facial-landmark-dataset
收藏github2024-04-26 更新2024-05-31 收录
下载链接:
https://github.com/yinguobing/facial-landmark-dataset
下载链接
链接失效反馈官方服务:
资源简介:
一个公开的面部地标数据集集合,包含多个数据集,如300-W、300-VW、AFW等,每个数据集都有详细的属性描述,如作者、发布年份、标记数量和样本数量。
A publicly available collection of facial landmark datasets, encompassing multiple datasets such as 300-W, 300-VW, AFW, among others. Each dataset is accompanied by detailed attribute descriptions, including the authors, publication year, number of annotations, and sample size.
创建时间:
2020-07-29
原始信息汇总
数据集概述
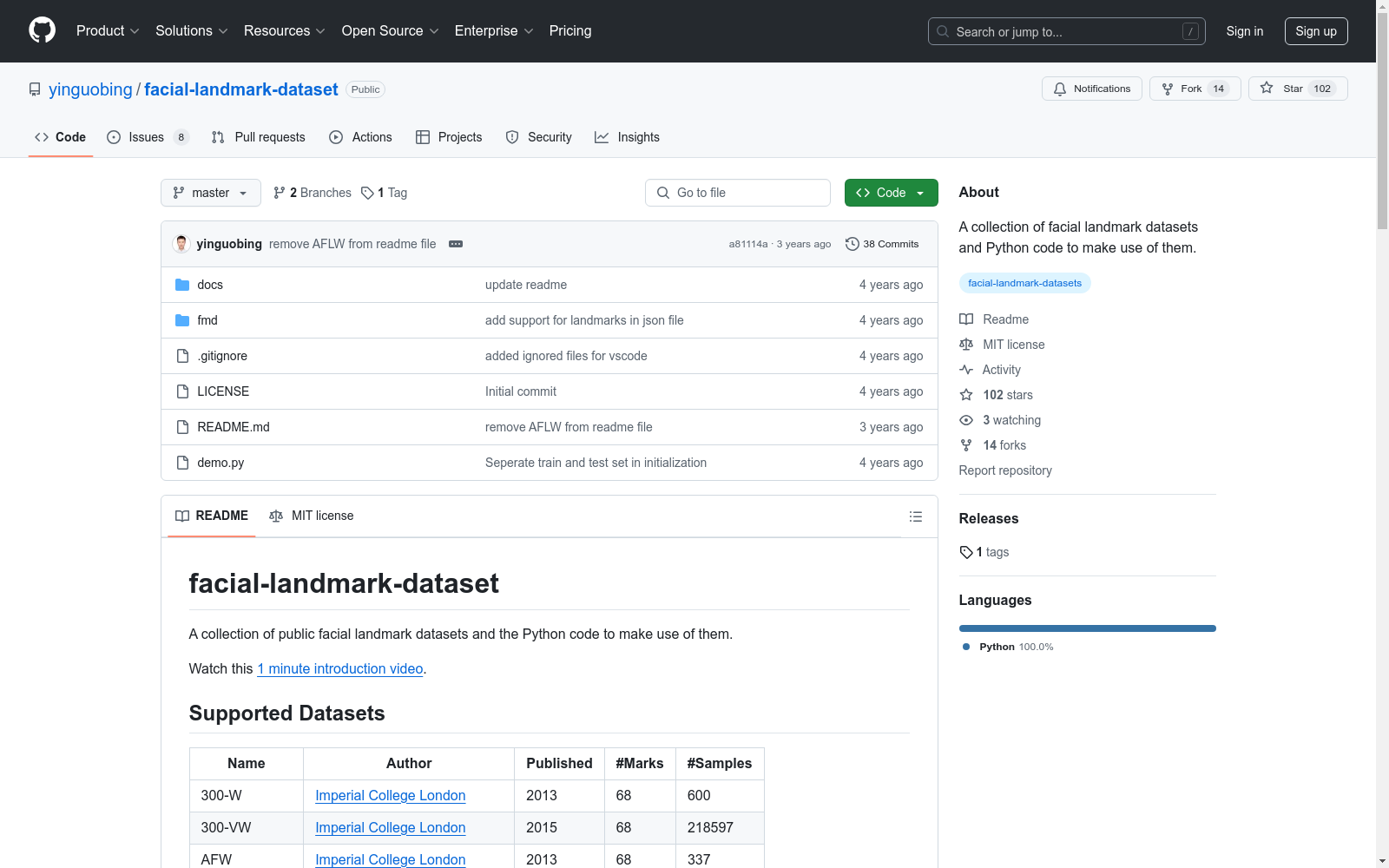
支持的数据集列表
| 名称 | 作者 | 发布年份 | 标记点数量 | 样本数量 |
|---|---|---|---|---|
| 300-W | Imperial College London | 2013 | 68 | 600 |
| 300-VW | Imperial College London | 2015 | 68 | 218597 |
| AFW | Imperial College London | 2013 | 68 | 337 |
| AFLW2000-3D | Chinese Academy of Sciences | 2015 | 68 | 2000 |
| HELEN | Imperial College London | 2013 | 68 | 2330 |
| IBUG | Imperial College London | 2013 | 68 | 135 |
| LFPW | Imperial College London | 2013 | 68 | 1035 |
| WFLW | Tsinghua National Laboratory | 2018 | 98 | 10000 |
数据集要求
- 需要面部图像和标记坐标。
- 部分数据集使用其他数据集的现有图像,此时数据集以图像数据集命名。
数据集操作示例
以300W数据集为例:
python from fmd.ds300w import DS300W
DS300W_DIR = "/home/robin/data/facial-marks/300W" ds = DS300W("300w") ds.populate_dataset(DS300W_DIR) print(ds)
输出示例:
bash name: 300w authors: Imperial College London year: 2013 num_marks: 68 num_samples: 600
数据集操作功能
- 随机选择样本:
sample = ds.pick_one() - 遍历数据集:
for sample in ds: - 读取图像文件:
image = sample.read_image() - 获取完整标记点:
facial_marks = sample.marks - 获取关键标记点:
key_marks = sample.get_key_marks() - 绘制标记点:
draw_marks(image, facial_marks)
搜集汇总
数据集介绍
构建方式
该数据集的构建方式主要通过整合多个公开的面部关键点数据集,涵盖了从2013年至2018年发布的多种数据集,如300-W、300-VW、AFW等。这些数据集由不同的研究机构发布,包括帝国理工学院和中国科学院等。每个数据集均包含面部图像及其对应的关键点坐标,关键点数量从68到98不等。通过Python代码,用户可以轻松地将这些数据集整合并加载到本地环境中进行进一步处理和分析。
特点
该数据集的特点在于其多样性和广泛性,涵盖了多个知名面部关键点数据集,且每个数据集的关键点数量和样本数量各异,能够满足不同研究需求。此外,数据集中的图像和关键点坐标均经过精心标注,确保了数据的准确性和可靠性。通过Python代码的封装,用户可以方便地访问和操作这些数据集,极大地简化了数据处理流程。
使用方法
使用该数据集时,用户首先需要通过Git克隆项目到本地,并安装必要的依赖库,如OpenCV 4.x。随后,用户可以通过Python代码初始化并加载特定的数据集,如300-W。加载后,用户可以随机选取样本、枚举数据集、读取图像文件以及获取关键点坐标等操作。此外,用户还可以绘制关键点,便于可视化分析。该数据集的使用方法简单直观,适合用于面部关键点检测和相关研究。
背景与挑战
背景概述
面部特征点检测是计算机视觉领域的重要研究方向,旨在通过识别和定位面部关键点来实现人脸分析、表情识别等应用。facial-landmark-dataset数据集由尹国冰(Yin Guobing)创建,汇集了多个公开的面部特征点数据集,涵盖了从2013年至2018年的多个版本,主要由帝国理工学院(Imperial College London)和中国科学院等机构发布。该数据集的核心研究问题是如何准确地定位面部特征点,以提高人脸识别、表情分析等任务的精度。其影响力在于为研究人员提供了丰富的资源,推动了面部特征点检测技术的发展。
当前挑战
面部特征点检测面临的主要挑战包括:1) 不同光照、姿态和表情下特征点的准确识别;2) 数据集的多样性和规模,如300-VW数据集包含218597个样本,而IBUG数据集仅有135个样本,如何处理数据集的不平衡性;3) 数据集构建过程中,如何确保特征点的标注准确性和一致性,尤其是在多源数据集的整合中。此外,不同数据集的特征点数量和定义存在差异,如300-W数据集使用68个特征点,而WFLW数据集则使用98个特征点,这为模型的泛化能力带来了挑战。
常用场景
经典使用场景
在计算机视觉领域,面部特征点数据集(facial-landmark-dataset)广泛应用于人脸识别、表情分析和姿态估计等任务。该数据集通过提供精确的面部特征点标注,使得研究人员能够训练和验证各种基于深度学习的人脸分析模型。例如,通过分析面部特征点的分布,可以实现高精度的人脸对齐,从而提升人脸识别系统的性能。此外,该数据集还可用于研究面部表情的细微变化,为情感计算提供基础数据支持。
实际应用
在实际应用中,面部特征点数据集被广泛应用于人脸识别系统、虚拟现实、增强现实以及医疗诊断等领域。例如,在人脸识别系统中,通过精确的特征点检测,可以实现高精度的身份验证。在虚拟现实和增强现实中,面部特征点的实时检测和跟踪能够提升用户体验,使得虚拟角色的表情更加自然。在医疗领域,该数据集可用于分析面部畸形或疾病,辅助医生进行诊断和治疗。
衍生相关工作
基于该数据集,研究人员开发了多种面部特征点检测算法和模型,推动了相关领域的技术进步。例如,基于300-W数据集的研究工作提出了多种改进的特征点检测方法,显著提升了检测精度。此外,WFLW数据集的引入进一步推动了高精度面部特征点检测的研究,尤其是在复杂场景下的应用。这些衍生工作不仅丰富了计算机视觉领域的研究内容,还为实际应用提供了强有力的技术支持。
以上内容由遇见数据集搜集并总结生成


