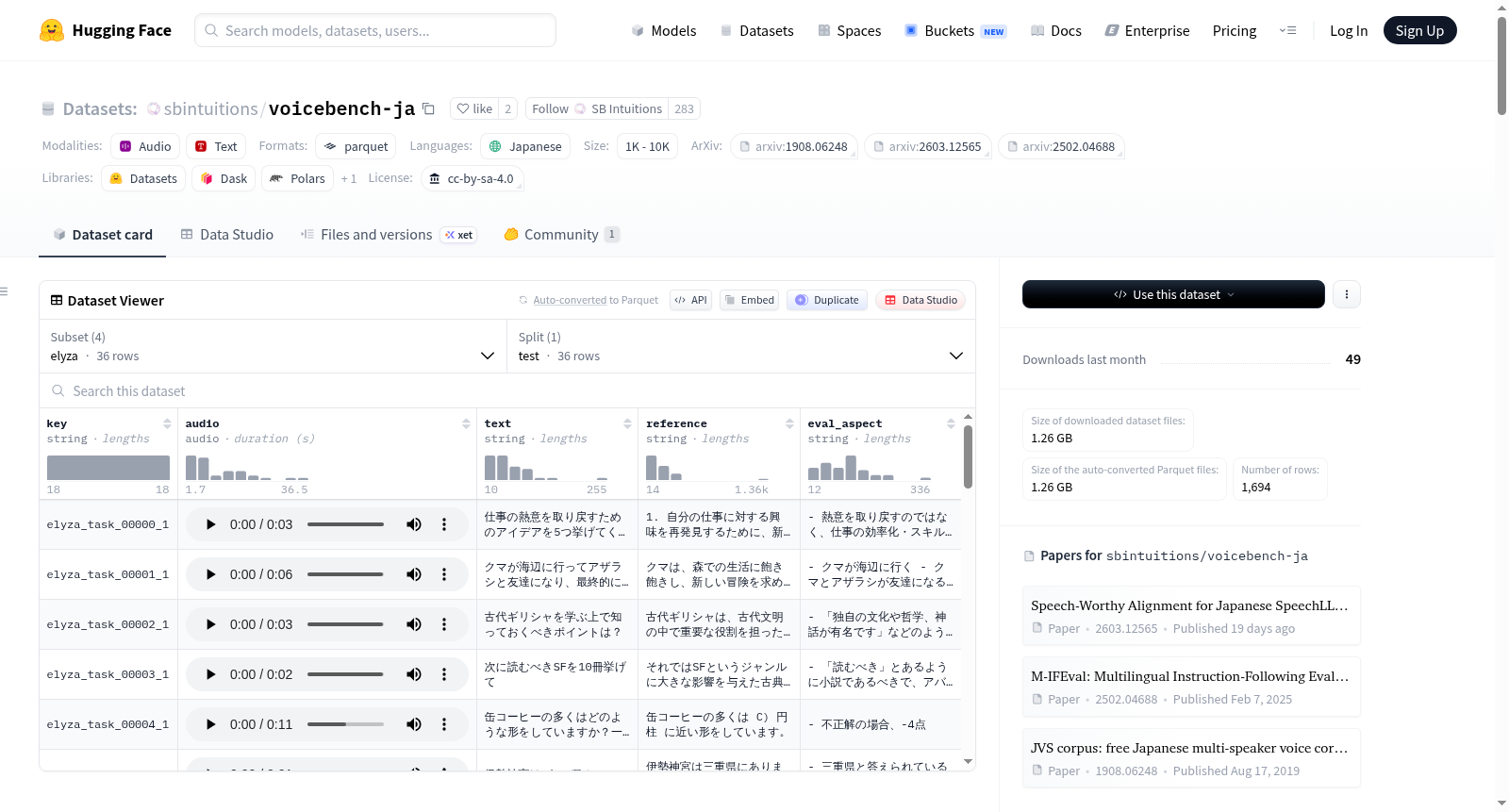
voicebench-ja
收藏Hugging Face2026-03-30 更新2026-03-31 收录
下载链接:
https://huggingface.co/datasets/sbintuitions/voicebench-ja
下载链接
链接失效反馈官方服务:
资源简介:
该数据集旨在定量评估语音语言模型在接收音频输入与文本输入时表现出的智能和推理能力差异。数据集由四个子集构成,这些子集基于三个文本基准(Elyza-tasks-100、M-IFEval和JamC-QA)的样本,并应用了语音合成技术。语音合成使用了SB Intuitions公司内部的TTS模型,并以JVS语料库的语音作为提示。数据集包含以下子集:
1. Elyza:从elyza-tasks-100中选取36个样本,经过文本修正和语音合成。
2. Spoken-Elyza:调整Elyza子集的参考文本,去除不适合语音传递的标记和符号,并进行人工听力验证,最终保留34个样本。
3. M-IFEval:将M-IFEval的输入提示转换为可朗读形式并合成语音,保留原始评估约束。
4. JamC-QA:对JamC-QA的多选题样本添加标签并合成语音,从2309个样本中筛选出1452个适合评估的样本。
数据集文本部分采用CC BY-SA 4.0许可,语音数据禁止商用和再分发。
This dataset aims to quantitatively evaluate the differences in intelligence and reasoning capabilities of speech language models when receiving audio inputs versus text inputs. The dataset comprises four subsets derived from samples of three text benchmarks (Elyza-tasks-100, M-IFEval, and JamC-QA) via speech synthesis technology. Speech synthesis was performed using an internal TTS model from SB Intuitions, with voices from the JVS corpus as prompts. The dataset includes the following subsets:
1. Elyza: 36 samples selected from Elyza-tasks-100, which underwent text correction and speech synthesis.
2. Spoken-Elyza: The reference texts of the Elyza subset were adjusted to remove markers and symbols unsuitable for oral transmission, followed by manual auditory verification, with 34 samples finally retained.
3. M-IFEval: The input prompts of M-IFEval were converted into orally readable forms and synthesized into speech, while the original evaluation constraints were preserved.
4. JamC-QA: Labels were added to the multiple-choice samples of JamC-QA, followed by speech synthesis; 1,452 eligible samples for evaluation were screened from the original 2,309 samples.
The text portion of the dataset is licensed under CC BY-SA 4.0, while commercial use and redistribution of the audio data are prohibited.
提供机构:
SB Intuitions创建时间:
2026-03-30
搜集汇总
数据集介绍
构建方式
在语音语言模型评估领域,voicebench-ja数据集通过系统化方法构建,旨在量化分析语音与文本输入对模型智能与推理能力的影响。该数据集以三个成熟的文本基准——Elyza-tasks-100、M-IFEval和JamC-QA为基础,从中精选样本并转化为语音形式。具体而言,研究团队采用内部文本转语音模型,以JVS语料库的语音作为提示,将原始文本内容合成为音频数据。每个子集均经过针对性调整:例如,Spoken-Elyza通过大语言模型去除文本中不适合语音传达的标记符号,并经人工听觉验证确保可理解性;JamC-QA则从多选问答中筛选出适合语音评估的样本,并为选项添加语音标签。
使用方法
使用该数据集时,研究者可通过Hugging Face库加载指定子集,并利用多模态模型进行端到端评估。典型流程包括:加载音频数据并编码为base64格式,构建包含系统指令与用户音频输入的对话模板,通过如Qwen2.5-Omni等模型生成文本响应。评估阶段需配合flexeval框架,根据子集特性调用相应的指标文件进行自动化评分。例如,对于JamC-QA子集,模型需输出单一选项字母;对于Elyza子集,则需对比生成内容与参考文本。整个流程支持标准化结果格式化,便于后续分析与比较研究。
背景与挑战
背景概述
语音语言模型在音频与文本输入模态间的性能差异,是衡量模型跨模态理解能力的关键维度。VoiceBench-JA数据集由SB Intuitions等机构于2026年前后构建,旨在定量评估日语语音语言模型在处理音频输入时的智能与推理能力。该数据集通过对Elyza-tasks-100、M-IFEval及JamC-QA三个文本基准进行语音合成,生成了四个子集,涵盖了常识推理、指令遵循及多选问答等多种任务。其创建推动了日语语音大模型在跨模态对齐与评估方法学上的发展,为研究者提供了首个专注于日语语音指令理解的标准化评测基准。
当前挑战
该数据集致力于解决语音语言模型在跨模态理解中的核心挑战,即如何准确评估模型对音频指令的语义解析与推理能力,弥合文本与语音输入间的性能鸿沟。在构建过程中,研究者面临多重技术难题:需将原始文本提示转化为自然流畅的语音,同时保留其语义完整性与评估约束;针对口语对话场景,需剔除文本中的非语音友好元素(如标记符号),并通过人工听力验证确保音频的可理解性;此外,还需从海量样本中筛选出适合语音评估的高质量数据,确保基准的严谨性与代表性。
常用场景
经典使用场景
在语音语言模型的研究领域,voicebench-ja数据集主要用于评估模型在语音输入与文本输入模式下智能与推理能力的差异。该数据集通过将Elyza-tasks-100、M-IFEval和JamC-QA等文本基准转化为语音形式,构建了包含问答、指令遵循和对话适应性的多维度测试环境。研究人员借助这一数据集,能够系统性地衡量语音语言模型在理解口语指令、执行复杂推理以及生成符合语音交互特性的响应方面的性能,为模型优化提供了关键的基准参照。
解决学术问题
该数据集有效解决了语音语言模型评估中缺乏标准化日语语音基准的学术难题。传统评估多依赖于文本输入,难以捕捉语音模态特有的信息损失与理解偏差。voicebench-ja通过合成语音样本,量化了模型在跨模态理解上的差距,为研究语音与文本处理的一致性、指令遵循的鲁棒性以及模型在语音环境下的认知能力提供了实证基础。其构建促进了多模态语言理解理论的深化,推动了语音对齐与跨模态泛化等前沿方向的发展。
实际应用
在实际应用层面,voicebench-ja为开发高性能日语语音助手和智能对话系统提供了关键评估工具。企业可利用该数据集测试语音模型在真实场景中的表现,如客户服务中的多轮问答、教育领域的知识查询以及娱乐交互中的指令理解。通过评估模型在语音输入下的准确性与自然度,开发者能够优化系统设计,提升用户体验,推动语音技术在智能设备、车载系统和无障碍通信等领域的可靠部署与广泛应用。
数据集最近研究
最新研究方向
在语音语言模型领域,VoiceBench-JA数据集正推动着多模态智能评估的前沿探索。该数据集通过将文本基准转化为合成语音,专门用于量化分析语音输入与文本输入之间在推理能力上的差异。当前研究热点聚焦于如何提升语音语言模型在复杂指令遵循、常识推理以及日语特有文化知识问答上的表现,尤其是在语音模态下保持与文本模态相媲美的认知准确性。随着多模态大模型的快速发展,该数据集为评估模型在真实语音交互场景中的泛化能力提供了关键基准,其构建方法也启发了跨语言语音评估体系的建立,对推动具身智能和自然语音交互系统的进步具有深远意义。
以上内容由遇见数据集搜集并总结生成


