cornstack-php-v1
收藏魔搭社区2025-12-03 更新2025-03-29 收录
下载链接:
https://modelscope.cn/datasets/nomic-ai/cornstack-php-v1
下载链接
链接失效反馈官方服务:
资源简介:
# CoRNStack PHP Dataset
The CoRNStack Dataset, accepted to [ICLR 2025](https://arxiv.org/abs/2412.01007), is a large-scale high quality training dataset specifically for code retrieval across multiple
programming languages. This dataset comprises of `<query, positive, negative>` triplets used to train [nomic-embed-code](https://huggingface.co/nomic-ai/nomic-embed-code),
[CodeRankEmbed](https://huggingface.co/nomic-ai/CodeRankEmbed), and [CodeRankLLM](https://huggingface.co/nomic-ai/CodeRankLLM).
## CoRNStack Dataset Curation
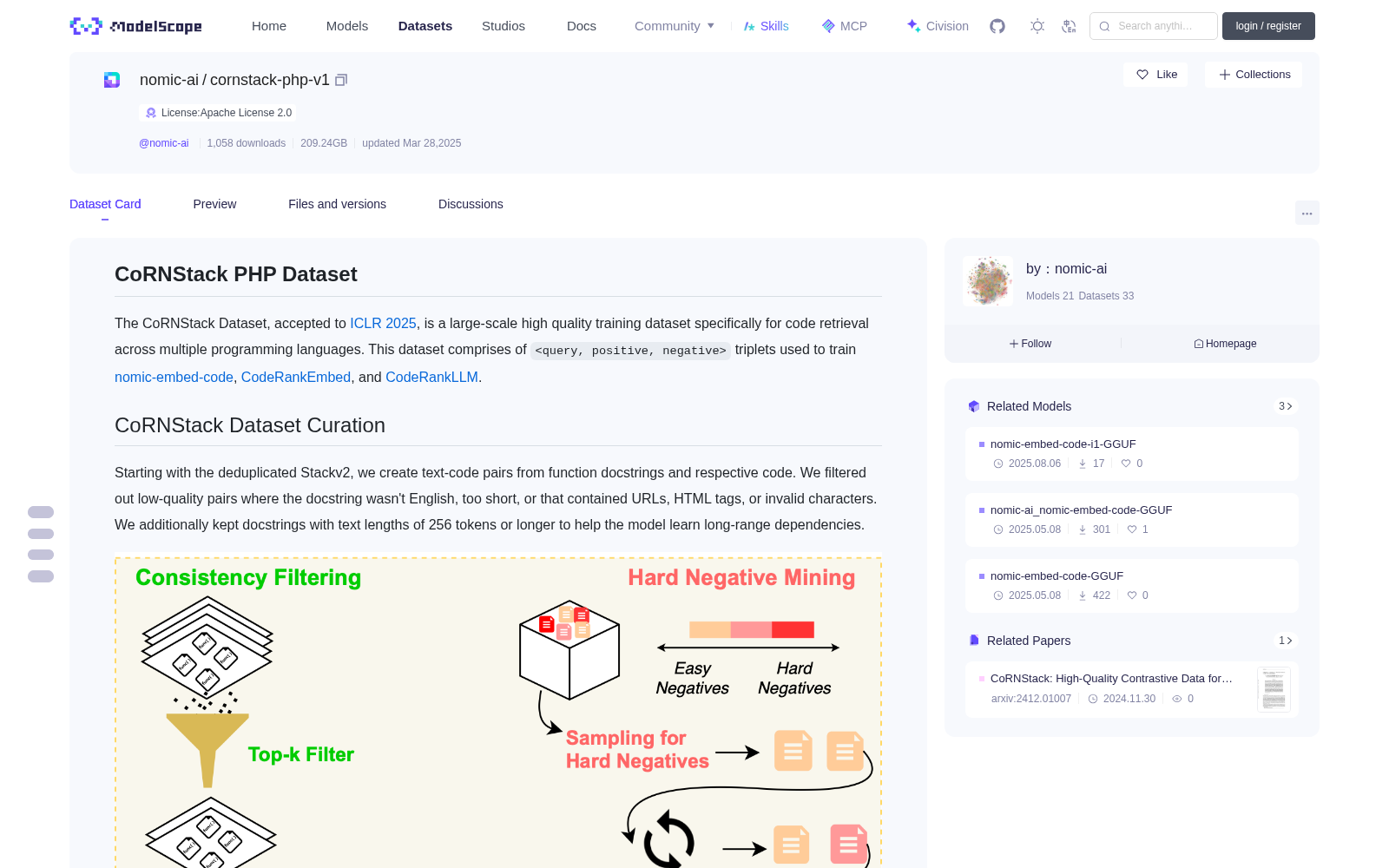
Starting with the deduplicated Stackv2, we create text-code pairs from function docstrings and respective code. We filtered out low-quality pairs where the docstring wasn't English, too short, or that contained URLs, HTML tags, or invalid characters. We additionally kept docstrings with text lengths of 256 tokens or longer to help the model learn long-range dependencies.

After the initial filtering, we used dual-consistency filtering to remove potentially noisy examples. We embed each docstring and code pair and compute the similarity between each docstring and every code example. We remove pairs from the dataset if the corresponding code example is not found in the top-2 most similar examples for a given docstring.
During training, we employ a novel curriculum-based hard negative mining strategy to ensure the model learns from challenging examples. We use a softmax-based sampling strategy to progressively sample hard negatives with increasing difficulty over time.
## Join the Nomic Community
- Nomic Embed Ecosystem: [https://www.nomic.ai/embed](https://www.nomic.ai/embed)
- Website: [https://nomic.ai](https://nomic.ai)
- Twitter: [https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
- Discord: [https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
# Citation
If you find the model, dataset, or training code useful, please cite our work:
```bibtex
@misc{suresh2025cornstackhighqualitycontrastivedata,
title={CoRNStack: High-Quality Contrastive Data for Better Code Retrieval and Reranking},
author={Tarun Suresh and Revanth Gangi Reddy and Yifei Xu and Zach Nussbaum and Andriy Mulyar and Brandon Duderstadt and Heng Ji},
year={2025},
eprint={2412.01007},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.01007},
}
# CoRNStack PHP 数据集
CoRNStack 数据集已被接收至ICLR 2025(https://arxiv.org/abs/2412.01007),是一款专为多编程语言代码检索任务打造的大规模高质量训练数据集。该数据集由用于训练 nomic-embed-code(https://huggingface.co/nomic-ai/nomic-embed-code)、CodeRankEmbed(https://huggingface.co/nomic-ai/CodeRankEmbed)以及 CodeRankLLM(https://huggingface.co/nomic-ai/CodeRankLLM)的`<查询、正样本、负样本>`三元组构成。
## CoRNStack 数据集构建流程
我们以去重后的 Stackv2 数据集为起点,从函数文档字符串(docstring)及其对应的代码中生成文本-代码配对样本。我们会过滤掉低质量配对样本:若文档字符串非英文、长度过短,或包含 URL、HTML 标签与非法字符,则将其剔除。此外,我们保留文本长度不少于 256 个 Token(Token)的文档字符串,以助力模型学习长距离依赖特征。

在初步过滤完成后,我们采用双一致性过滤策略来剔除可能存在噪声的样本。我们对每一组文档字符串与代码配对样本进行嵌入(embedding)操作,并计算每一条文档字符串与所有代码样本之间的相似度。若某一文档字符串对应的代码样本未进入其最相似的前 2 个代码样本之列,则将该配对样本从数据集中移除。
在模型训练阶段,我们采用一种新颖的基于课程学习的难例挖掘策略,确保模型能够从具有挑战性的样本中学习。我们采用基于 Softmax 的采样策略,随着训练进程逐步采样难度递增的难负样本。
## 加入 Nomic 社区
- Nomic 嵌入生态系统:[https://www.nomic.ai/embed](https://www.nomic.ai/embed)
- 官方网站:[https://nomic.ai](https://nomic.ai)
- Twitter:[https://twitter.com/nomic_ai](https://twitter.com/nomic_ai)
- Discord:[https://discord.gg/myY5YDR8z8](https://discord.gg/myY5YDR8z8)
# 引用格式
若您认为本模型、数据集或训练代码对您的研究有所帮助,请引用我们的工作:
bibtex
@misc{suresh2025cornstackhighqualitycontrastivedata,
title={CoRNStack: High-Quality Contrastive Data for Better Code Retrieval and Reranking},
author={Tarun Suresh and Revanth Gangi Reddy and Yifei Xu and Zach Nussbaum and Andriy Mulyar and Brandon Duderstadt and Heng Ji},
year={2025},
eprint={2412.01007},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.01007},
}
提供机构:
maas创建时间:
2025-03-04
搜集汇总
数据集介绍
背景与挑战
背景概述
CoRNStack PHP数据集是一个高质量的大规模代码检索训练数据集,被ICLR 2025接受,包含查询、正例和负例三元组,用于训练嵌入模型。它基于Stackv2去重后,通过过滤低质量文本代码对和双一致性筛选确保数据质量,并采用课程式硬负例挖掘策略提升模型学习效果,由nomic-ai发布,采用Apache 2.0许可证。
以上内容由遇见数据集搜集并总结生成


