MobileAgentBench
收藏arXiv2024-06-12 更新2024-06-14 收录
下载链接:
https://MobileAgentBench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
MobileAgentBench是由卡内基梅隆大学等机构创建的一个高效且用户友好的移动LLM代理基准测试数据集。该数据集包含100个任务,分布在10个开源应用中,旨在通过模拟日常任务来评估移动代理的性能。数据集的创建过程注重任务的成功条件灵活性和低代码侵入性,使得第三方开发者能够轻松扩展和定制任务。MobileAgentBench的应用领域广泛,主要用于学术和工业界,以解决移动代理性能评估的挑战,推动智能个人助理技术的发展。
MobileAgentBench is an efficient and user-friendly mobile LLM agent benchmark dataset created by Carnegie Mellon University and other institutions. It consists of 100 tasks distributed across 10 open-source applications, aiming to evaluate the performance of mobile agents by simulating real-world daily tasks. The dataset's creation process emphasizes flexible task success conditions and low code invasiveness, enabling third-party developers to easily extend and customize the tasks. With wide applicability, MobileAgentBench is primarily used in academic and industrial fields to address the challenges of mobile agent performance evaluation and promote the development of intelligent personal assistant technologies.
提供机构:
卡内基梅隆大学
创建时间:
2024-06-12
搜集汇总
数据集介绍
构建方式
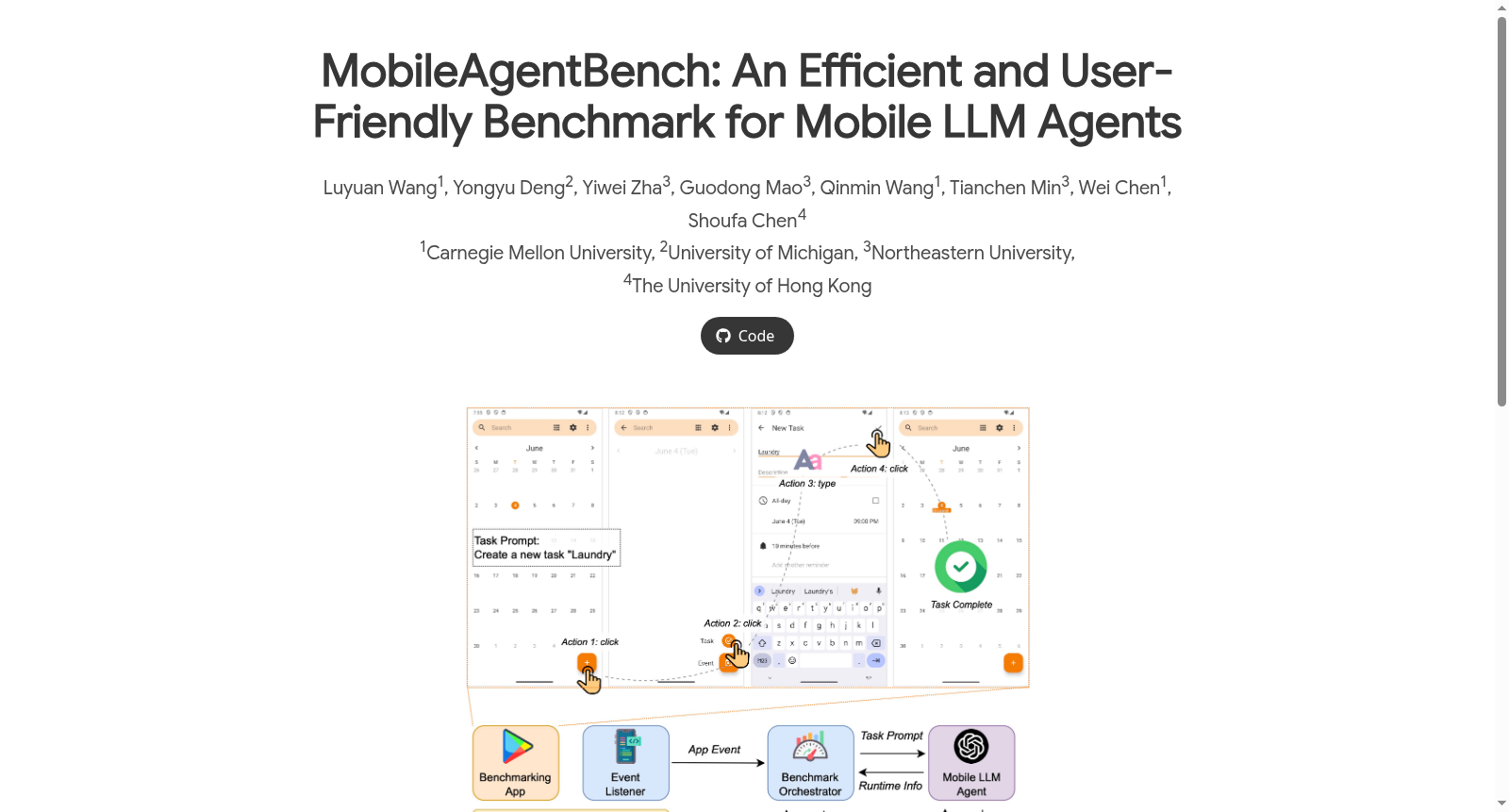
在移动智能助手领域,MobileAgentBench的构建采用了基于真实Android设备的评估框架。该框架通过Android无障碍服务捕获应用事件,并结合视图层次信息,实现了对任务完成状态的实时判断。数据集初始版本涵盖了10款开源应用中的100项任务,这些任务根据完成所需的最小步骤数被划分为不同难度等级,确保了评估的全面性与层次性。
特点
MobileAgentBench的突出特点在于其高度的实用性与鲁棒性。该数据集支持在真实设备或模拟器上运行,实现了完全自动化的评估流程,无需人工干预。其任务成功判断机制不依赖于固定的动作序列,而是通过检查最终UI状态,从而兼容多种可能的成功路径。此外,数据集集成简便,对现有智能体代码的侵入性极低,显著提升了研究效率。
使用方法
使用MobileAgentBench时,研究人员需导入其Python库并初始化任务协调器。用户需定义一个以任务提示为唯一参数的智能体入口函数,该函数在迭代执行动作前后调用协调器的相应方法,以收集执行时间与模型输出等数据。协调器的运行函数将自动遍历所有任务,并在任务完成或超时后切换至下一项,整个过程实现了对移动大语言模型智能体的端到端自动化评估。
背景与挑战
背景概述
随着大语言模型技术的迅猛发展,基于大语言模型的移动智能体因其能够直接与移动设备图形用户界面交互并自主管理日常任务的潜力,在学术界与工业界引起了广泛关注。MobileAgentBench由卡内基梅隆大学、密歇根大学、东北大学及香港大学的研究团队于2024年联合推出,旨在解决移动智能体性能评估中存在的基准测试稀缺问题。该数据集通过定义涵盖10款开源应用的100项任务,并依据难度分级,为移动智能体的能力提供了系统化、自动化的评估框架,显著推动了移动智能体领域的标准化研究进程。
当前挑战
MobileAgentBench致力于解决移动智能体在图形用户界面导航任务中的性能评估挑战,其核心在于如何准确判断任务完成状态,避免因应用状态无限性与动作序列多样性导致的评估偏差。在构建过程中,研究团队面临的主要挑战包括:确保基准测试在真实设备环境中的完全自主运行,避免依赖人工监督;设计灵活的任务成功判定机制,以兼容多种可能的完成路径;以及降低代码侵入性,使第三方开发者能够便捷地扩展自定义任务,这些挑战的克服使得该数据集在可用性与可靠性方面实现了重要突破。
常用场景
经典使用场景
在移动智能代理研究领域,MobileAgentBench作为一款高效且用户友好的基准测试框架,其经典使用场景聚焦于评估大型语言模型(LLM)驱动的移动代理在真实Android设备上的任务执行能力。该框架通过集成100项内置测试任务,覆盖日历、通讯录、文件管理器等10款开源应用,模拟用户日常操作,为研究人员提供了自动化、可扩展的性能评测平台。其设计允许代理在无需人工干预的环境中自主交互,通过实时状态监测与任务成功判定机制,系统化地衡量代理在图形用户界面(GUI)导航中的准确性与效率。
实际应用
在实际应用层面,MobileAgentBench为移动应用开发与智能助手优化提供了关键支持。科技公司可借助该基准测试框架,评估其基于LLM的移动代理在真实设备上的任务完成率、步骤效率与响应延迟,从而优化代理的交互逻辑与模型选择。例如,在智能日历管理、自动消息回复或文件整理等场景中,开发者能够通过定制化任务配置,快速验证代理在不同操作系统版本及设备型号上的兼容性与鲁棒性。这种低代码侵入式的集成方式,显著降低了企业研发成本,加速了下一代智能个人助手(IPA)的商业化落地进程。
衍生相关工作
MobileAgentBench的推出催生了一系列围绕移动LLM代理优化的衍生研究。以AppAgent为代表的探索-部署双阶段代理,通过自探索机制与检索增强生成技术,显著提升了复杂任务的成功率;AndroidArena则通过压缩视图层次与唯一节点标识,优化了提示工程与系统效率。同时,CogAgent开发了高效的多模态轻量模型,为端侧部署提供了可行方案,而Octopus v2进一步探索了设备本地运行的隐私保护范式。这些工作共同构建了移动代理从理论框架到工程实践的研究生态,持续推动着界面理解、动作规划与资源约束等关键方向的技术突破。
以上内容由遇见数据集搜集并总结生成


