xsum-unlearning-mia
收藏Hugging Face2025-12-21 更新2025-12-22 收录
下载链接:
https://huggingface.co/datasets/h0ssn/xsum-unlearning-mia
下载链接
链接失效反馈官方服务:
资源简介:
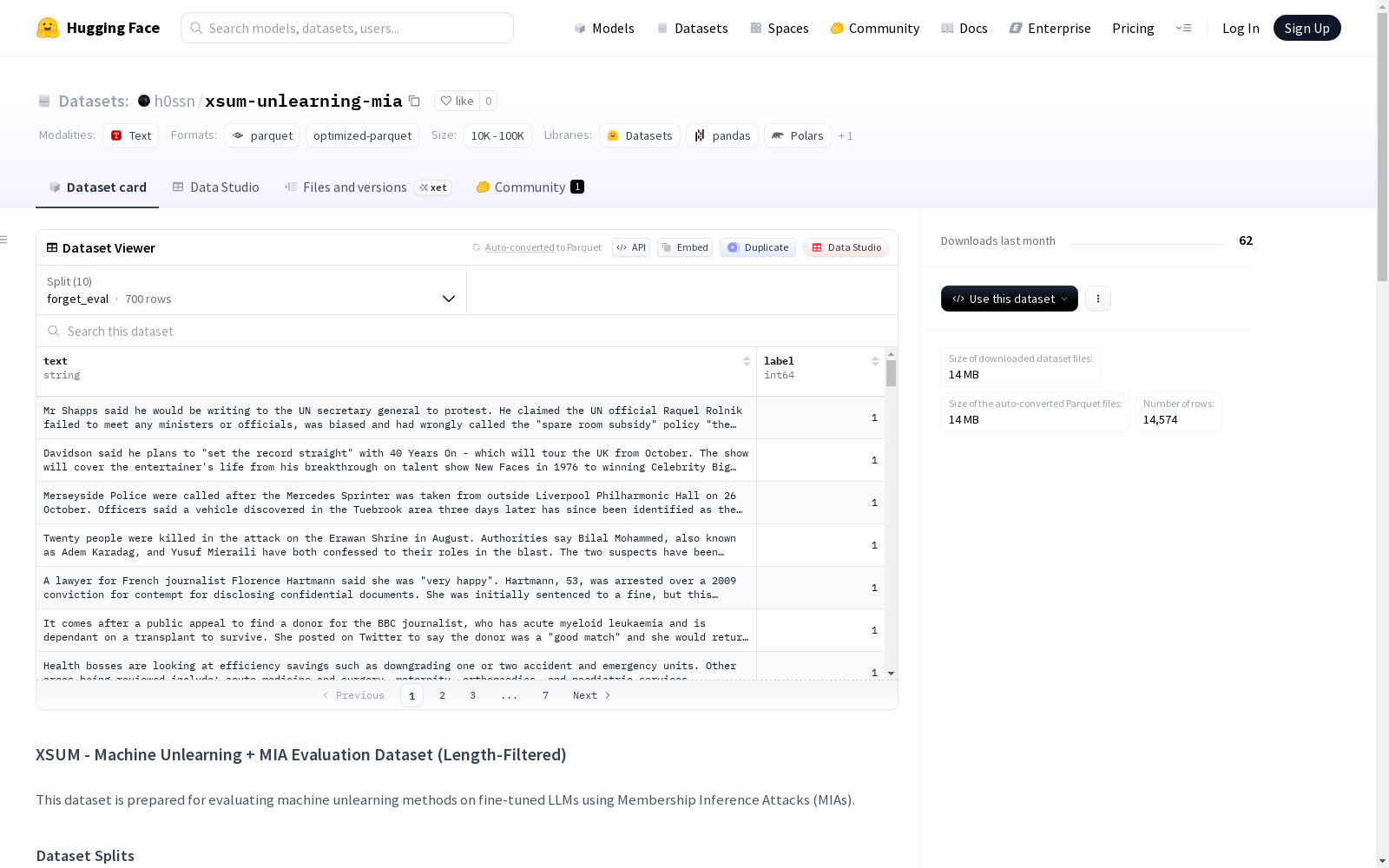
该数据集是为评估在微调的大型语言模型(LLMs)上使用成员推理攻击(MIAs)的机器遗忘方法而准备的。数据集包含训练集和评估集,训练集分为保留集(9,000个样本)和遗忘集(1,000个样本),评估集则根据摘要长度分为64、96和128 tokens的不同版本。每个评估数据集(最多700个样本)包含来自微调数据集子集的成员样本和来自原始测试集的非成员样本。数据集经过长度过滤,以匹配特定的token长度(±10 tokens的容差),防止模型使用序列长度作为成员推理的信号。该数据集适用于机器遗忘、MIA评估、隐私研究和长度控制的MIA评估。
This dataset is designed to evaluate machine forgetting methods that employ Membership Inference Attacks (MIAs) on fine-tuned Large Language Models (LLMs). The dataset consists of a training set and an evaluation set. The training set is split into a retained subset (9,000 samples) and a forgotten subset (1,000 samples). The evaluation set is divided into variants with 64, 96, and 128 tokens based on summary length. Each evaluation dataset, containing up to 700 samples, includes member samples from subsets of the fine-tuned dataset and non-member samples from the original test set. The dataset has undergone length filtering to match specific token lengths with a tolerance of ±10 tokens, preventing the model from using sequence length as a signal for membership inference. This dataset is applicable to machine forgetting, MIA evaluation, privacy research, and length-controlled MIA evaluation.
创建时间:
2025-12-11
原始信息汇总
XSUM - Machine Unlearning + MIA Evaluation Dataset (Length-Filtered) 数据集概述
数据集基本信息
- 数据集名称:XSUM - Machine Unlearning + MIA Evaluation Dataset (Length-Filtered)
- 主要用途:用于评估在微调大语言模型上应用机器遗忘方法的效果,并使用成员推理攻击进行评测。
- 核心特征:
text:字符串类型。label:int64类型。
数据集划分
训练集(用于机器遗忘)
retain_set:包含9,000个样本,代表在遗忘过程中需要保留的数据。forget_set:包含1,000个样本,代表需要被遗忘的数据。
评估集(用于成员推理攻击)- 经过长度过滤
评估集根据文本长度分为三个变体,每个变体包含对应的retain_eval和forget_eval子集:
- 64个词元:短摘要版本(约64±10个词元)。
retain_eval_64forget_eval_64
- 96个词元:中等摘要版本(约96±10个词元)。
retain_eval_96forget_eval_96
- 128个词元:长摘要版本(约128±10个词元),为推荐使用的版本。
retain_eval_128forget_eval_128
评估集结构
每个评估数据集(最多700个样本)结构如下:
| 索引范围 | 数据来源 | 成员状态 | 标签 |
|---|---|---|---|
| 0-349 | 微调数据集的子集 | 成员 | 1 |
| 350-699 | 原始测试集划分 | 非成员 | 0 |
注意:实际样本数量可能因符合长度标准的样本可用性而有所不同。
关键处理:长度过滤
- 所有评估集划分都经过过滤,以匹配特定的词元长度(允许±10个词元的容差)。
- 此长度匹配旨在防止模型使用序列长度作为成员推理的信号,该方法遵循Win-k MIA论文的方法论。
主要应用场景
- 机器遗忘:训练模型以“遗忘”
forget_set,同时在retain_set上保持性能。 - 成员推理攻击评估:使用评估集划分来测量遗忘前后的成员信息泄露。
- 隐私研究:研究遗忘方法在保护数据隐私方面的有效性。
- 长度受控的成员推理攻击:在没有长度混淆因素的情况下评估成员推理攻击。
使用许可
请参考原始数据集的许可协议。
引用要求
如果使用此数据集,请引用建立了长度过滤方法论的Win-k MIA论文。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,针对大语言模型隐私保护与遗忘机制的研究日益深入,XSUM遗忘与成员推理评估数据集应运而生。该数据集基于XSUM摘要数据集构建,通过精细划分形成保留集与遗忘集,分别包含九千条与一千条样本,专门用于评估模型在遗忘特定数据后的性能变化。评估部分进一步依据摘要长度进行过滤,生成了六十四、九十六及一百二十八令牌三种长度的变体,每个评估集均包含来自微调子集的成员样本与原始测试集的非成员样本,确保了样本长度的一致性,有效消除了序列长度对成员推理的潜在干扰。
特点
本数据集的核心特点在于其精心设计的长度过滤机制与结构化评估框架。所有评估样本均被严格控制在目标令牌长度的正负十个令牌容差范围内,这一设计遵循了相关研究的方法论,旨在排除长度特征对成员推理攻击的混淆影响。数据集明确区分了用于遗忘训练的保留集、遗忘集以及用于成员推理评估的多长度变体集,其中一百二十八令牌版本被推荐使用。评估集以均衡方式混合了成员与非成员样本,并提供了清晰的索引范围标识,为量化模型隐私泄露程度提供了可靠且标准化的基准。
使用方法
研究人员可利用该数据集系统性地开展机器遗忘与隐私评估实验。通过加载数据集,可便捷地访问训练所需的保留集与遗忘集,以实施遗忘算法。随后,可调用不同长度的评估集,对模型在遗忘前后执行成员推理攻击,从而精确测量遗忘操作在保护数据隐私方面的有效性。该数据集尤其适用于探究在控制文本长度变量的条件下,各种遗忘方法对缓解成员推理风险的实际效能,为模型隐私保护研究提供了关键的工具支持。
背景与挑战
背景概述
在人工智能与数据隐私研究领域,机器遗忘作为一项新兴技术,旨在使大型语言模型能够有选择性地遗忘特定训练数据,以应对隐私法规与伦理要求。数据集xsum-unlearning-mia由研究团队于近期构建,专注于评估基于微调大型语言模型的机器遗忘方法,并采用成员推理攻击作为核心评估手段。该数据集基于XSum摘要数据集,通过精心设计的保留集与遗忘集划分,为量化遗忘效果与隐私泄露风险提供了标准化基准,推动了可验证遗忘机制与模型隐私保护的前沿探索。
当前挑战
该数据集致力于解决机器遗忘领域中的评估难题,即如何准确衡量模型在遗忘特定数据后是否仍存在隐私泄露风险。主要挑战在于设计无偏的评估框架,避免模型利用序列长度等无关特征进行成员推断,从而确保评估结果真实反映遗忘有效性。在构建过程中,挑战集中于对原始文本进行精确的长度过滤与匹配,以消除长度混杂因素,同时需平衡不同长度变体的样本可用性与数据代表性,这要求严格的数据处理流程与质量控制。
常用场景
经典使用场景
在机器遗忘与隐私保护研究领域,该数据集为评估大型语言模型的遗忘效能提供了标准化基准。研究者通常利用其精心划分的保留集与遗忘集,对微调后的模型实施遗忘操作,随后通过成员推理攻击评估遗忘前后模型的隐私泄露程度。数据集特别引入了基于文本长度的过滤机制,有效消除了序列长度对成员推断的干扰,从而确保评估结果聚焦于模型对特定数据的记忆消除能力,为机器遗忘算法的公平比较奠定了坚实基础。
解决学术问题
该数据集主要致力于解决机器遗忘研究中两个核心学术问题:一是如何量化评估模型对特定数据的遗忘效果,二是如何精准衡量遗忘操作对模型隐私保护水平的提升。通过构建保留集、遗忘集及对应的成员与非成员评估子集,数据集使得研究者能够系统分析遗忘算法在消除目标数据记忆的同时,是否保持了模型在其余数据上的性能,并有效阻断了成员推理攻击。这为理解模型记忆机制、发展可验证的遗忘方法提供了关键实验平台,推动了可信人工智能与数据隐私领域的前沿探索。
衍生相关工作
围绕该数据集,已衍生出一系列聚焦机器遗忘与隐私评估的经典研究工作。其中,Win-k MIA论文提出的长度过滤方法论直接启发了数据集的构建,为控制混淆变量、提升成员推理攻击的鲁棒性设立了新标准。后续研究在此基础上,进一步探索了不同遗忘算法(如梯度修正、模型修剪)在该数据集上的效能对比,以及遗忘操作对模型泛化能力的影响。这些工作共同深化了对神经网络记忆机制的理解,并推动了更高效、可证明的遗忘算法的发展,形成了机器遗忘领域一个活跃的研究脉络。
以上内容由遇见数据集搜集并总结生成


