Visual Persona-500K
收藏arXiv2025-03-20 更新2025-03-21 收录
下载链接:
https://cvlab-kaist.github.io/Visual-Persona
下载链接
链接失效反馈官方服务:
资源简介:
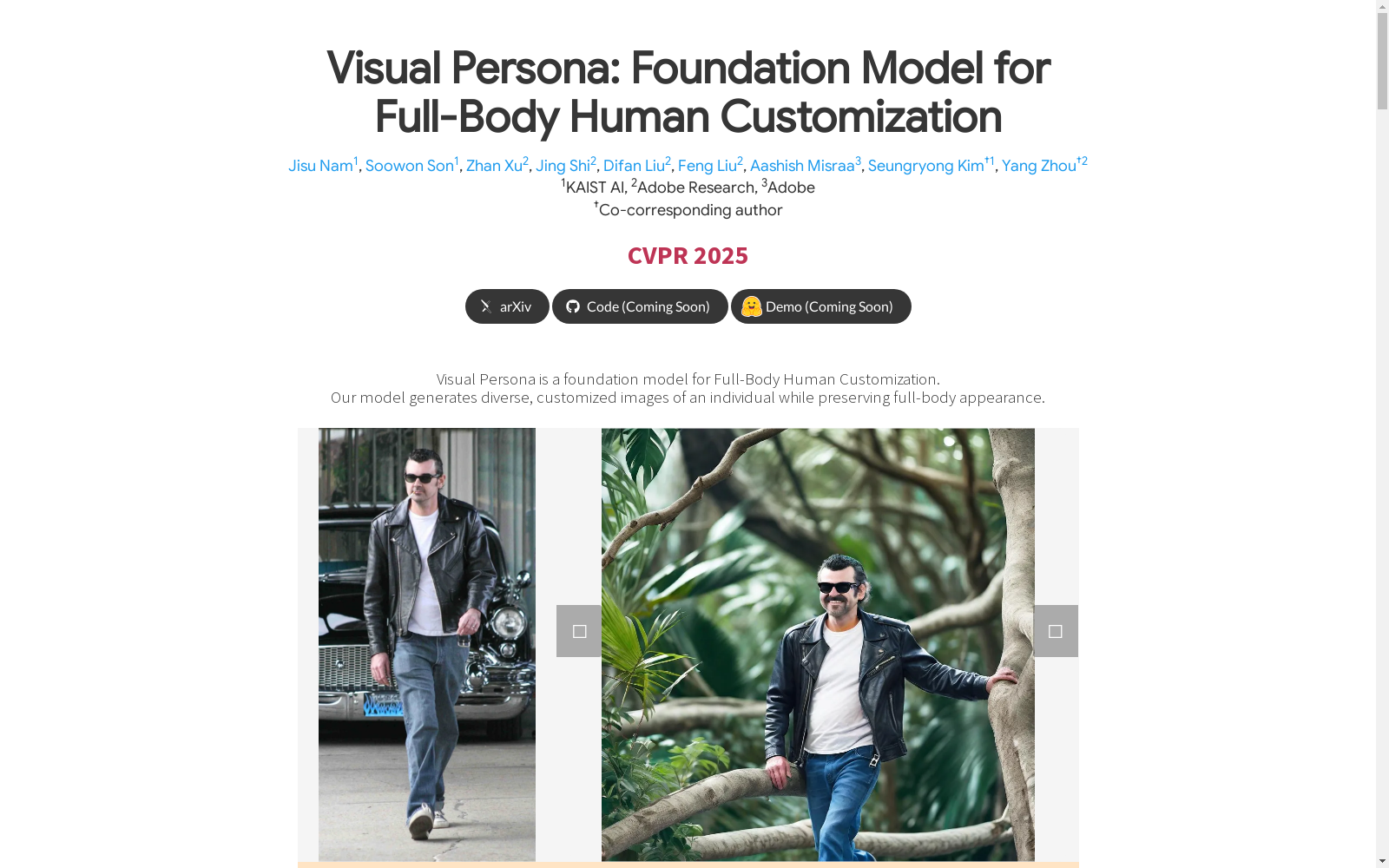
Visual Persona-500K是由韩国科学技术院(KAIST AI)和Adobe Research创建的大型数据集,包含580k张配对的人体图像,涵盖100k个独特身份。该数据集通过视觉语言模型评估人体外观一致性,生成详细文本描述,以区分个体身份和图像内的变化。数据集广泛应用于全身人体定制领域,解决了文本对齐和身份保持两大关键问题,可应用于虚拟试穿、人体风格化和角色定制等多种应用场景。
Visual Persona-500K is a large-scale dataset created by the Korea Advanced Institute of Science and Technology (KAIST AI) and Adobe Research. It contains 580k paired human images covering 100k unique identities. This dataset uses vision-language models to assess the consistency of human appearance, and generates detailed textual descriptions to distinguish individual identities and intra-image variations. Widely applied in the field of full-body human customization, the dataset addresses two key challenges: text alignment and identity preservation. It can be deployed in various application scenarios such as virtual try-on, human stylization and character customization.
创建时间:
2025-03-20
搜集汇总
数据集介绍
构建方式
Visual Persona-500K数据集的构建采用了大规模成对人类数据,确保每个个体的全身外观一致性。通过从大量未配对的人类图像库中筛选,利用视觉语言模型(VLM)评估全身视觉一致性,并结合详细的文本描述来解耦个体身份与文本提示中的个体内部变化。最终,该数据集包含580,000张带有文本描述的图像,涵盖100,000个独特的全身身份。
特点
Visual Persona-500K数据集的特点在于其大规模的成对图像和全身外观一致性。每个个体包含多个图像,确保身份的一致性,同时通过文本描述捕捉个体在不同场景和动作中的变化。数据集涵盖了广泛的种族、年龄和性别多样性,并且通过身体解析方法将图像分割为多个身体区域,进一步增强了数据的多样性和细节。
使用方法
Visual Persona-500K数据集主要用于训练和评估全身人类定制模型。通过输入单张人类图像和文本描述,模型能够生成多样化的定制图像,同时保持输入图像的全身外观一致性。该数据集支持多种下游任务,如文本引导的虚拟试穿、人类风格化和角色定制。使用该数据集时,研究人员可以通过调整模型参数来平衡身份保持和文本对齐,从而生成高质量的定制图像。
背景与挑战
背景概述
Visual Persona-500K数据集由KAIST AI和Adobe Research的研究团队于2025年提出,旨在解决全身体人像定制问题。该数据集包含58万张配对的全身人像图像,涵盖10万个独特的身份。与以往专注于面部识别的数据集不同,Visual Persona-500K通过文本描述生成多样化的全身人像图像,推动了文本到图像生成领域的发展。该数据集的构建基于大规模配对人像数据的需求,解决了传统方法中难以获取多张同一身份图像的问题。通过视觉语言模型(VLM)评估全身外观一致性,Visual Persona-500K为全身体人像定制提供了坚实的基础,广泛应用于虚拟试衣、人像风格化和角色定制等领域。
当前挑战
Visual Persona-500K在构建和应用过程中面临多重挑战。首先,获取大规模配对人像数据极为困难,传统方法通常依赖单张图像,难以保持全身外观的一致性。其次,生成图像时需同时满足文本对齐和身份保持的要求,尤其是在复杂的身体结构和场景变化下,确保生成的图像既符合文本描述,又保留输入图像的身份特征。此外,预训练的文本到图像扩散模型在生成人体图像时容易出现身体比例不准确的问题,如手指融合或多余肢体。尽管通过负向提示词可以部分缓解这一问题,但仍需进一步优化模型以生成更自然的人体图像。
常用场景
经典使用场景
Visual Persona-500K数据集在文本到图像生成领域中被广泛用于全身人物定制任务。通过输入单张人物图像和文本描述,模型能够生成与文本描述高度一致且保持全身外观一致性的多样化图像。这一经典使用场景涵盖了虚拟试衣、人物风格化以及角色定制等多个应用方向,极大地推动了生成模型在人物定制领域的发展。
衍生相关工作
Visual Persona-500K数据集衍生了许多相关经典工作,特别是在全身人物定制和文本到图像生成领域。基于该数据集的研究提出了多种改进模型,如基于Transformer的编码器-解码器架构,进一步提升了生成图像的质量和多样性。此外,该数据集还推动了虚拟试衣、人物风格化等应用的发展,衍生出如StoryMaker、PhotoMaker等经典模型,极大地扩展了生成模型的应用范围。
数据集最近研究
最新研究方向
近年来,Visual Persona-500K数据集在计算机视觉领域引起了广泛关注,尤其是在全身人体定制(Full-Body Human Customization)方向。该数据集通过结合视觉语言模型(VLMs)和文本到图像生成技术,推动了基于文本描述的全身人体图像生成研究。当前的研究热点主要集中在如何通过大规模配对数据实现身份保持与文本对齐的平衡。Visual Persona-500K通过构建包含58万张图像和10万个独特身份的配对数据集,解决了传统方法中难以获取大规模全身一致性数据的难题。该数据集的应用场景广泛,包括虚拟试衣、人体风格化、角色定制等,尤其在虚拟现实、电影制作和时尚设计等领域具有重要影响。未来,随着生成模型和视觉语言模型的进一步发展,Visual Persona-500K有望在更复杂的场景中实现更高精度的人体图像生成与定制。
相关研究论文
- 1Visual Persona: Foundation Model for Full-Body Human Customization韩国科学技术院(KAIST AI), Adobe Research · 2025年
以上内容由遇见数据集搜集并总结生成


