turkish_llm_finetune_set_4_topics
收藏Hugging Face2024-09-04 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/barathanasln/turkish_llm_finetune_set_4_topics
下载链接
链接失效反馈官方服务:
资源简介:
Turkish LLM Finetune Dataset是一个用于微调T3 AI土耳其LLM的问答数据集,由Barathan Aslan, Ömer Faruk Çelik, 和 Batuhan Kalem创建。该数据集专注于四个主题:农业、可持续性、土耳其教育系统和土耳其法律系统。数据集中的问答对是通过Gemini 1.5 Flash生成的,使用Gemini 1.5 Pro进行评分和质量评估。建议在微调时排除评分低于6的行。每个主题的数据集都提供了CSV格式,适用于微调T3 AI土耳其LLM和土耳其语的自然语言处理任务。
创建时间:
2024-09-04
原始信息汇总
Turkish LLM Finetune Dataset - 4 Topics
概述
- 数据集名称: Turkish LLM Finetune Dataset
- 数据集类型: Question Answering
- 语言: 土耳其语
- 许可证: Apache 2.0
- 标签:
- 土耳其语
- 文本
- LLM
- 微调
- 问答
- 自然语言处理
- 法律
- 教育
- 可持续性
- 农业
贡献者
- Barathan Aslan
- Batuhan Kalem
- Ömer Faruk Çelik
数据集创建
- 问题-答案对使用Gemini 1.5 Flash通过多链提示生成。
- 评分和质量评估使用Gemini 1.5 Pro进行。
- 建议: 为了获得最佳微调结果,建议排除评分值低于6的行。
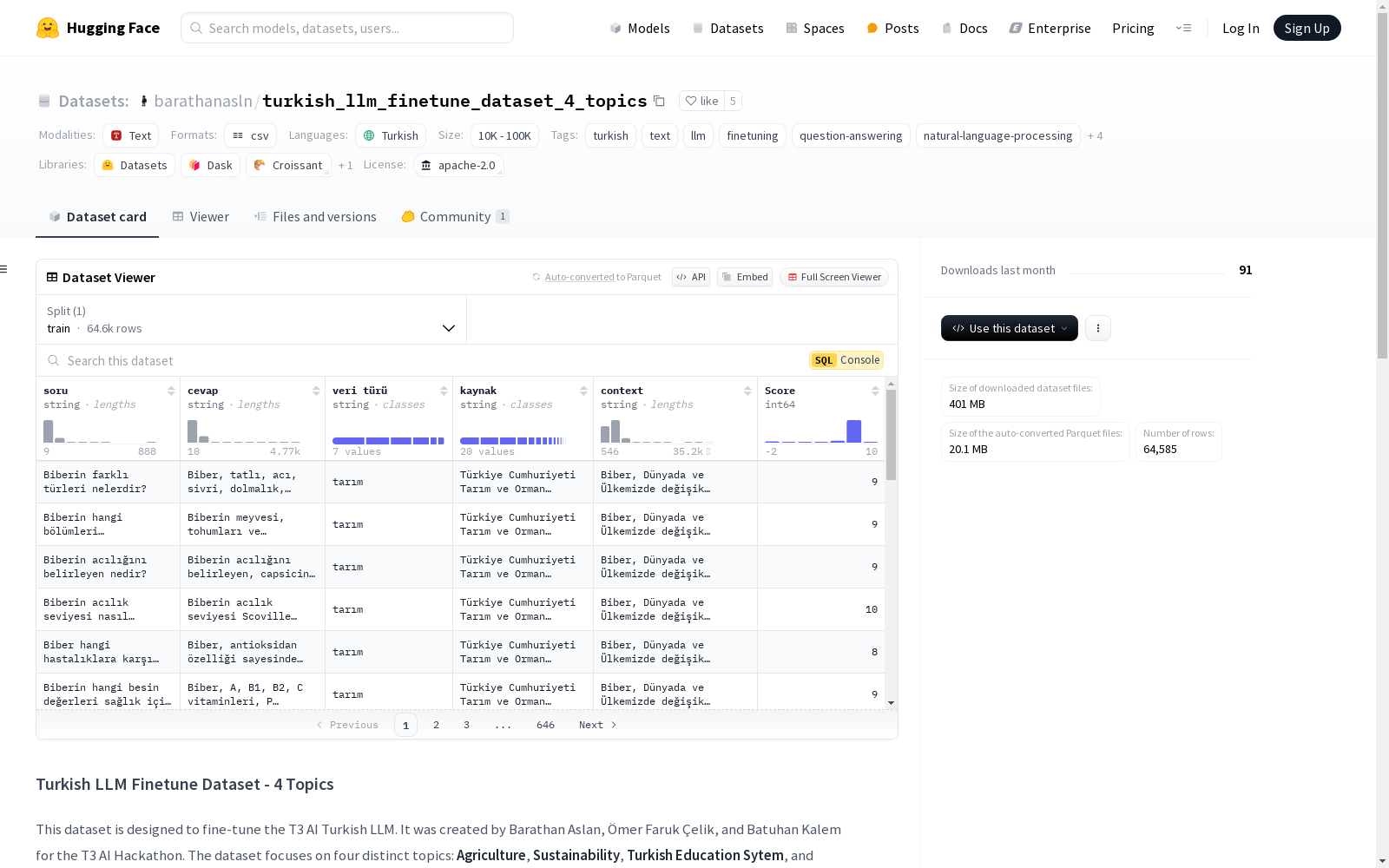
数据集概览
| 数据集 | 来源 |
|---|---|
| Agriculture Dataset | Türkiye Cumhuriyeti Tarım ve Orman Bakanlığı <br>Tarım ve Orman Bakanlığı <br>T.C. TARIM VE ORMAN BAKANLIĞI - Bitki Sağlığında Yayınlar |
| Sustainability Dataset | Sürdürülebilir Kalkınma Platformu <br>Wikipedia: Sürdürülebilirlik |
| Turkish Education Dataset | OGM Konu Özetleri <br> OGM Materyel <br> Wikihow <br> SMUS: Supporting Child Exams <br> DPS Mathura Road <br> MEB Türk Milli Eğitim Sistemi <br> TUSEB - Eğitim Sistemi <br> Anadolu Ajansı <br> MEB YKS Öncesi Öneriler <br> Türkiye Yüzyılı Maarif Modeli <br> TÜRK EĞİTİM SİSTEMİ VE ORTAÖĞRETİM <br>Wikipedia: Türkiye'de Eğitim |
| Turkish Law Dataset | Türkiye Cumhuriyeti Anayasası <br> Bilgi Edinme Kanunu <br> Ceza Muhakemesi Kanunu <br> Türk Medeni Kanunu <br> Türk Bayrağı Tüzüğü <br> Türk Borçlar Kanunu <br> Türk Ceza Kanunu <br> Türkiye Cumhuriyeti İş Kanunu |
使用方法
- 每个数据集以CSV格式提供,可用于:
- 微调T3 AI土耳其语LLM。
- 专注于土耳其语的自然语言处理任务。
- 数据集根据内容的质量和相关性进行评分,评分越高表示质量越好。
- -1表示“安全”类别。
- -2表示未评分的行。
搜集汇总
数据集介绍
构建方式
该数据集由Barathan Aslan、Ömer Faruk Çelik和Batuhan Kalem为T3 AI Hackathon创建,旨在微调T3 AI土耳其语言模型。数据集的构建过程采用了Gemini 1.5 Flash生成问答对,并通过Gemini 1.5 Pro进行评分和质量评估。数据集涵盖了农业、可持续性、土耳其教育系统和土耳其法律系统四个主题,确保了内容的多样性和专业性。
使用方法
该数据集以CSV格式提供,适用于微调T3 AI土耳其语言模型以及进行土耳其语的自然语言处理任务。用户可以根据评分筛选高质量的数据进行模型训练,确保模型的性能。数据集中的-1表示“安全”类别,-2表示未评分的样本,用户在使用时需注意这些特殊标记。
背景与挑战
背景概述
Turkish LLM Finetune Dataset是由Barathan Aslan、Ömer Faruk Çelik和Batuhan Kalem在T3 AI Hackathon期间创建的,旨在为土耳其语的大型语言模型(LLM)提供微调数据。该数据集涵盖了四个核心主题:农业、可持续性、土耳其教育系统和土耳其法律系统。这些主题的选择反映了土耳其社会中的重要领域,尤其是农业和法律系统在土耳其经济和社会结构中的关键作用。数据集的创建时间可追溯至T3 AI Hackathon期间,具体时间未明确提及,但其发布标志着土耳其语自然语言处理领域的一个重要进展。通过使用Gemini 1.5 Flash和Gemini 1.5 Pro生成和评估问答对,该数据集为土耳其语LLM的微调提供了高质量的资源。
当前挑战
Turkish LLM Finetune Dataset在构建过程中面临多重挑战。首先,数据集的生成依赖于Gemini 1.5 Flash的多轮提示链,这要求研究人员在生成问答对时确保内容的多样性和准确性。其次,数据质量评估通过Gemini 1.5 Pro进行,评分低于6的样本被建议排除,这一过程增加了数据筛选的复杂性。此外,数据集涵盖的四个主题(农业、可持续性、教育、法律)涉及大量专业术语和复杂的领域知识,这对问答对的生成和评估提出了更高的要求。最后,土耳其语作为一种形态丰富的语言,其语法结构和词汇复杂性也为数据集的构建带来了额外的挑战,尤其是在确保问答对的流畅性和语义准确性方面。
常用场景
经典使用场景
在自然语言处理领域,turkish_llm_finetune_set_4_topics数据集主要用于微调土耳其语的大型语言模型(LLM)。该数据集涵盖了农业、可持续性、土耳其教育系统和土耳其法律系统四个主题,为研究人员提供了丰富的问答对,帮助模型更好地理解和生成土耳其语文本。通过使用该数据集,研究人员可以在特定领域内提升模型的性能,尤其是在处理复杂和专业性较强的土耳其语文本时。
解决学术问题
该数据集解决了土耳其语自然语言处理中的多个学术问题,特别是在领域特定文本的理解和生成方面。通过提供高质量的问答对,数据集帮助研究人员克服了土耳其语语料稀缺的挑战,尤其是在农业、法律和教育等专业领域。此外,数据集的质量评分机制确保了数据的可靠性,为模型微调提供了坚实的基础,推动了土耳其语NLP研究的发展。
实际应用
在实际应用中,turkish_llm_finetune_set_4_topics数据集被广泛用于开发土耳其语的智能问答系统、法律咨询工具和教育辅助平台。例如,在法律领域,该数据集可以帮助构建自动化的法律咨询系统,为用户提供快速且准确的法律信息。在教育领域,数据集可以用于开发智能辅导系统,帮助学生更好地理解复杂的教育内容。这些应用不仅提高了信息获取的效率,还增强了用户体验。
数据集最近研究
最新研究方向
在自然语言处理领域,土耳其语的大型语言模型(LLM)微调数据集正逐渐成为研究热点。turkish_llm_finetune_set_4_topics数据集专注于农业、可持续性、土耳其教育系统和土耳其法律系统四个主题,为土耳其语的自然语言处理任务提供了丰富的语料资源。近年来,随着全球对多语言模型需求的增加,土耳其语作为重要的区域性语言,其语言模型的优化和微调成为学术界和工业界关注的焦点。该数据集的推出不仅填补了土耳其语在特定领域语料库的空白,还为相关领域的研究提供了新的数据支持。特别是在法律和教育领域,数据集的精细标注和高质量内容为模型的理解和生成能力提供了坚实基础。未来,该数据集有望在跨语言迁移学习、多任务学习等前沿方向发挥重要作用,推动土耳其语自然语言处理技术的进一步发展。
以上内容由遇见数据集搜集并总结生成


