allenai/quartz
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/allenai/quartz
下载链接
链接失效反馈官方服务:
资源简介:
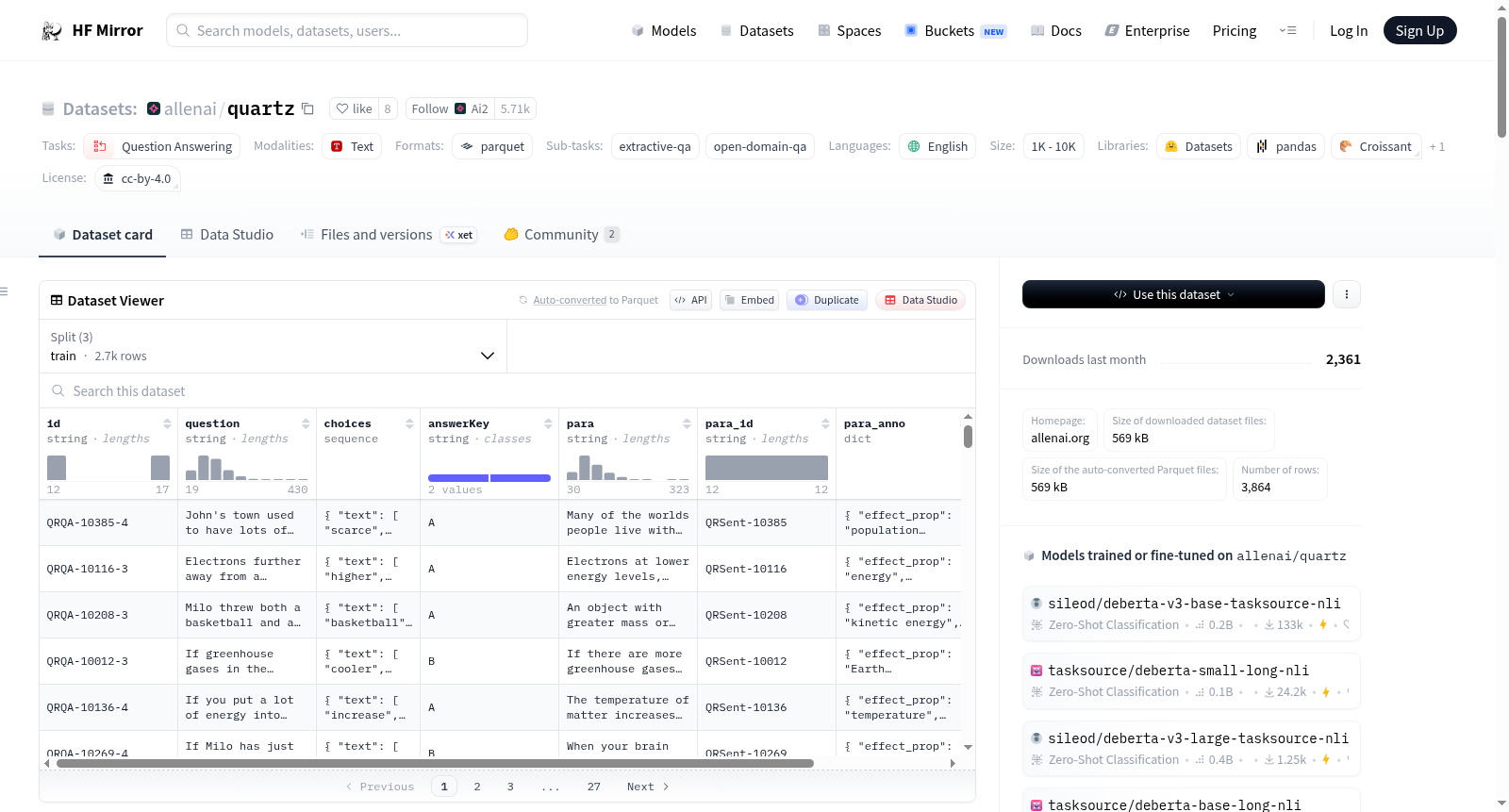
QuaRTz是一个关于开放领域定性关系的多选问题数据集,包含3864个问题,每个问题都与405个不同的背景句子(有时是短段落)配对。数据集分为训练集(2696个问题)、验证集(384个问题)和测试集(784个问题)。每个背景句子只会出现在一个数据集中。数据集的特征包括问题ID、问题文本、选项、答案、背景句子及其注释等。
QuaRTz is a multiple-choice question dataset focused on open-domain qualitative relations. It contains 3864 questions, each paired with 405 distinct background sentences (sometimes short paragraphs). The dataset is partitioned into three splits: a training split with 2696 questions, a validation split with 384 questions, and a test split with 784 questions. Each background sentence appears in exactly one dataset split. Key attributes of the dataset include question IDs, question text, answer options, the correct answer, background sentences and their annotations, among others.
提供机构:
allenai
原始信息汇总
数据集概述
名称: QuaRTz
语言: 英语 (en)
许可证: Creative Commons Attribution 4.0 International (CC BY 4.0)
多语言性: 单语
大小: 1K<n<10K
来源: 原始数据
任务类别: 问答 (question-answering)
任务ID:
- 抽取式问答 (extractive-qa)
- 开放领域问答 (open-domain-qa)
数据集信息:
-
特征:
id: 字符串类型question: 字符串类型choices: 序列类型,包含text: 字符串类型label: 字符串类型
answerKey: 字符串类型para: 字符串类型para_id: 字符串类型para_anno: 结构类型,包含effect_prop: 字符串类型cause_dir_str: 字符串类型effect_dir_str: 字符串类型cause_dir_sign: 字符串类型effect_dir_sign: 字符串类型cause_prop: 字符串类型
question_anno: 结构类型,包含more_effect_dir: 字符串类型less_effect_dir: 字符串类型less_cause_prop: 字符串类型more_effect_prop: 字符串类型less_effect_prop: 字符串类型less_cause_dir: 字符串类型
-
数据分割:
train: 2696 条记录test: 784 条记录validation: 384 条记录
-
下载大小: 569255 字节
-
数据集大小: 1711477 字节
配置:
default配置下,数据文件路径如下:train: data/train-*test: data/test-*validation: data/validation-*
搜集汇总
数据集介绍
构建方式
在开放域定性关系推理领域,QuaRTz数据集的构建体现了众包协作的智慧结晶。该数据集通过系统化流程,汇集了3864道多项选择题,每道题目均围绕定性关系设计,并配以405条背景句子或短段落作为知识支撑。构建过程中,背景句子被精心分配到训练、验证与测试三个独立子集,确保每个句子仅出现在单一划分内,从而有效避免了数据泄露问题,为模型评估提供了可靠基础。
使用方法
该数据集主要应用于问答任务,特别是抽取式与开放域定性关系推理。研究人员可借助标准数据加载工具直接读取划分后的子集,利用背景句子与问题间的关联性,训练模型理解并推断定性变化趋势。通过解析标注中的因果属性与方向信息,能够深化模型对关系逻辑的把握,进而推动开放域推理技术的演进与评估。
背景与挑战
背景概述
在自然语言处理领域,开放域定性关系推理是衡量机器深层语义理解能力的关键任务。由AllenAI研究院于2019年发布的QuaRTz数据集,旨在通过众包方式构建一个包含3864个多项选择题的语料库,专注于探究事物间定性关系的因果与效应逻辑。该数据集的核心研究问题聚焦于模型对开放域背景知识中隐含的定性比较关系进行推理的能力,例如“电子距离原子核越远,其能量水平越高”这类命题。QuaRTz的推出,为推进常识推理与因果推断模型的发展提供了重要的基准资源,尤其在教育技术、智能问答系统等领域展现出潜在的应用价值。
当前挑战
QuaRTz数据集所针对的领域挑战在于,开放域定性关系推理要求模型不仅理解文本表面信息,还需捕捉隐含的因果逻辑与比较关系,这对现有自然语言理解技术构成了显著考验。在构建过程中,数据集的创建面临多重挑战:首先,众包标注需要确保标注者对复杂科学或日常概念中的定性关系具有一致且准确的理解,以维持数据的高质量与可靠性;其次,设计能够全面覆盖多样关系类型(如“更多/更少”、“增加/减少”)的问题与背景句对,需精心策划以避免偏差并保证数据的广泛代表性;此外,如何有效分割数据以确保训练、验证与测试集之间的背景知识无重叠,也是保障模型评估公正性的关键环节。
常用场景
经典使用场景
在自然语言处理领域,定性关系推理是衡量模型深层理解能力的关键维度。QuaRTz数据集以其精心设计的开放域定性关系多选题,为研究者提供了评估模型因果与属性推理性能的经典场景。该数据集通过背景句与问题的配对,要求模型不仅识别文本表层信息,还需推断诸如“更接近导致能量更低”等复杂关系,从而成为测试模型定性推理能力的基准工具。
解决学术问题
该数据集有效应对了自然语言理解中定性关系建模的学术挑战。传统问答系统往往局限于事实性知识检索,而QuaRTz通过标注因果方向、属性变化等结构化信息,促使研究社区开发能够理解“更多”或“更少”等非数值化关系的模型。它推动了从符号推理到神经符号融合的方法演进,为构建具备常识推理能力的人工智能系统提供了关键数据支撑。
实际应用
在实际应用层面,QuaRTz所训练的模型可赋能教育技术、智能辅导系统等领域。例如,在科学教育中,系统能够自动生成或解答关于物理、化学概念的定性比较问题,帮助学生理解“温度升高导致溶解度增加”等抽象关系。此外,在知识图谱的丰富与校验中,模型对定性关系的识别能力可辅助发现并补全实体间的隐含因果链条。
数据集最近研究
最新研究方向
在自然语言处理领域,定性关系推理作为复杂推理任务的重要分支,正逐渐成为研究热点。QuaRTz数据集以其独特的开放领域定性关系问答特性,为模型理解因果与比较关系提供了丰富资源。当前前沿研究聚焦于结合预训练语言模型与符号推理方法,探索如何利用数据集中的结构化标注(如因果方向与属性)提升模型的可解释性与泛化能力。相关研究已延伸至科学教育、常识推理等应用场景,推动人工智能系统在复杂逻辑理解方面取得实质性进展,对构建更具人类思维的智能体具有深远意义。
以上内容由遇见数据集搜集并总结生成


