CaseLaw Access Project
收藏case.law2024-10-25 收录
下载链接:
https://case.law/
下载链接
链接失效反馈资源简介:
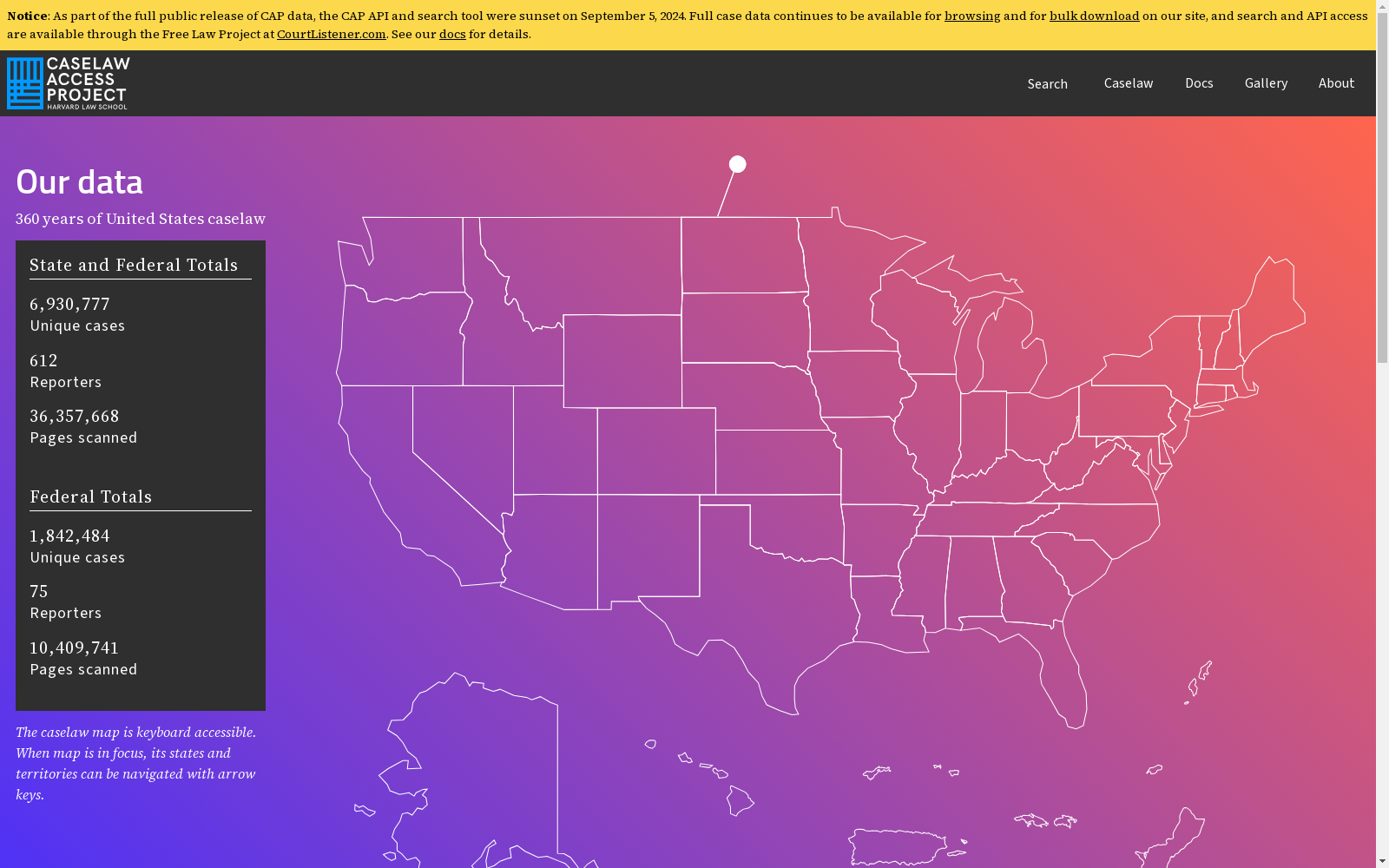
CaseLaw Access Project 是一个包含美国联邦和州法院判决书的数据集,旨在提供对美国法律历史的全面访问。数据集包括从1658年至今的超过640万份判决书,涵盖了所有50个州和联邦法院的判决。
The CaseLaw Access Project is a dataset encompassing U.S. federal and state court opinions, with the goal of providing comprehensive access to the history of American law. The dataset contains over 6.4 million court opinions spanning from 1658 to the present, covering judgments from all 50 U.S. states and federal courts.
提供机构:
case.law
AI搜集汇总
数据集介绍
构建方式
CaseLaw Access Project数据集的构建基于对美国联邦和州法院的公开法律文书进行系统性收集与整理。通过自动化爬虫技术,该数据集从多个法律数据库中提取了大量判决书、诉讼文件及其他相关法律文档。数据清洗过程包括去除冗余信息、标准化文本格式以及标注关键法律术语,确保数据的准确性与一致性。
使用方法
CaseLaw Access Project数据集适用于多种法律研究与分析场景。研究者可以通过关键词搜索、时间筛选以及案件类型分类等方式快速定位所需信息。数据集支持文本挖掘、自然语言处理以及机器学习等高级分析技术,帮助用户从海量法律文书中提取有价值的信息。此外,该数据集还可用于法律教育、政策制定以及司法实践的辅助决策,提升法律工作的效率与准确性。
背景与挑战
背景概述
CaseLaw Access Project(案例法访问项目)由哈佛大学法学院于2018年发起,旨在通过数字化和公开美国联邦法院的判例,促进法律研究和司法透明度。该项目的核心研究问题是如何有效地收集、整理和提供海量的法律文本数据,以便学者、律师和公众能够便捷地访问和分析。这一数据集的创建不仅极大地推动了法律信息技术的进步,还为法律领域的实证研究提供了前所未有的数据支持,从而在法学、社会科学和计算机科学等多个领域产生了深远影响。
当前挑战
CaseLaw Access Project在构建过程中面临诸多挑战。首先,数据集的规模庞大,涵盖了数百万份法律文件,如何高效地进行数据清洗和结构化处理是一大难题。其次,法律文本的复杂性和多样性使得自然语言处理技术的应用面临挑战,尤其是在语义理解和法律术语的准确解析方面。此外,数据隐私和版权问题也是该项目必须解决的重要议题,确保在公开数据的同时保护相关方的合法权益。这些挑战不仅影响了数据集的质量和可用性,也对后续的法律研究和应用提出了更高的技术要求。
发展历史
创建时间与更新
CaseLaw Access Project数据集创建于2015年,由Harvard Law School的Legal Analytics Lab发起。该数据集自创建以来,持续进行更新,以确保数据的时效性和完整性。
重要里程碑
CaseLaw Access Project的一个重要里程碑是其在2018年完成了对美国所有州和联邦法院判决的全文收录,这一成就极大地推动了法律研究和分析的进步。此外,2020年,该项目引入了自然语言处理技术,使得数据集的搜索和分析功能得到了显著提升,进一步促进了法律领域的数字化转型。
当前发展情况
当前,CaseLaw Access Project已成为法律研究领域的重要资源,其数据集不仅被广泛应用于学术研究,还被法律实务界用于案件分析和策略制定。该数据集的持续更新和扩展,确保了其对法律领域发展的持续贡献,尤其是在推动法律信息公开和透明化方面,发挥了不可替代的作用。
发展历程
- CaseLaw Access Project由哈佛大学法学院首次提出,旨在创建一个全面且公开的法律案例数据库。
- 项目正式启动,开始收集和整理美国联邦和州法院的判决文书。
- CaseLaw Access Project发布了其首个公开版本,包含超过640万份法律判决文书,标志着该数据集的初步完成。
- 数据集开始被广泛应用于法律研究、教育和政策分析领域,成为法律学术界的重要资源。
常用场景
经典使用场景
在法律研究领域,CaseLaw Access Project数据集被广泛用于分析和理解美国联邦法院的判例法。研究者利用该数据集进行案例检索、法律文本分析以及判例法的历史演变研究。通过这一数据集,学者们能够深入探讨法律条文的实际应用及其对社会的影响,从而为法律理论和实践提供有力支持。
解决学术问题
CaseLaw Access Project数据集解决了法律研究中长期存在的数据获取和分析难题。它为学者们提供了一个全面、结构化的判例法数据库,使得法律文本的量化分析成为可能。这不仅有助于揭示法律条文的实际应用模式,还为法律改革和政策制定提供了科学依据,推动了法律研究的深入发展。
实际应用
在实际应用中,CaseLaw Access Project数据集被广泛用于法律教育和培训、法律咨询服务以及司法决策支持系统。律师和法律顾问利用该数据集进行案例研究和法律分析,以提供更为精准的法律建议。此外,司法机构也利用这一数据集进行判例法的检索和分析,以辅助司法决策,提高司法效率和公正性。
数据集最近研究
最新研究方向
在法律信息学领域,CaseLaw Access Project数据集的最新研究方向主要集中在法律文本的自动化分析与预测。研究者们利用自然语言处理技术,深入挖掘法律文书中的潜在模式,以提高司法决策的透明度和效率。此外,该数据集还被广泛应用于法律文本的情感分析和主题建模,旨在揭示公众对特定法律问题的态度和观点。这些研究不仅推动了法律科技的发展,也为政策制定者提供了宝贵的数据支持,从而在法律实践中产生了深远的影响。
相关研究论文
- 1The Caselaw Access Project: Making All U.S. Case Law and Subsequent Legal Developments Freely Accessible to the PublicHarvard Law School · 2018年
- 2The Caselaw Access Project: A New Era of Legal ResearchHarvard Law School · 2019年
- 3Legal Text Mining: Opportunities and Challenges in the Caselaw Access ProjectUniversity of Pennsylvania · 2020年
- 4The Impact of Open Access to Case Law on Legal Education and PracticeHarvard Law School · 2021年
- 5Caselaw Access Project: A Comprehensive Analysis of Legal Data AccessibilityUniversity of California, Berkeley · 2022年
以上内容由AI搜集并总结生成


