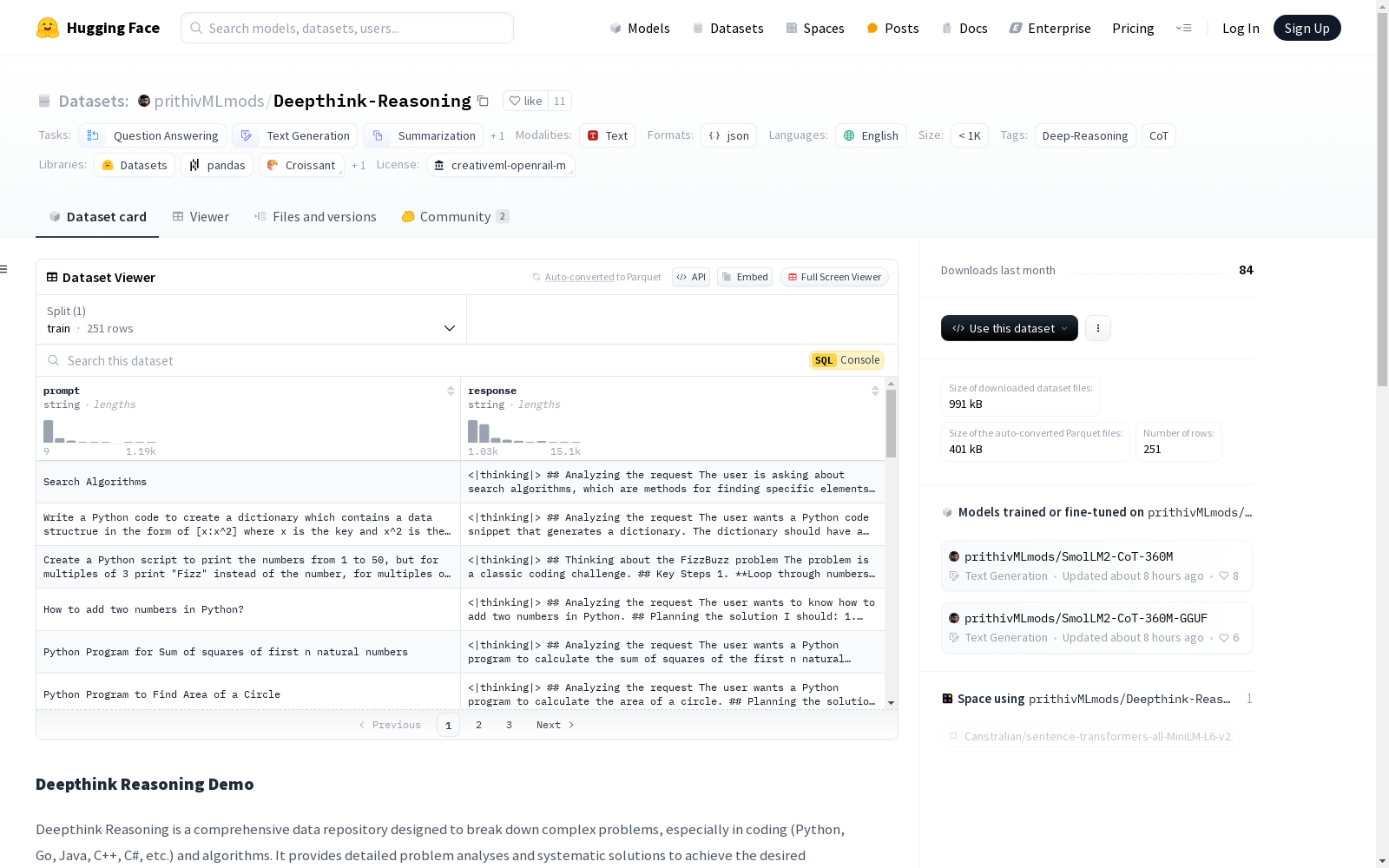
Deepthink Reasoning Demo是一个全面的数据仓库,旨在分解复杂问题,特别是在编码(Python、Go、Java、C++、C#等)和算法方面。它提供了详细的问题分析和系统解决方案,以实现预期结果。数据集包含从Deepseek、Llama、OpenAI和Claude Sonnet等模型合成的数据,所有内容均为英文。
Deepthink Reasoning Demo is a comprehensive data warehouse designed to decompose complex problems, especially in the domains of coding (Python, Go, Java, C++, C#, etc.) and algorithms. It provides detailed problem analyses and systematic solutions to achieve the intended results. The dataset contains synthetic data derived from models such as Deepseek, Llama, OpenAI, and Claude Sonnet, with all content written in English.
创建时间:
2024-12-28
搜集汇总
数据集介绍
构建方式
Deepthink-Reasoning数据集的构建依托于多种先进的人工智能模型,包括Deepseek、Llama、OpenAI和Claude Sonnet。这些模型通过合成推理的方式生成数据,确保数据集在编程语言(如Python、Go、Java、C++、C#等)和算法领域的广泛覆盖。数据集的构建过程注重问题的分解与系统化解决方案的生成,旨在提供高质量的推理与分析内容。
特点
Deepthink-Reasoning数据集以其全面性和结构化推理方法著称。其核心特点在于将复杂问题分解为更小的可管理组件,便于用户深入理解并生成解决方案。数据集涵盖多种编程语言,并提供详细的算法分步解析,采用‘思维链’(Chain of Thought)推理方法,增强了问题解决的清晰度与逻辑性。所有内容均以英文呈现,确保了全球用户的易用性。
使用方法
Deepthink-Reasoning数据集适用于开发人员、数据科学家以及算法爱好者,旨在提升其编程与算法开发能力。用户可通过该数据集学习如何系统化地分解问题,并掌握高效的推理方法。无论是用于教学、研究还是实际项目开发,该数据集都能为用户提供丰富的资源,助力其提升分析与解决问题的能力。
背景与挑战
背景概述
Deepthink-Reasoning数据集由Surendhar和Prithiv Sakthi等研究人员于近期创建,旨在通过系统化的方法解决编程和算法领域的复杂问题。该数据集特别关注Python、Go、Java、C++和C#等多种编程语言,并采用“思维链”(Chain of Thought)推理方法,将复杂问题分解为更小、更易管理的部分,从而提供清晰的结构化解决方案。其数据来源包括Deepseek、Llama、OpenAI和Claude Sonnet等模型,确保了数据的多样性和高质量。该数据集的推出为开发者和数据科学家提供了一个强大的工具,以提升他们在编程和算法开发中的问题分析与解决能力。
当前挑战
Deepthink-Reasoning数据集在解决编程和算法问题的过程中面临多重挑战。首先,如何将复杂的编程问题分解为逻辑清晰且易于理解的步骤,同时保持解决方案的准确性和完整性,是一个核心难题。其次,数据集的构建依赖于多种模型(如Deepseek、Llama等)的合成推理,这可能导致数据一致性和质量控制的挑战。此外,尽管数据集以英语为主要语言,但在全球范围内推广时,如何确保其内容对不同语言背景的用户具有普适性,也是一个需要解决的问题。这些挑战不仅考验了数据集的构建技术,也对其在实际应用中的有效性提出了更高要求。
常用场景
经典使用场景
Deepthink-Reasoning数据集在编程和算法领域展现了其独特的价值,尤其是在解决复杂问题时。该数据集通过将问题分解为更小的、可管理的部分,帮助开发者和研究人员更好地理解问题结构,并生成系统化的解决方案。其经典的链式思维(Chain of Thought)方法为问题解决提供了清晰的逻辑路径,特别适用于多编程语言(如Python、Java、C++等)和算法优化的场景。
解决学术问题
Deepthink-Reasoning数据集为学术研究提供了重要的支持,尤其是在编程语言理解和算法分析领域。通过其详细的步骤分解和链式思维方法,研究人员能够更深入地探索复杂问题的解决路径,从而推动编程教育和算法优化的研究进展。该数据集不仅帮助解决了多语言编程中的共性问题,还为算法设计中的逻辑推理提供了新的视角,具有重要的学术意义。
衍生相关工作
Deepthink-Reasoning数据集衍生了一系列经典的研究工作,尤其是在智能编程助手和自动化代码生成领域。基于该数据集的研究成果,许多学者开发了新的算法和工具,用于优化编程语言的学习曲线和提升代码生成效率。此外,该数据集还启发了链式思维方法在自然语言处理任务中的应用,为多模态推理和复杂问题解决提供了新的研究方向。
以上内容由遇见数据集搜集并总结生成


