NuCLS
收藏arXiv2021-02-18 更新2024-06-21 收录
下载链接:
https://sites.google.com/view/nucls
下载链接
链接失效反馈官方服务:
资源简介:
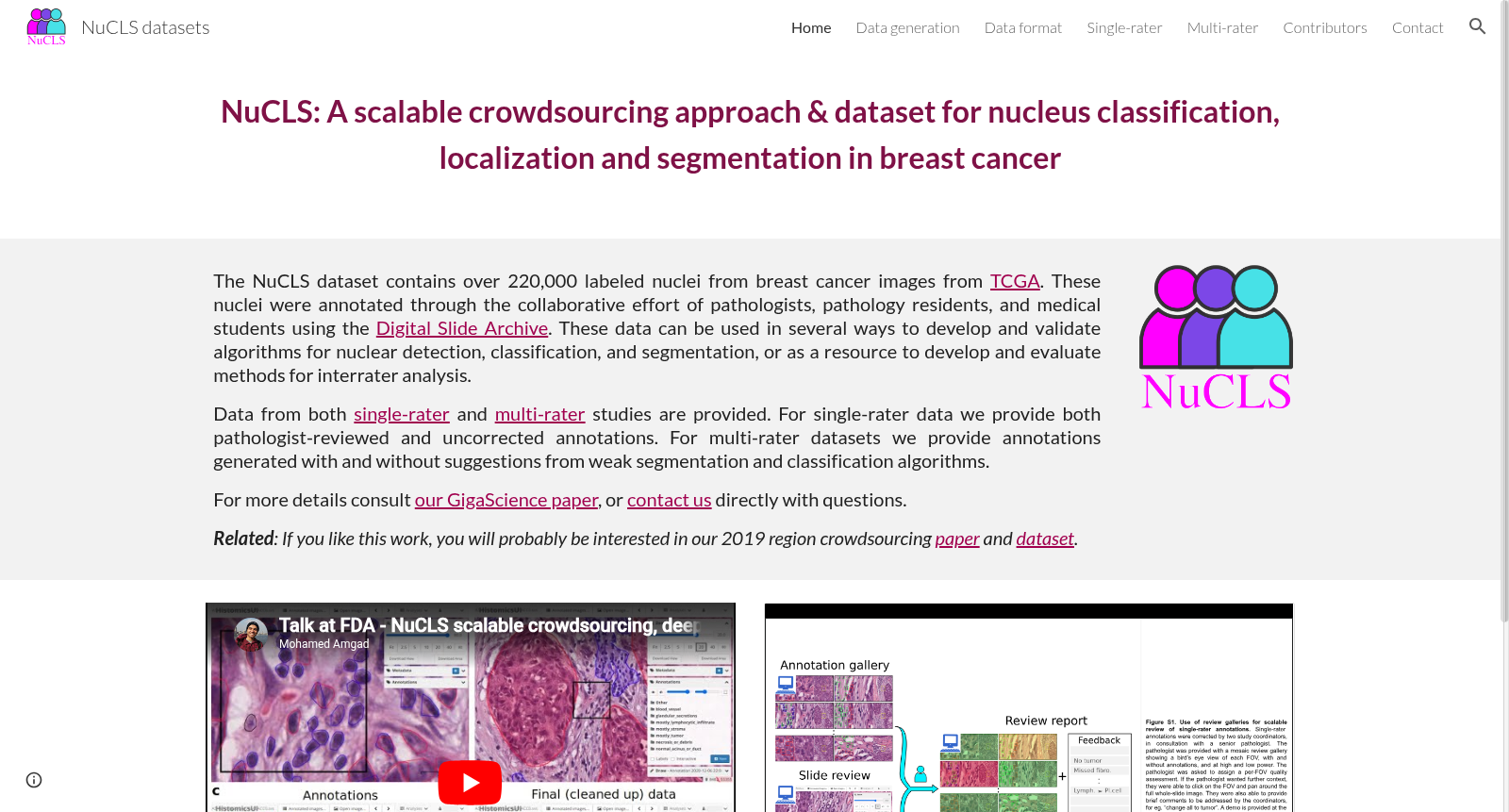
NuCLS数据集是由美国芝加哥西北大学的一个研究团队开发的,通过众包方式,利用医学生和病理学家的参与,对乳腺癌中的超过22万个细胞核进行了标注。该数据集不仅包含了单个注释者的标注,还包括了多个注释者的标注,其中算法建议被用来提高标注的准确性和效率。数据集的目的是为了训练和验证机器学习模型,特别是在计算病理学领域。
The NuCLS dataset was developed by a research team from Northwestern University in Chicago, United States. It was built via crowdsourcing, with the participation of medical students and pathologists, to annotate more than 220,000 cell nuclei in breast cancer tissues. The dataset includes annotations from both individual annotators and multiple annotators, and algorithmic suggestions were utilized to improve annotation accuracy and efficiency. The purpose of this dataset is to train and validate machine learning models, particularly in the field of computational pathology.
提供机构:
Northwestern University, Chicago, IL, USA
创建时间:
2021-02-18
搜集汇总
数据集介绍
构建方式
在计算病理学领域,高质量标注数据的稀缺性长期制约着深度学习模型的进展。NuCLS数据集通过一种创新的众包策略,系统性地构建了大规模细胞核标注数据。该数据集采集自癌症基因组图谱(TCGA)中125例三阴性乳腺癌患者的全切片图像,涵盖18个机构来源。构建过程采用结构化众包流程,招募了32名非病理学家(如医学生)和7名病理学家参与标注。标注任务包括细胞核的定位、分类与分割,通过基于Web的HistomicsUI平台集中管理。关键创新在于引入算法辅助标注:首先利用图像处理启发式方法生成初始的噪声分割建议(自举建议),进而使用MaskRCNN模型进行精细化处理,形成高质量的建议边界。参与者通过点击确认准确建议或绘制边界框的方式完成标注,最终形成了包含22万余个标注的混合数据集,其中单标注者数据集经过病理学家监督修正,多标注者数据集则用于评估标注者间一致性与算法建议的效用。
使用方法
NuCLS数据集为细胞核检测、分割与分类算法的开发与评估提供了多功能平台。研究者可访问公开数据仓库获取标注数据与对应全切片图像。数据集支持多种机器学习任务:对于模型训练,可主要利用经过修正的单标注者数据集,该数据集提供了经过病理学家验证的高质量标注;对于算法评估与比较,多标注者数据集及其推断出的病理学家真值可作为可靠的基准测试集。数据使用时可遵循内部-外部交叉验证方案,按医院机构划分训练与测试集,以更好地评估模型的外部泛化能力。针对细胞核检测与分割任务,可利用数据集中丰富的边界信息训练如MaskRCNN等实例分割模型;对于分类任务,则可利用精细的细胞核类别标签。此外,数据集配套的NuCLS改进模型代码与决策树近似学习嵌入技术为可解释性研究提供了工具。研究者还可利用多标注者数据研究众包标注质量控制、标注者间一致性分析以及半监督学习策略,推动计算病理学标注工作流的创新发展。
背景与挑战
背景概述
NuCLS数据集由西北大学病理学系等多家机构的研究团队于近年创建,旨在应对计算病理学中大规模标注数据稀缺的核心挑战。该数据集聚焦于乳腺癌组织切片中细胞核的分类、定位与分割任务,通过创新的众包策略整合了医学学生与病理学专家的标注能力,最终汇集了超过22万个细胞核标注。其核心研究在于探索如何以可扩展的方式生成高质量标注数据,从而推动可解释性深度学习模型在肿瘤微环境分析、形态学生物标志物发现等领域的应用,为计算病理学的发展提供了重要的数据基础与方法学参考。
当前挑战
NuCLS数据集致力于解决计算病理学中细胞核精细分析的多重挑战,包括细胞核在复杂组织背景下的准确检测、形态相似细胞类别的区分,以及密集或重叠细胞核的实例分割。构建过程中的挑战尤为显著:首先,依赖病理专家进行大规模标注面临时间与人力成本高昂的瓶颈;其次,众包标注中非专家与专家间的一致性保障、标注质量控制成为关键难题;此外,如何有效融合算法生成的初始建议与人工标注,以平衡效率与精度,亦是数据集构建中需要克服的技术障碍。
常用场景
经典使用场景
在计算病理学领域,NuCLS数据集为核检测、分类与分割任务提供了大规模标注基准。该数据集通过众包策略整合了医学学生与病理学专家的标注,覆盖了超过22万个细胞核注释,广泛应用于训练和验证深度学习模型,特别是在乳腺癌组织切片中细胞核的精准定位与形态分析。其经典使用场景包括开发基于卷积神经网络的细胞核检测算法,如改进的MaskRCNN架构,以及评估模型在组织微环境分析中的泛化能力。
解决学术问题
NuCLS数据集有效缓解了计算病理学中标注数据稀缺的核心瓶颈。通过引入非病理学专家的众包标注与算法辅助建议,该数据集以较低成本生成了高质量的细胞核边界与分类标签,解决了传统病理学标注依赖专家耗时手工勾画的难题。其意义在于为可解释性机器学习模型提供了训练基础,促进了肿瘤微环境的高分辨率空间映射研究,并推动了组织病理学与基因组学关联的发现,为癌症生物标志物的计算驱动探索铺平了道路。
实际应用
在实际临床与科研场景中,NuCLS数据集支持自动化病理图像分析系统的开发。基于该数据集训练的模型能够辅助病理医生快速识别乳腺癌切片中的肿瘤细胞、基质细胞和肿瘤浸润淋巴细胞,提升诊断效率与一致性。此外,数据集衍生的分割与分类工具可集成到数字病理平台中,用于大规模癌症筛查、预后评估以及治疗反应监测,为精准医疗提供可靠的计算支持。
数据集最近研究
最新研究方向
在计算病理学领域,NuCLS数据集正推动着细胞核检测与分类的前沿研究。该数据集通过众包策略结合弱监督算法,实现了大规模细胞核标注的高效生成,为深度学习模型提供了丰富的训练资源。当前研究聚焦于改进MaskRCNN架构,使其适应细胞核检测任务,并利用混合标注数据提升模型泛化能力。同时,决策树近似学习嵌入技术(DTALE)的引入,增强了模型的可解释性,有助于克服临床应用的信任壁垒。这些进展不仅促进了肿瘤微环境的高分辨率空间映射,还为发现新的组织病理学生物标志物奠定了坚实基础。
相关研究论文
- 1NuCLS: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentationNorthwestern University, Chicago, IL, USA · 2021年
以上内容由遇见数据集搜集并总结生成


