FACE4FAIRSHIFTS
收藏arXiv2025-08-31 更新2025-11-25 收录
下载链接:
https://meviuslab.github.io/Face4FairShifts/
下载链接
链接失效反馈官方服务:
资源简介:
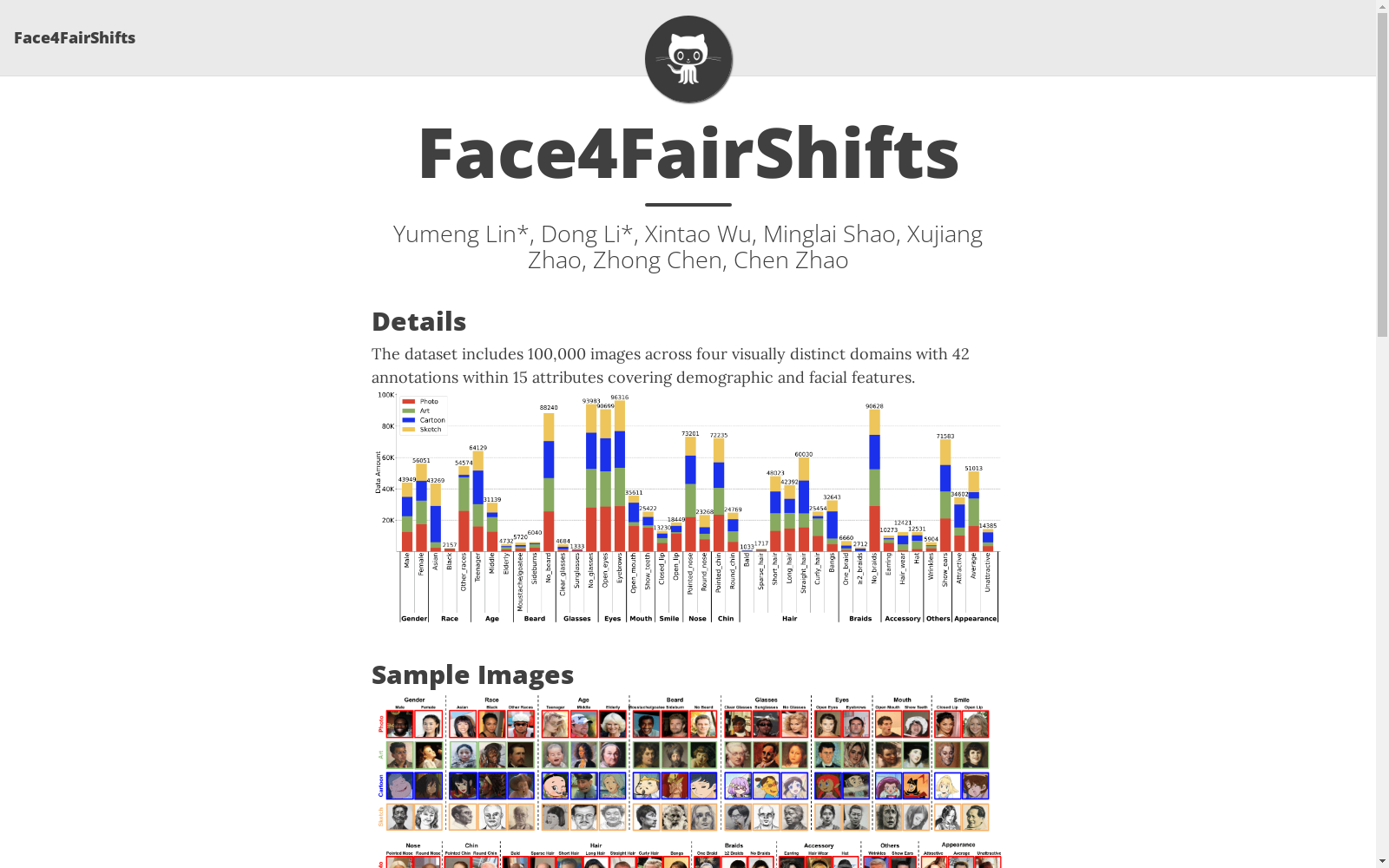
FACE4FAIRSHIFTS是一个大规模的人脸图像基准数据集,旨在系统地评估公平性学习领域内的公平性和鲁棒性。该数据集包含来自四个视觉上不同的领域的10万张图像,其中包括42个标注,涵盖了15个属性,覆盖了人口统计和面部特征。数据集的构建过程涉及对现有数据集的筛选和补充,并采用了人工标注和专门的质量控制团队来确保标注的高质量。FACE4FAIRSHIFTS为公平性和鲁棒性学习领域提供了一个全面的测试平台,有助于推动公平和可靠的人工智能系统的发展。
FACE4FAIRSHIFTS is a large-scale facial image benchmark dataset aimed at systematically evaluating fairness and robustness in the field of fairness-aware learning. This dataset contains 100,000 images from four visually distinct domains, with 42 annotation labels covering 15 attributes spanning demographic and facial features. The dataset construction process involves screening and supplementing existing datasets, and adopts manual annotation and a dedicated quality control team to ensure high-quality annotations. FACE4FAIRSHIFTS provides a comprehensive testbed for fairness and robustness learning, which helps advance the development of fair and reliable artificial intelligence systems.
提供机构:
天津大学新媒体与传播学院、贝勒大学计算机科学系、阿肯色大学电气工程与计算机科学系、NEC实验室美洲、南伊利诺伊大学计算机学院
创建时间:
2025-08-31
搜集汇总
数据集介绍
构建方式
在计算机视觉与公平机器学习交叉领域,构建具有自然分布偏移的数据集对推动算法鲁棒性研究至关重要。FACE4FAIRSHIFTS通过整合现有公开数据集与网络爬取图像的系统化流程,构建了涵盖照片、艺术、卡通和素描四个视觉域的大规模人脸图像基准。具体采用两阶段策略:首先筛选CELEBA、METFACES等权威数据集中的合格样本,再通过Python爬虫从谷歌等搜索引擎补充艺术与素描域数据,最终经YOLOv5人物检测与人工裁剪确保图像质量与一致性。该过程共处理10万张图像,实现了跨域协变量偏移的自然呈现。
使用方法
作为公平机器学习研究的基准工具,该数据集支持四类核心实验范式。在公平性学习中,可将全数据集按8:2比例划分训练测试集,以年龄为预测目标评估模型在不同敏感属性下的公平性指标。在域泛化任务中,采用留一域验证策略,训练时隐藏目标域数据以测试模型跨域泛化能力。对于分布外检测,可分别构建协变量偏移与语义偏移场景,通过能量分数或熵值阈值区分分布内外样本。在公平性域泛化实验中,需同步优化预测精度与跨域公平性,使用对抗训练或元学习等方法学习域不变公平表征。所有实验均建议重复三次以确保结果稳定性。
背景与挑战
背景概述
FACE4FAIRSHIFTS数据集于2025年由天津大学、贝勒大学、阿肯色大学等机构联合发布,旨在系统评估机器学习模型在视觉域偏移下的公平性与鲁棒性。该数据集涵盖10万张人脸图像,跨越照片、艺术、卡通和素描四个视觉域,包含15类属性的42种标注,覆盖人口统计特征与面部细节。其核心研究聚焦于公平感知的域泛化问题,通过自然存在的协变量偏移和相关性偏移,为开发公平可靠的人工智能系统提供了标准化测试平台。
当前挑战
该数据集针对人脸识别领域在域偏移下公平性难以保障的痛点,需解决模型在未知目标域中因协变量偏移和敏感属性相关性变化导致的性能退化与偏见放大问题。构建过程中面临多重挑战:需从现有数据集与网络爬取图像中整合多域数据并保持视觉一致性;通过66名标注者完成超1260万次标注实例,需设计多人交叉验证与质量控制机制以应对标注主观性与规模化管理难题;同时需确保各域间统计分布差异显著且符合现实场景的偏移模式。
常用场景
经典使用场景
在计算机视觉与机器学习领域,FACE4FAIRSHIFTS数据集为研究分布偏移下的公平性学习提供了标准化评估平台。该数据集通过涵盖照片、艺术画作、卡通和素描四个视觉域,系统性地构建了具有显著协变量偏移的测试环境。研究人员通常采用留一域验证方法,在三个域上训练模型并在剩余域上评估泛化性能,从而模拟现实世界中模型部署时面临的跨域分布变化挑战。这种评估范式能够有效揭示模型在未知数据分布下的公平性表现与鲁棒性局限。
解决学术问题
该数据集主要解决了机器学习中公平性外分布泛化这一核心学术难题。传统公平性研究往往假设训练与测试数据同分布,而FACE4FAIRSHIFTS通过自然存在的视觉域差异与敏感属性关联变化,揭示了协变量偏移与相关性偏移同时存在时的公平性退化现象。其实验结果表明,现有公平性算法在跨域场景中普遍存在性能下降,这为推动开发同时应对分布偏移与公平性约束的新型算法提供了理论依据与实践验证平台,显著促进了公平机器学习理论体系的完善。
实际应用
在现实应用层面,该数据集为开发公平可靠的生物识别系统提供了重要支撑。人脸识别技术在安防监控、金融支付等领域的广泛应用中,经常面临艺术滤镜、卡通化处理等风格转换带来的域偏移问题。通过在该数据集上的严格测试,开发者能够评估模型对不同种族、性别群体在多样化视觉表征下的识别公平性,有效预防如素描图像中特定族裔识别率显著下降等实际偏差问题,为构建包容性人工智能系统提供关键质量保障。
数据集最近研究
最新研究方向
在计算机视觉与机器学习领域,FACE4FAIRSHIFTS数据集正推动公平性与鲁棒性研究的深度整合。该数据集通过涵盖照片、艺术、卡通和素描四个视觉域,系统模拟了真实世界中的协变量偏移与相关性偏移,为公平感知的域泛化研究提供了关键基准。前沿研究聚焦于开发能够同时应对分布偏移与敏感属性偏差的算法,例如通过对抗性学习与不变表示建模来提升模型在未知域中的公平性。这一方向与当前人工智能伦理治理的热点议题紧密相连,尤其在面部识别技术的公平部署与监管框架构建中具有深远影响,为构建可信赖的人工智能系统奠定了实证基础。
相关研究论文
- 1通过天津大学新媒体与传播学院、贝勒大学计算机科学系、阿肯色大学电气工程与计算机科学系、NEC实验室美洲、南伊利诺伊大学计算机学院 · 2025年
以上内容由遇见数据集搜集并总结生成


