WildChat-4.8M
收藏Hugging Face2025-11-16 更新2025-11-17 收录
下载链接:
https://huggingface.co/datasets/HayatoHongo/WildChat-4.8M
下载链接
链接失效反馈官方服务:
资源简介:
WildChat-4.8M是一个包含约319万次人类用户与ChatGPT之间对话的数据集。这个版本仅包含由OpenAI Moderations API或Detoxify标记为非毒性的用户输入和ChatGPT回复。数据集包括状态、国家、散列的IP地址、请求头部以及完整的对话记录。数据集中包含了用户与聊天机器人的各种交互,如模棱两可的请求、代码切换、话题转换、政治辩论等。此外,还包含来自推理模型'o1-preview'和'o1-mini'的11万8千多次非毒性对话。
创建时间:
2025-11-16
原始信息汇总
WildChat-4.8M 数据集概述
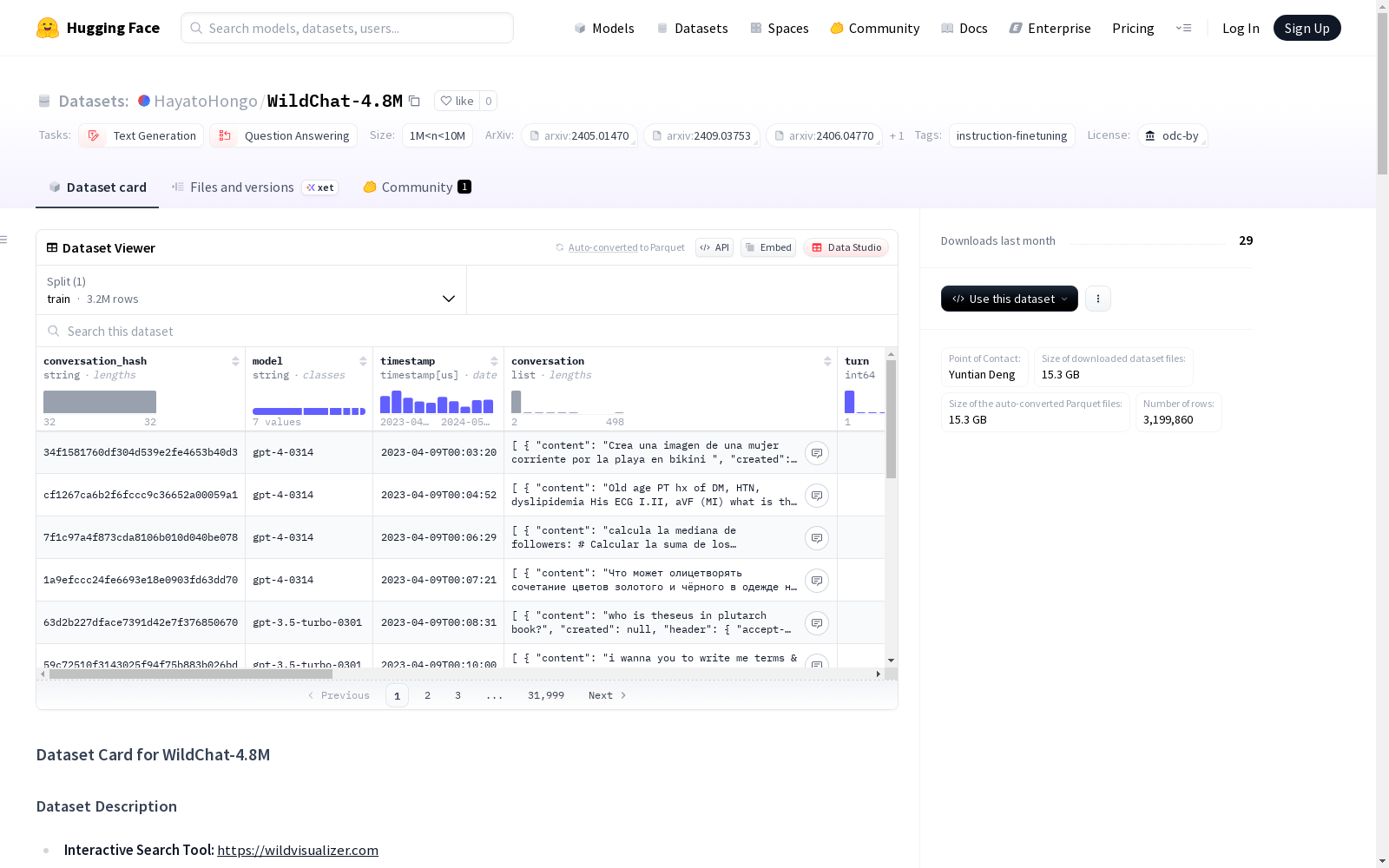
数据集基本信息
- 数据集名称: WildChat-4.8M
- 许可证: odc-by
- 数据规模: 1M<n<10M
- 任务类别: 文本生成、问答
- 数据量: 3,199,860 个对话
- 数据集大小: 42,645,714,270.24 字节
- 下载大小: 15,282,293,424 字节
数据集来源
- 基础版本: 从 WildChat-4.8M-Full 数据集过滤而来
- 原始对话数: 4,804,190 个对话
- 过滤后对话数: 3,199,860 个非毒性对话
- 过滤掉对话数: 1,543,476 个毒性对话
数据特征
核心字段
conversation_hash: 对话内容哈希值model: OpenAI 模型名称timestamp: 对话最后轮次的时间戳conversation: 用户/助手对话轮次列表turn: 对话轮次数量language: 对话语言
对话内容结构
每个对话轮次包含:
content: 对话内容role: 说话者角色(用户或助手)language: 检测到的语言toxic: 是否包含毒性内容redacted: 是否已匿名化处理turn_identifier: 唯一标识符
用户信息字段
hashed_ip: 哈希处理的IP地址state: 推断的州/省信息country: 推断的国家信息header: 请求头信息
模型响应信息
timestamp: 服务器接收响应时间temperature: 温度参数top_p: Top-p参数token_counter: 令牌计数usage: 使用详情统计
内容审核信息
openai_moderation: OpenAI审核结果detoxify_moderation: Detoxify审核结果toxic: 整体毒性标记
模型分布
| 模型系列 | 对话数量 |
|---|---|
| gpt-4o | 1,539,780 |
| gpt-3.5-turbo | 688,900 |
| gpt-4.1-mini | 634,037 |
| gpt-4 | 202,915 |
| o1-mini | 58,529 |
| o1-preview | 53,307 |
| gpt-4-turbo | 22,392 |
特殊特性
- 推理模型对话: 包含 111,836 个来自 o1-preview 和 o1-mini 的非毒性推理模型对话
- 多语言支持: 覆盖数十种语言(早期版本检测到68种)
- 地理位置信息: 包含基于IP地址推断的地理位置数据
- 内容审核: 使用OpenAI Moderation API和Detoxify进行毒性内容过滤
数据处理
- 去标识化: 使用Microsoft Presidio、自定义正则规则和手动调整
- 秘密信息移除: 使用TruffleHog扫描移除已验证的秘密信息
- 毒性过滤: 仅保留被OpenAI Moderations API或Detoxify标记为非毒性的对话
相关资源
- 交互式搜索工具: https://wildvisualizer.com
- WildChat论文: https://arxiv.org/abs/2405.01470
- WildVis论文: https://arxiv.org/abs/2409.03753
- 完整版本: https://huggingface.co/datasets/allenai/WildChat-4.8M-Full
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建真实用户交互数据集对理解人机对话模式至关重要。WildChat-4.8M通过收集真实用户与ChatGPT的对话记录构建而成,原始数据经过严格的内容筛选流程,采用OpenAI审核接口与Detoxify工具双重过滤机制,移除了被标记为有害的对话内容。数据预处理阶段运用微软Presidio框架与自定义正则规则进行匿名化处理,并通过TruffleHog扫描清除已验证的敏感信息,最终形成包含319万条非毒性对话的纯净语料库。
使用方法
研究人员可通过HuggingFace平台直接加载该数据集,利用其丰富的对话元数据开展多项研究。在模型训练方面,该数据集适用于指令微调任务,特别是对安全对齐模型的研究具有重要价值。数据分析时可结合对话哈希值与回合标识符进行精准定位,利用语言标签和多轮对话结构研究跨语言对话模式。需要注意的是,若需研究包含有害内容的全版本数据,需另行申请访问权限并提供充分的研究理由。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的广泛应用,对真实世界交互数据的需求日益增长。WildChat-4.8M数据集由艾伦人工智能研究所于2024年创建,核心研究团队包括邓云天等学者,旨在通过收集480万条真实用户与ChatGPT的对话记录,为对话生成与问答任务提供大规模训练资源。该数据集聚焦于多语言环境下的开放式对话场景,涵盖代码转换、话题迁移等复杂交互模式,其非毒性筛选机制为安全对齐研究提供了重要基准,显著推动了对话系统在真实应用场景中的适应性研究。
当前挑战
构建过程中面临双重挑战:在领域问题层面,需解决真实对话中存在的语义模糊性、多语言混合及话题跳跃等自然语言理解难题;在数据构建环节,既要通过OpenAI审核API与Detoxify工具精准识别毒性内容,又需利用微软Presidio框架完成用户隐私信息脱敏,同时应对跨地域用户行为差异带来的数据分布异构性。这些技术难点使得数据清洗与质量保障成为数据集构建的核心瓶颈。
常用场景
经典使用场景
在自然语言处理领域,WildChat-4.8M数据集为研究真实场景下的人机对话交互提供了宝贵资源。其包含的319万条非毒性对话记录,覆盖了多语言环境、话题转换及代码混合等复杂情境,尤其适用于训练和评估对话生成模型的泛化能力。通过整合用户的地理位置、设备信息及多轮对话轨迹,该数据集能够模拟真实世界中的开放式交流模式,为构建更自然的对话系统奠定基础。
解决学术问题
该数据集有效解决了对话系统中数据稀缺性与真实性的核心矛盾。通过过滤毒性内容并保留多样化的用户意图,它为研究对话安全性、跨语言理解以及长文本连贯性提供了标准化实验环境。其包含的11万余条推理模型对话记录,进一步推动了复杂推理任务与指令跟随能力的研究,填补了真实交互数据在学术评估中的空白。
实际应用
在实际部署中,WildChat-4.8M被广泛应用于智能客服系统与个性化助手的优化。企业可利用其多国语言对话样本训练本地化服务机器人,而开发者则通过分析用户请求的分布模式改进意图识别模块。该数据集的地理元数据还能辅助研究文化差异对对话策略的影响,为全球化产品提供数据支撑。
数据集最近研究
最新研究方向
在自然语言处理领域,大规模对话数据集正推动人机交互研究的深度发展。WildChat-4.8M凭借其480万条真实用户与ChatGPT的交互记录,为探索开放域对话系统的行为模式提供了珍贵资源。当前研究聚焦于多语言语境下的意图理解与话题迁移机制,特别是通过地理元数据分析跨文化对话特征。该数据集内含的11万条推理模型对话记录,为复杂逻辑推理任务的性能优化提供了新视角。随着数据安全治理需求的提升,基于OpenAI与Detoxify双重过滤机制的有害内容识别技术,已成为构建安全对话系统的关键参考。这些进展不仅深化了对大语言模型泛化能力的认知,更为构建下一代负责任人工智能奠定了数据基石。
以上内容由遇见数据集搜集并总结生成


