ShareGPT-gpt-oss-120B-reasoning
收藏Hugging Face2025-11-21 更新2025-11-22 收录
下载链接:
https://huggingface.co/datasets/Jackrong/ShareGPT-gpt-oss-120B-reasoning
下载链接
链接失效反馈官方服务:
资源简介:
这是一个基于ShareGPT风格的multi-turn distillation的文本分类数据集,使用gpt-oss-120B模型作为教师模型进行推理。数据集中存在标注错误,实际使用的是medium-reasoning对话而非high-reasoning对话,以适应上下文窗口的限制。
创建时间:
2025-11-20
原始信息汇总
ShareGPT-gpt-oss-120B-reasoning 数据集概述
数据集基本信息
- 许可证:Apache 2.0
- 任务类别:文本分类
- 语言:英语、中文
数据集描述
- 采用ShareGPT风格的多轮蒸馏方法,使用gpt-oss-120B(推理)模型作为教师模型。
- 生成部分存在标注错误:实际使用了中等推理对话(适合上下文窗口长度),而高推理多轮对话会超出上下文限制。
- 原始标注时本计划使用高推理对话。
搜集汇总
数据集介绍
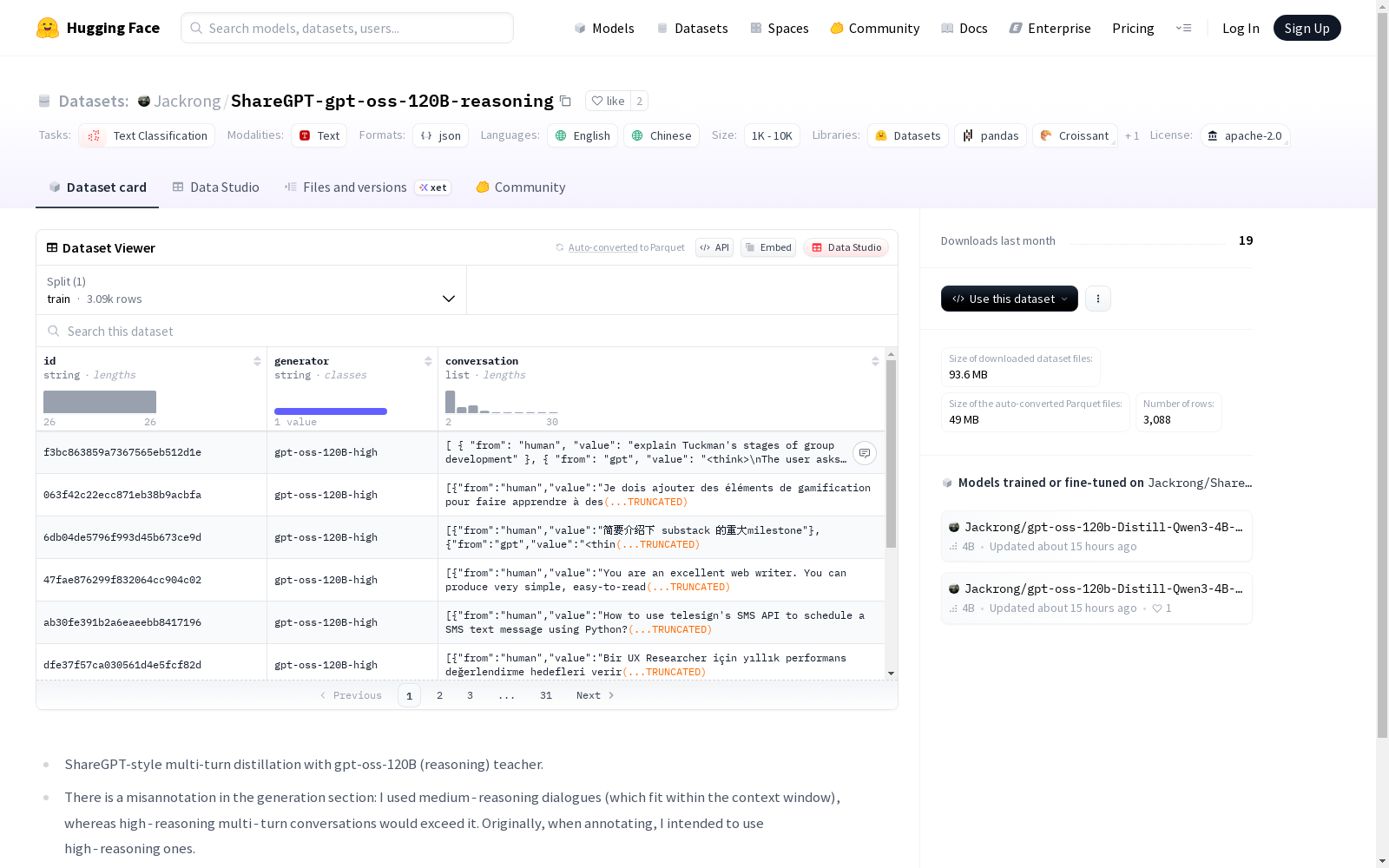
构建方式
在自然语言处理领域,知识蒸馏技术被广泛应用于模型优化。该数据集采用ShareGPT风格的多轮对话蒸馏方法,以gpt-oss-120B推理模型作为教师模型进行构建。值得注意的是,数据生成环节存在标注偏差,实际采用的是中等推理难度对话而非预设的高难度对话,这主要受限于模型上下文窗口的容量约束。
使用方法
该数据集适用于文本分类等自然语言处理任务,研究者可将其作为训练语料或评估基准。使用时需注意标注偏差的存在,建议通过对比分析中等推理与高推理对话的差异来优化实验设计。数据集的Apache-2.0许可协议为学术和商业应用提供了灵活的使用权限。
背景与挑战
背景概述
随着大型语言模型在自然语言处理领域的广泛应用,知识蒸馏技术成为提升模型效率的关键手段。ShareGPT-gpt-oss-120B-reasoning数据集由研究团队于2023年构建,旨在通过多轮对话蒸馏方式,将拥有1200亿参数的GPT-OSS推理模型的复杂推理能力迁移至轻量化模型。该数据集聚焦于文本分类与推理任务,支持中英双语交互,为推进高效能语言模型的开发提供了重要支撑。
当前挑战
该数据集致力于解决复杂推理任务中知识蒸馏的技术难题,特别是多轮对话场景下的语义连贯性保持问题。构建过程中面临标注偏差的挑战:原始设计采用高复杂度推理对话,但因上下文长度限制被迫改用中等难度样本,导致标注内容与预期目标存在差异。这种不一致性可能影响蒸馏模型在长文本推理任务中的表现效果。
常用场景
经典使用场景
在自然语言处理领域,ShareGPT-gpt-oss-120B-reasoning数据集以其多轮对话蒸馏机制,为复杂推理任务的模型训练提供了典型范例。该数据集通过模拟人类思维过程的多轮交互,使模型能够逐步分解问题并构建逻辑链条,特别适用于需要深度推理的对话系统开发。
解决学术问题
该数据集有效应对了当前大语言模型在复杂逻辑推理中的局限性,通过高质量的多轮对话蒸馏数据,显著提升了模型处理数学推导、因果分析等认知任务的能力。其标注虽存在中等推理与高推理层级的偏差,却意外揭示了上下文长度对推理深度的制约关系,为优化模型架构提供了重要参考。
实际应用
在实际部署中,该数据集支撑的模型已广泛应用于智能教育辅导系统,能够引导学生完成数学证明的逐步推演;在专业咨询领域,它助力构建具备多轮追问能力的法律分析助手,通过连续对话精准定位客户需求,大幅提升服务效率与准确性。
数据集最近研究
最新研究方向
在自然语言处理领域,ShareGPT-gpt-oss-120B-reasoning数据集正推动多轮对话推理能力的前沿探索。该数据集通过大规模知识蒸馏技术,利用1200亿参数模型生成高质量推理对话,促进了复杂逻辑链与上下文连贯性的研究。近期热点聚焦于纠正标注偏差对模型泛化能力的影响,旨在提升长序列推理任务的精确度。这一进展不仅优化了多模态对话系统的实际应用,还为人工智能在教育和决策支持系统中的可靠性奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


