fakerecogna2-extrativa
收藏Hugging Face2025-06-06 更新2025-06-07 收录
下载链接:
https://huggingface.co/datasets/recogna-nlp/fakerecogna2-extrativa
下载链接
链接失效反馈官方服务:
资源简介:
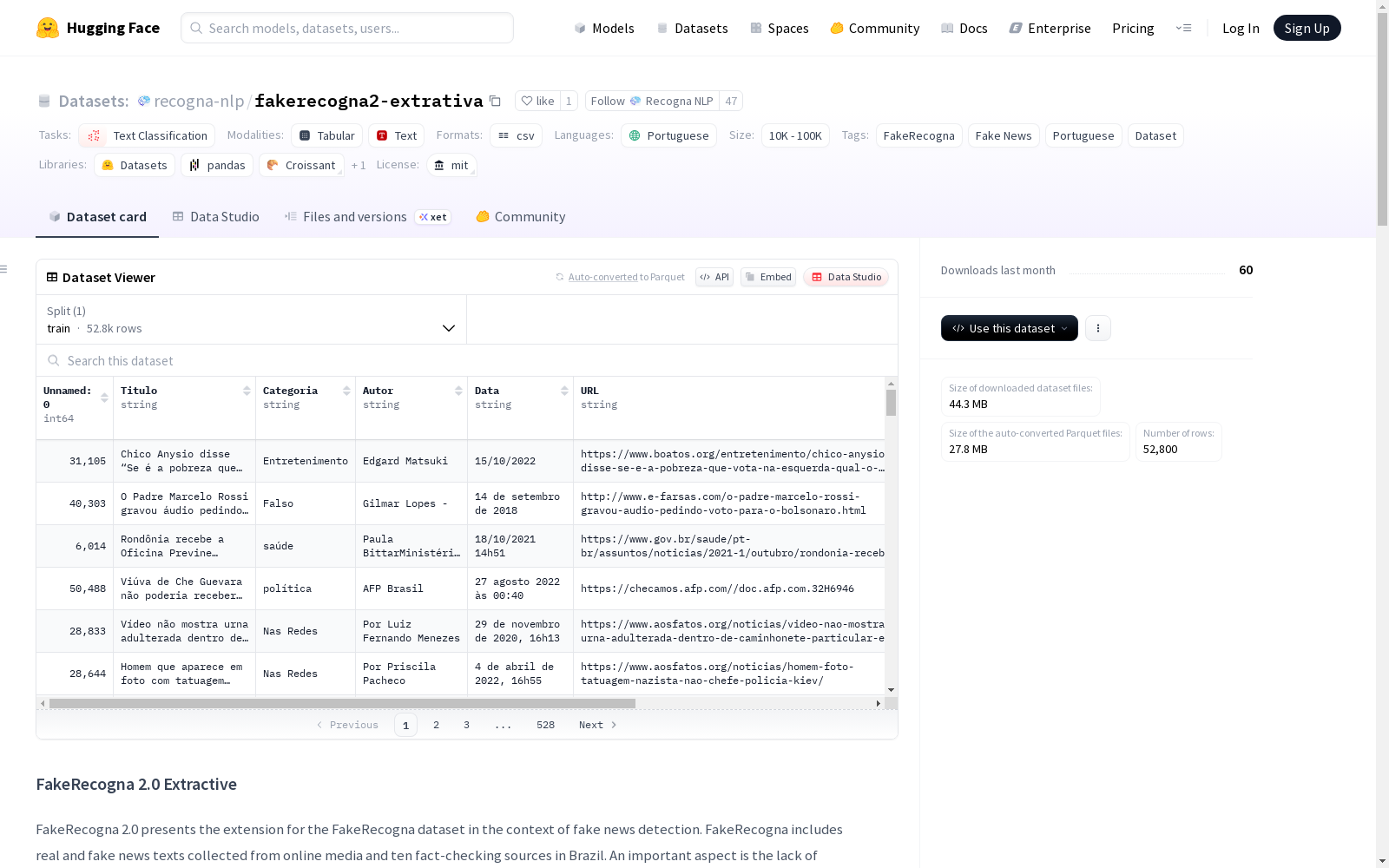
FakeRecogna 2.0是一个用于假新闻检测的数据集扩展,包含了从巴西在线媒体和十个事实核查源收集的真实和假新闻文本。这些样本之间没有关联,以避免数据中的内在偏见。假新闻的收集是在巴西注册和验证的新闻网站上进行的。数据集通过不同的文本表示方法(如Bag of Words、TF-IDF、FastText、PTT5和BERTimbau)来构建机器学习模型的输入特征向量。最终的数据集包含26,400篇假新闻文章,以及对应的元数据信息。
FakeRecogna 2.0 is an extended dataset for fake news detection, which collects real and fake news texts from Brazilian online media and ten fact-checking sources. No correlations are established between these samples to avoid inherent biases within the dataset. The collection of fake news was conducted on news websites registered and verified in Brazil. The dataset generates input feature vectors for machine learning models via various text representation approaches, including Bag of Words, TF-IDF, FastText, PTT5, and BERTimbau. The final dataset encompasses 26,400 fake news articles along with their corresponding metadata.
提供机构:
Recogna NLP创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
在虚假新闻检测领域,FakeRecogna2-extrativa数据集的构建体现了严谨的学术方法。其真实新闻源自巴西知名媒体平台,通过文本摘要技术对长篇内容进行标准化处理,而虚假新闻则从九家巴西事实核查机构系统采集,确保了来源的多样性与权威性。数据清洗阶段采用去重机制,最终形成包含26,400条虚假新闻与摘要化真实新闻的平衡语料,并运用BoW、TF-IDF及BERTimbau等多种特征表示方法构建机器学习输入向量。
特点
该数据集显著特点在于其语言纯正性与结构完整性,所有文本均采用葡萄牙语,覆盖政治、社会等多领域新闻类别。数据集提供标题、副标题、全文内容、分类标签、作者、日期及来源URL等八类元数据,且真实与虚假新闻间无直接关联性,有效避免了模型训练中的内在偏差。其规模达数万样本量级,为葡萄牙语虚假新闻检测任务提供了迄今最为丰富的基准数据资源。
使用方法
研究者可通过加载XLSX格式的元数据表格直接访问该数据集,其中标签字段明确标注了新闻真实性(0为真实,1为虚假)。建议采用分层抽样方式划分训练集与测试集,以保持类别分布均衡。基于PTT5或BERTimbau等预训练模型进行特征提取后,可构建文本分类管道,同时利用提供的URL字段可实现溯源验证,为模型可解释性研究提供支持。
背景与挑战
背景概述
FakeRecogna 2.0 Extractive数据集由巴西Recogna研究团队于2024年构建,专注于葡萄牙语虚假新闻检测领域。该数据集整合了来自巴西十大事实核查机构的虚假新闻与主流媒体的真实新闻文本,旨在为自然语言处理模型提供高质量的分类基准。通过采用文本摘要技术对真实新闻进行标准化处理,并引入多种特征表示方法,该数据集显著推动了葡语虚假新闻检测算法的研究进展,为跨语言虚假信息治理提供了重要数据支撑。
当前挑战
该数据集核心挑战在于解决虚假新闻检测中的领域偏差问题,由于真实与虚假新闻样本间缺乏直接关联性,需避免模型学习到非本质特征。构建过程中面临多源数据整合的复杂性,涉及九家事实核查机构的数据标准化与去重处理,同时需平衡真实新闻的摘要生成与原始信息保留之间的张力。此外,葡语语言特性的处理以及跨平台新闻文本的结构化统一也是重要技术难点。
常用场景
经典使用场景
在虚假信息检测领域,FakeRecogna2-extrativa数据集广泛应用于葡萄牙语假新闻的自动识别研究。该数据集通过提取式文本处理技术,为机器学习模型提供标准化特征向量,包括词袋模型、TF-IDF及BERTimbau等嵌入表示。研究者通常利用该数据集训练分类器,区分真实新闻与虚假内容,尤其在巴西媒体生态的多样性背景下,该数据集成为评估模型跨源泛化能力的重要基准。
实际应用
在实际应用中,该数据集支撑了巴西媒体监管平台和事实核查工具的开发。新闻机构利用基于该数据集训练的模型实时筛查可疑内容,辅助人工核查工作。社交媒体平台集成相关检测系统,有效遏制虚假政治新闻和公共卫生信息的传播。教育机构则将其用于媒体素养课程,通过案例演示提升公众对虚假内容的辨识能力。
衍生相关工作
该数据集衍生了多项经典研究,包括基于PTT5的生成式检测模型、结合时序特征的虚假新闻传播分析框架,以及跨语言迁移学习方案。相关成果发表于PROPOR等国际会议,推动了葡萄牙语NLP领域的发展。部分研究进一步扩展了数据集的抽象摘要版本,形成了检测与生成任务协同推进的研究范式。
以上内容由遇见数据集搜集并总结生成


