kk-tokenizer-fertility-baseline
收藏Hugging Face2026-04-30 更新2026-05-01 收录
下载链接:
https://huggingface.co/datasets/Abzalbek89/kk-tokenizer-fertility-baseline
下载链接
链接失效反馈官方服务:
资源简介:
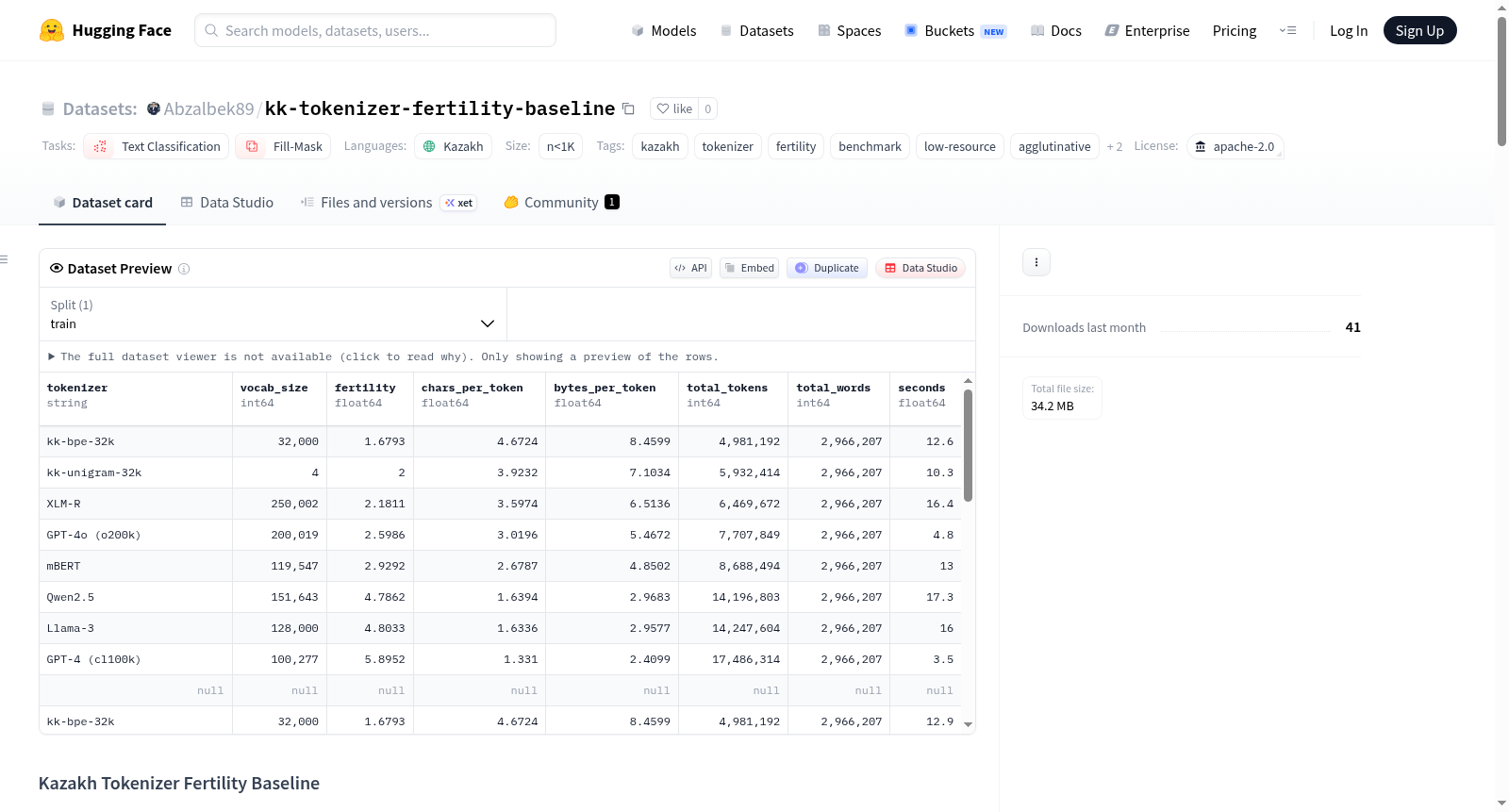
该数据集名为哈萨克语分词器效率基准,旨在为哈萨克语的分词器提供可复现的效率基准测试。数据集作为论文《Tokenizer Optimization for Kazakh Small Language Models》(待发表,目标期刊:ACM TALLIP)的配套成果,主要用于评估不同子词分词器在哈萨克语上的效率表现。数据集包含13种分词器的详细性能比较,包括哈萨克语定制训练的BPE/Unigram分词器、形态学感知分词器以及多语言/工业级分词器(如mBERT、XLM-R、GPT-4等)。评估基于一个包含2,966,207个空白分隔词(约15K文档)的验证集,主要指标包括分词效率(Fertility,即总token数/总词数,越低越好)和压缩率(字符数/token,越高越好)。最佳哈萨克语定制分词器(kk-bpe-32k)的效率比GPT-4高3.51倍,可显著降低API成本并扩展有效上下文窗口。数据集还包含完整的实验复现指南、配套分词器仓库链接以及Apache 2.0许可证信息。
创建时间:
2026-04-29
原始信息汇总
Kazakh Tokenizer Fertility Baseline 数据集概述
基本信息
- 语言: 哈萨克语 (kk)
- 许可证: Apache 2.0
- 任务类别: 文本分类、掩码填充
- 数据集规模: n < 1K
- 标签: 哈萨克语、分词器、生育率、基准测试、低资源语言、粘着语、形态感知、自然语言处理
数据集核心内容
该数据集是哈萨克语子词分词器的可复现生育率(Fertility)基准测试,为论文《Tokenizer Optimization for Kazakh Small Language Models》(筹备中,目标期刊:ACM TALLIP)提供配套实验数据。
关键指标排名
最佳与最差结果
| 排名 | 分词器 | 生育率 (Fertility) |
|---|---|---|
| 🥇 最佳 | kk-bpe-32k |
1.679 |
| 🚨 最差 | GPT-4 (cl100k) |
5.895 |
| GPT-4 惩罚 | GPT-4 (cl100k) 比最佳哈萨克语训练分词器效率低 3.51 倍 |
13 个分词器完整排名
自有——哈萨克语训练,无形态预分割
| 分词器 | 词表大小 | 生育率 ↓ | 字符/词元 ↑ |
|---|---|---|---|
kk-bpe-32k |
32,000 | 1.679 | 4.672 |
kk-sp-bpe-32k |
32,000 | 1.758 | 4.463 |
kk-sp-unigram-32k |
32,000 | 1.762 | 4.454 |
kk-hf-unigram-32k |
32,000 | 2.026 | 3.872 |
自有——哈萨克语训练,形态感知(Morfessor → 分词器)
| 分词器 | 词表大小 | 生育率 ↓ | 字符/词元 ↑ |
|---|---|---|---|
kk-morph-hf-bpe-32k |
32,000 | 1.761 | 4.456 |
kk-morph-sp-unigram-32k |
32,000 | 1.945 | 4.034 |
kk-morph-hf-unigram-32k |
32,000 | 2.346 | 3.345 |
参考——多语言/工业分词器
| 分词器 | 词表大小 | 生育率 ↓ | 字符/词元 ↑ |
|---|---|---|---|
XLM-R |
250,002 | 2.181 | 3.597 |
GPT-4o (o200k) |
200,019 | 2.599 | 3.020 |
mBERT |
119,547 | 2.929 | 2.679 |
Qwen2.5 |
151,643 | 4.786 | 1.639 |
Llama-3 |
128,000 | 4.803 | 1.634 |
GPT-4 (cl100k) |
100,277 | 5.895 | 1.331 |
方法论
评估数据集
- 留出评估集: 2,966,207 个空白分隔词(约 15K 文档),来自
Abzalbek89/corpus_clean的验证集。
评估指标
- 生育率 (Fertility) = 总词元数 / 总空白分隔词数(越低越好)
- 压缩率 (字符/词元) = 总字符数 / 总词元数(越高越好)
- 压缩率 (字节/词元) = 总 UTF-8 字节数 / 总词元数(越高越好)
训练的分词器(词表大小 32,000,共享相同训练语料)
kk-bpe-32k— HF tokenizers ByteLevel BPEkk-sp-bpe-32k— SentencePiece BPE(character_coverage=1.0,NFKC)kk-sp-unigram-32k— SentencePiece Unigramkk-hf-unigram-32k— HF tokenizers Unigram + ByteLevel 预分词kk-morph-hf-bpe-32k— 在 Morfessor 分割语料上训练的 HF BPEkk-morph-hf-unigram-32k— 在 Morfessor 分割语料上训练的 HF Unigramkk-morph-sp-unigram-32k— 在 Morfessor 分割语料上训练的 SentencePiece Unigram
参考分词器
mBERT、XLM-R、Llama-3、Qwen 2.5、GPT-4(cl100k_base)、GPT-4o(o200k_base)
文件结构
| 路径 | 描述 |
|---|---|
experiment.py |
版本 1——单一 Unigram 基线 |
experiment_v2.py |
版本 2——扩展(跨库 BPE/Unigram) |
experiment_v3_fix.py |
版本 2 修复——通过原始 SentencePieceProcessor 重新测量 SentencePiece 分词器 |
experiment_morph.py |
实验 2——形态感知变体 |
morfessor.bin |
训练好的 Morfessor 分割模型(前 100 万哈萨克语词汇) |
v2/fertility_v2.csv、.json、.png |
版本 2 固定数据 |
v3/fertility_v3.csv、.json、.png |
版本 3 扩展数据(含形态感知) |
v3/RESULTS_V3.md |
可读版本 3 报告 |
复现方法
要求环境:≥30GB 磁盘、≥16GB RAM。安装依赖后运行 experiment_morph.py,总运行时间约 30 分钟(缓存 Morfessor 模型)至 70 分钟(冷启动)。
关联分词器仓库
Abzalbek89/kk-tokenizer-bpe-32kAbzalbek89/kk-tokenizer-sp-bpe-32kAbzalbek89/kk-tokenizer-sp-unigram-32kAbzalbek89/kk-tokenizer-hf-unigram-32kAbzalbek89/kk-tokenizer-morph-hf-bpe-32kAbzalbek89/kk-tokenizer-morph-hf-unigram-32kAbzalbek89/kk-tokenizer-morph-sp-unigram-32k
引用信息
bibtex @misc{kk_tokenizer_fertility_2026, title = {Kazakh Tokenizer Fertility Baseline}, author = {Abzalbek Ulasbek}, year = {2026}, howpublished = {url{https://huggingface.co/datasets/Abzalbek89/kk-tokenizer-fertility-baseline}}, }
搜集汇总
数据集介绍
构建方式
该数据集专为评估哈萨克语子词分词器的效率而构建,聚焦于低资源、粘着性语言的形态学挑战。研究者首先从大规模语料库中筛选出约15K文档(300万词)作为验证集,并基于此设计了13种不同分词器的对比实验。这些分词器包括四种自研的非形态感知模型(如kk-bpe-32k)、三种结合Morfessor形态预分割的变体,以及六种工业级多语言分词器(如GPT-4、XLM-R)。所有自研分词器均采用统一的32K词表大小,在相同训练语料上通过HF Tokenizers、SentencePiece等框架进行训练,确保了比较的公平性与可复现性。
特点
该数据集的核心在于首次系统性量化了分词器对哈萨克语的“生殖力”(Fertility)指标,即平均每个词被切分成的token数量,该值越低代表分词效率越高。实验揭示了一个惊人事实:专门训练的kk-bpe-32k分词器生殖力仅为1.679,而GPT-4的cl100k分词器高达5.895,性能差距达3.51倍。值得注意的是,形态感知分词器并未显著优于非形态感知版本,暗示现代BPE算法已能隐式捕捉粘着语的形态边界。此外,压缩率(chars/token)指标进一步验证了专用分词器在降低API成本、扩展有效上下文长度方面的巨大潜力。
使用方法
用户可通过HuggingFace Datasets库直接加载该基准数据集,并利用配套的Python脚本(如experiment_morph.py)复现完整评估流程。建议在具备30GB磁盘和16GB内存的环境下运行,总耗时约30-70分钟。用例包括:研究人员可对比不同分词器在哈萨克语上的生殖力与压缩率;开发者可选取最优分词器(如kk-bpe-32k)部署到下游任务中,以显著降低推理成本。数据集还提供了Morfessor形态模型(morfessor.bin),用于探索形态感知预分割对分词效果的影响。所有脚本均基于Apache 2.0许可,支持灵活的扩展与再发布。
背景与挑战
背景概述
哈萨克语作为一种黏着语,其丰富的形态变化对自然语言处理中的子词分词器构成了独特挑战。由Abzalbek Ulasbek于2026年创建的kk-tokenizer-fertility-baseline基准数据集,聚焦于评估不同分词器在哈萨克语文本上的效率。该数据集基于约15K文档、近三百万词规模的验证集,系统比较了13种分词器的生育率指标,涵盖自训练的BPE、Unigram及形态感知变体,并与GPT-4、mBERT等工业级分词器对照。研究揭示了定制化分词器相较通用方案在效率上的显著优势,为低资源黏着语语言模型的优化提供了关键基准。
当前挑战
该数据集核心解决了黏着语分词效率评测的领域空白,即量化分词器处理哈萨克语时产生的冗余标记。构建过程中面临两大挑战:一是确保评估语料的代表性和纯净性,从大规模语料库中筛选验证集并处理多来源噪声;二是设计公平的比较框架,需统一词汇量(32K)与训练语料,同时整合形态预切分(Morfessor)等复杂流水线,以分离不同技术路线的影响。此外,跨库分词器(如tiktoken、SentencePiece)的接口差异也为复现实验增加了工程难度。
常用场景
经典使用场景
在低资源黏着语自然语言处理研究中,分词器的词元化效率是影响语言模型性能与部署成本的核心因素。该数据集构建了一套系统性的生育率基准测试框架,专门用于评估不同分词器对哈萨克语文本的词元化效率。通过设计统一的评估指标与标准化流程,研究者可利用该数据集对BPE、Unigram等主流分词算法及其形态学感知变体进行横向比较,从而在语料上精确衡量各分词器的生词率与压缩比指标。这为针对哈萨克语这类形态丰富的语言进行分词器选型提供了可重复的量化依据。
实际应用
在实际应用层面,该数据集的价值体现在显著降低哈萨克语自然语言处理系统的部署与运行成本。研究结果表明,最优的哈萨克语专用分词器相较GPT-4分词器可实现3.51倍的效率提升,这意味着处理相同规模文本时API调用成本降低约72%,同时有效上下文窗口扩展至3.5倍。这一效率优势直接转化为哈萨克语大语言模型在不同算力约束场景下的可行性提升,尤其对资源受限环境中的下游任务部署具有现实指导意义,促使工业界在构建多语言服务时重新评估分词器定制策略。
衍生相关工作
该数据集催生了系列定制化哈萨克语分词器模型的发布,形成了从基准测试到实际应用的完整生态链条。具体衍生产品包括基于标准BPE与SentencePipe的四种核心分词器,以及融入Morfessor形态学预分割的三种增强型变体。这些分词器均经过严格生育率评估,为后续研究提供了可直接应用的优质基础组件。循此方向,研究者可进一步探索面向其他低资源黏着语的分词优化方案,或将该基准测试方法论扩展至跨语言分词迁移学习的评估体系中,推动形态学感知分词技术在多语言场景下的理论深化与工程实践。
以上内容由遇见数据集搜集并总结生成


