HAICTrain 和 HAICBench
收藏arXiv2025-02-28 更新2025-03-04 收录
下载链接:
https://huggingface.co/datasets/KuaishouHAIC/HAIC
下载链接
链接失效反馈官方服务:
资源简介:
HAICTrain是由快手科技推出的一个包含126K视频-字幕对的数据集,这些视频-字幕对通过Gemini-1.5-Pro生成并经过人工验证,旨在用于训练多模态大型语言模型,以改善对人类动作的理解。HAICBench则包含500个经过人工标注的视频-字幕对和1,400个QA对,用于全面评估多模态大型语言模型在人类动作理解方面的能力。
HAICTrain is a dataset launched by Kuaishou Technology, which comprises 126K video-subtitle pairs generated by Gemini-1.5-Pro and manually verified. It is designed for training multimodal large language models to enhance the understanding of human actions. HAICBench, on the other hand, contains 500 manually annotated video-subtitle pairs and 1,400 QA pairs, which are used to comprehensively evaluate the capabilities of multimodal large language models in human action understanding.
提供机构:
快手科技
创建时间:
2025-02-28
搜集汇总
数据集介绍
构建方式
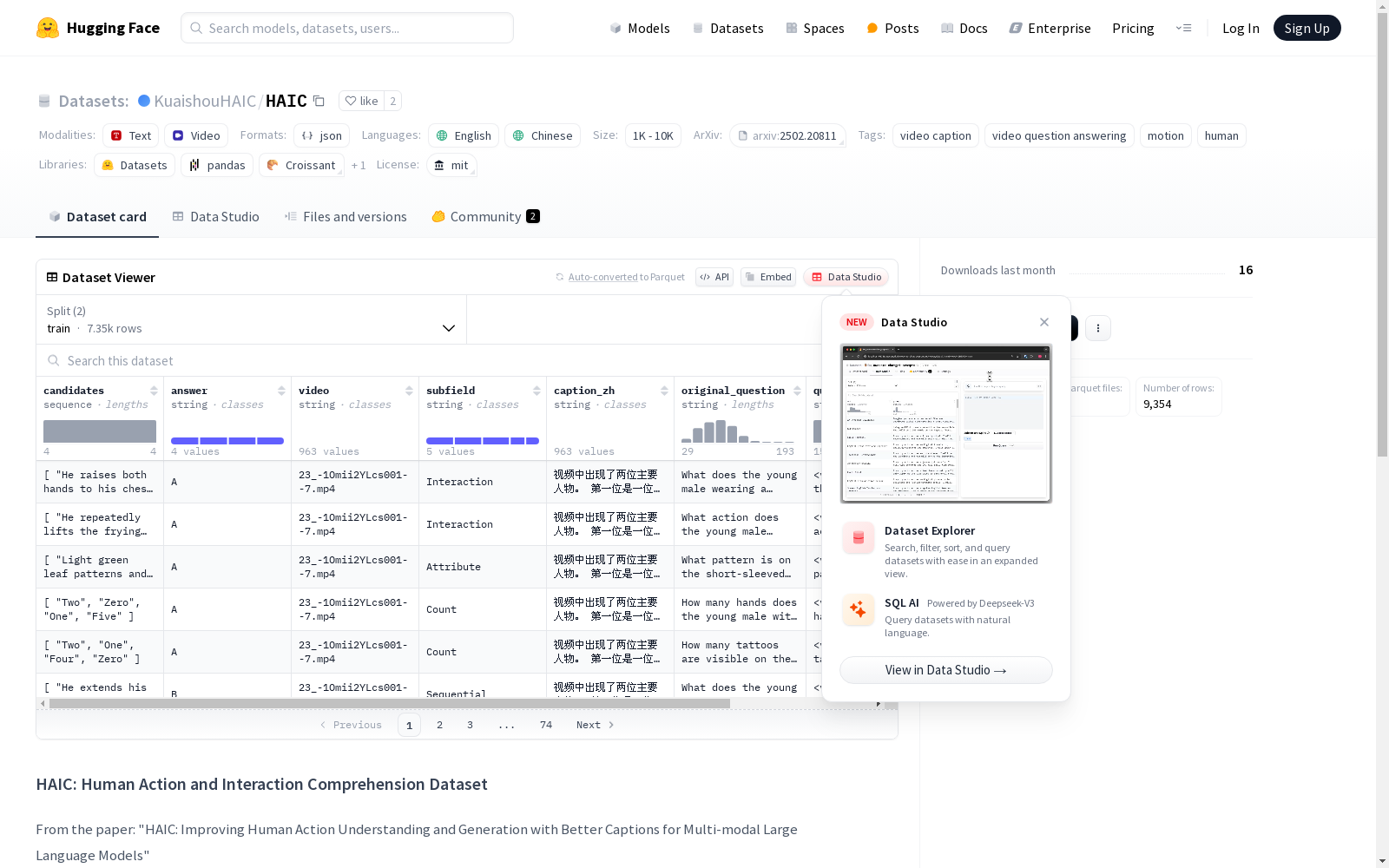
HAICTrain 和 HAICBench 数据集的构建方式分为两个阶段:首先,通过设计策略从互联网上积累具有清晰人类动作的视频;其次,对这些视频进行标准化描述,使用人类属性来区分个体,并按时间顺序详细描述他们的动作和互动。通过这一流程,我们创建了两个数据集:HAICTrain 和 HAICBench。HAICTrain 包含 126K 个视频-描述对,由 Gemini-Pro 生成并经过验证,用于训练目的。同时,HAICBench 包括 500 个手动标注的视频-描述对和 1,400 个 QA 对,用于全面评估人类动作理解。
使用方法
HAICTrain 和 HAICBench 数据集的使用方法取决于具体的应用场景。对于训练多模态大型语言模型以增强人类动作理解能力,可以使用 HAICTrain 数据集进行训练。对于评估模型在人类动作理解方面的能力,可以使用 HAICBench 数据集进行测试。在使用过程中,需要根据数据集的特点和应用场景,选择合适的使用方法和评价指标。
背景与挑战
背景概述
近年来,多模态大型语言模型(MLLMs)在视频理解任务上取得了显著进展,尤其在涉及人类行为的视频理解方面。然而,由于缺乏高质量的数据,MLLMs在理解人类行为方面的表现仍然有限。为了解决这一问题,Xiao Wang等人提出了一种两阶段的数据标注流程。首先,他们设计了一种策略,从互联网上积累具有清晰人类行为的视频。其次,他们使用一种标准化字幕格式对视频进行标注,该格式利用人类属性来区分个体,并按时间顺序详细描述他们的行为和互动。通过这一流程,他们创建了两个数据集,即HAICTrain和HAICBench。HAICTrain包括126K个视频-字幕对,由Gemini-Pro生成并经过验证,用于训练目的。HAICBench包括500个手动标注的视频-字幕对和1,400个QA对,用于全面评估人类行为理解。实验结果表明,使用HAICTrain进行训练不仅可以显著提高4个基准测试中的人类理解能力,还可以提高文本到视频生成的结果。这两个数据集都在https://huggingface.co/datasets/KuaishouHAIC/HAIC上发布。
当前挑战
构建HAICTrain和HAICBench数据集的过程中,研究人员面临着两个主要挑战。首先,如何从互联网上自动积累大规模的、具有清晰人类行为的视频。其次,如何定义一种字幕格式,可以清楚地区分不同的人,并分别详细描述他们的行为和互动。为了解决上述挑战,研究人员提出了一种新颖的数据生成流程,包括两个阶段。在视频积累阶段,他们从各种领域积累具有清晰、有意义的人类行为的视频,并识别它们的特定时间戳。在字幕标注阶段,他们定义了一种字幕格式,使用人类属性来区分个体,并按时间顺序为每个人详细标注身体动作和互动。
常用场景
经典使用场景
HAICTrain 和 HAICBench 数据集主要应用于提升多模态大型语言模型 (MLLM) 在视频理解方面的性能,特别是涉及人类行为的视频。该数据集通过提供高质量、细粒度的人类动作和交互描述,帮助 MLLM 更准确地理解和生成视频内容。
解决学术问题
HAICTrain 和 HAICBench 数据集解决了 MLLM 在理解人类行为方面的局限性问题。现有的大多数工作仅提供粗粒度的动作描述,不足以理解精细的行为。HAICTrain 和 HAICBench 通过提供细粒度的人类动作和交互描述,显著提升了 MLLM 的理解能力。
实际应用
HAICTrain 和 HAICBench 数据集在实际应用中,可被用于提高 MLLM 在视频理解、文本到视频生成等任务上的性能。例如,在自动驾驶系统中,该数据集可以帮助模型更好地理解驾驶场景中的人类行为,从而提高驾驶安全性。在人类视频生成方面,该数据集可以提高生成视频的质量和语义准确性。
数据集最近研究
最新研究方向
近年来,多模态大型语言模型(MLLMs)在视频理解任务中取得了显著进展,特别是在涉及人类行为的视频理解方面。然而,这些模型在缺乏高质量数据的情况下,其性能仍然受限。为了解决这个问题,研究人员引入了一种两阶段数据注释流程。首先,设计策略从互联网上积累包含清晰人类行为的视频。其次,视频以标准化的字幕格式进行标注,该格式使用人类属性来区分个体,并按时间顺序详细描述他们的行为和互动。通过这一流程,研究人员整理出两个数据集:HAICTrain和HAICBench。HAICTrain包括由Gemini-Pro生成的126K视频-字幕对,并经过验证用于训练目的。同时,HAICBench包括500个手动标注的视频-字幕对和1400个QA对,用于全面评估人类行为理解。实验结果表明,使用HAICTrain进行训练不仅显著提高了跨4个基准的人类理解能力,还可以提高文本到视频的生成结果。HAICTrain和HAICBench的发布将有助于推动多模态大型语言模型在视频理解方面的研究。
相关研究论文
- 1HAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models快手科技 · 2025年
以上内容由遇见数据集搜集并总结生成


