MVAD
收藏github2025-12-02 更新2025-12-04 收录
下载链接:
https://github.com/HuMengXue0104/MVAD
下载链接
链接失效反馈官方服务:
资源简介:
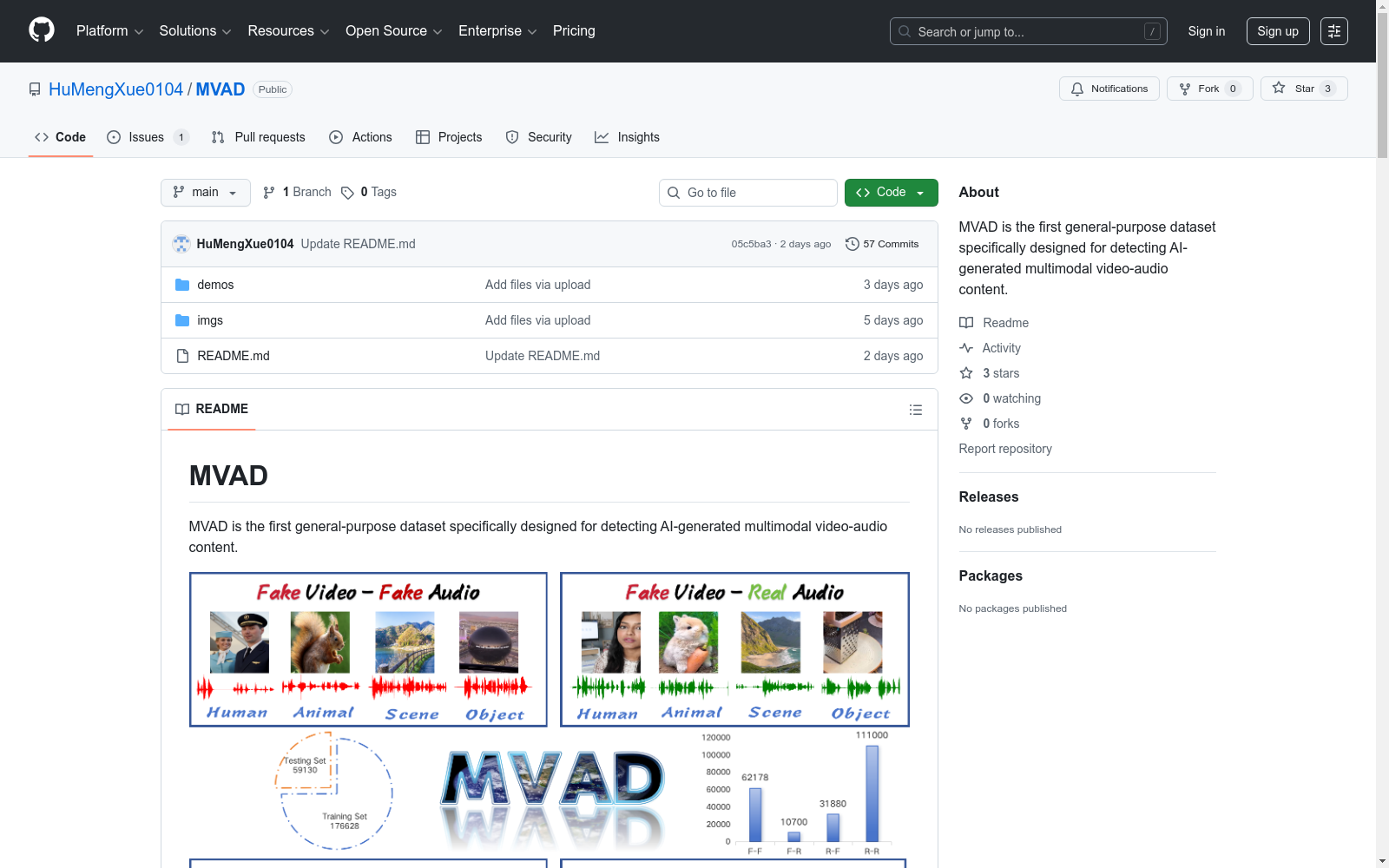
MVAD是首个专门为检测AI生成的多模态视频-音频内容而设计的通用数据集。它涵盖两个视觉领域(写实和动漫风格)和四个主要类别(人类、动物、物体和场景),包含三种视频-音频伪造类型和四种模态组合(假-假、假-真、真-假、真-真)。数据集包含205,758个多模态视频-音频样本,使用超过20种不同方法生成,其中104,578个伪造样本和101,000个真实样本,伪造与真实样本比例为1:1。
MVAD is the first general-purpose dataset specifically designed for detecting AI-generated multimodal video-audio content. It covers two visual domains (realistic and anime styles) and four main categories (humans, animals, objects, and scenes), and includes three types of video-audio forgeries as well as four modality combinations (fake-fake, fake-real, real-fake, real-real). The dataset contains 205,758 multimodal video-audio samples generated by over 20 different methods, among which there are 104,578 forged samples and 101,000 real samples, with a 1:1 ratio between forged and real samples.
创建时间:
2025-11-28
搜集汇总
数据集介绍
构建方式
在人工智能生成内容检测领域,MVAD数据集的构建体现了对多模态视频音频内容的系统性整合。该数据集通过汇聚超过20种不同的生成方法,涵盖了真实与动漫两种视觉风格,并围绕人类、动物、物体和场景四大类别展开。构建过程中,团队精心设计了四种模态组合,包括伪造视频与伪造音频、真实视频与伪造音频、伪造视频与真实音频以及真实视频与真实音频,确保了数据分布的多样性与平衡性。总计205,758个样本中,伪造与真实样本的比例严格遵循1:1的设计原则,为后续的模型训练与评估奠定了坚实基础。
使用方法
针对多模态内容检测任务,MVAD数据集的使用方法主要围绕训练与测试分割展开。数据集已预先划分为训练集与测试集,其中训练集包含176,628个样本,测试集则为59,130个样本,确保了模型评估的独立性与可靠性。研究者可利用这些数据开发与验证检测算法,特别是在处理不同模态组合下的伪造内容时,MVAD提供了多样化的案例支持。数据集预计即将发布,届时用户可通过官方渠道获取,并依据提供的样本类别与模态标签进行针对性的实验设计。
背景与挑战
背景概述
随着生成式人工智能技术的飞速发展,多模态视频-音频内容的合成与伪造能力日益精进,对数字内容的真实性与可信度构成了严峻挑战。在此背景下,MVAD数据集应运而生,成为首个专门针对AI生成多模态视频-音频内容检测而设计的通用型基准数据集。该数据集由HuMengXue等研究人员构建,旨在系统性地应对深度伪造技术在视听领域的扩散问题。其核心研究聚焦于如何有效区分真实与伪造的视频-音频组合,覆盖了人类、动物、物体和场景等多种类别,并囊括了真实-真实、真实-伪造、伪造-真实、伪造-伪造四种模态组合,共计超过20万样本。MVAD的创建填补了多模态伪造检测领域的数据空白,为开发鲁棒的检测模型提供了至关重要的资源,有力推动了数字媒体取证与人工智能安全研究的进展。
当前挑战
MVAD数据集致力于解决多模态视频-音频内容真伪鉴别这一核心领域问题,其面临的首要挑战在于生成技术的快速演进导致伪造内容的多样性与逼真度不断提升,使得检测模型必须应对日益复杂的视听不一致性、细微的伪影以及跨模态关联异常。构建过程中的挑战同样显著,数据收集需统筹来自Sora、Vidu、Pika等超过20种不同生成方法的样本,确保在视觉风格(写实与动漫)、内容类别和模态组合上具有充分的多样性与平衡性。同时,标注工作需要精确区分视频与音频各自的真伪状态及其组合关系,并维持伪造与真实样本的均衡比例,这对数据清洗、验证与标准化流程提出了极高的要求。
常用场景
经典使用场景
在多媒体内容安全领域,MVAD数据集作为首个专为检测AI生成的多模态视频-音频内容而设计的通用数据集,其经典使用场景聚焦于训练和评估先进的深度伪造检测模型。该数据集覆盖了真实与动漫两种视觉风格,并囊括人类、动物、物体和场景四大类别,通过超过20种生成方法构建了20余万样本,其中伪造与真实样本保持均衡比例。研究者可借助其丰富的模态组合(如假视频-假音频、真视频-假音频等),系统性地探索多模态信号中的不一致性特征,从而提升模型在复杂现实环境下的泛化能力与鲁棒性。
解决学术问题
MVAD数据集有效应对了当前多媒体伪造检测研究中数据稀缺与多样性不足的核心挑战。它通过系统整合多种生成技术和模态组合,为学术界提供了标准化的基准测试平台,助力解决多模态内容真伪鉴别中的特征融合、跨模态一致性分析等关键科学问题。该数据集的构建不仅推动了检测算法从单一模态向多模态协同分析的范式转变,也为理解AI生成内容的语义连贯性与物理合理性奠定了实证基础,对维护数字内容的可信度具有深远意义。
实际应用
在实际应用层面,MVAD数据集为社交媒体平台、新闻机构及网络安全系统提供了关键的技术支持。基于该数据集训练的检测模型能够有效识别网络空间中泛滥的深度伪造视频与合成音频,遏制虚假信息传播与身份欺诈行为。在司法取证、版权保护与数字身份验证等领域,此类技术可协助鉴别篡改后的视听证据,保障信息的真实性与完整性,从而维护公共安全与数字生态的健康发展。
数据集最近研究
最新研究方向
在人工智能生成内容检测领域,MVAD数据集作为首个专注于多模态视频-音频伪造检测的通用基准,正推动着前沿研究向跨模态一致性分析深化。随着Sora、Vidu等生成式模型的广泛应用,伪造视频与音频的组合形式日益复杂,该数据集涵盖的四种模态组合(伪造-伪造、真实-伪造、伪造-真实、真实-真实)为探索视听信号间的微妙不一致性提供了丰富素材。研究热点集中于利用多模态融合网络与自监督学习,从时空与频谱维度捕捉生成痕迹,以应对深度伪造技术在社交媒体与新闻传播中的潜在风险。这一进展不仅提升了检测系统的鲁棒性,也为数字内容可信认证奠定了关键数据基础。
以上内容由遇见数据集搜集并总结生成


