Nurye/tenacious_bench_v0.1
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Nurye/tenacious_bench_v0.1
下载链接
链接失效反馈官方服务:
资源简介:
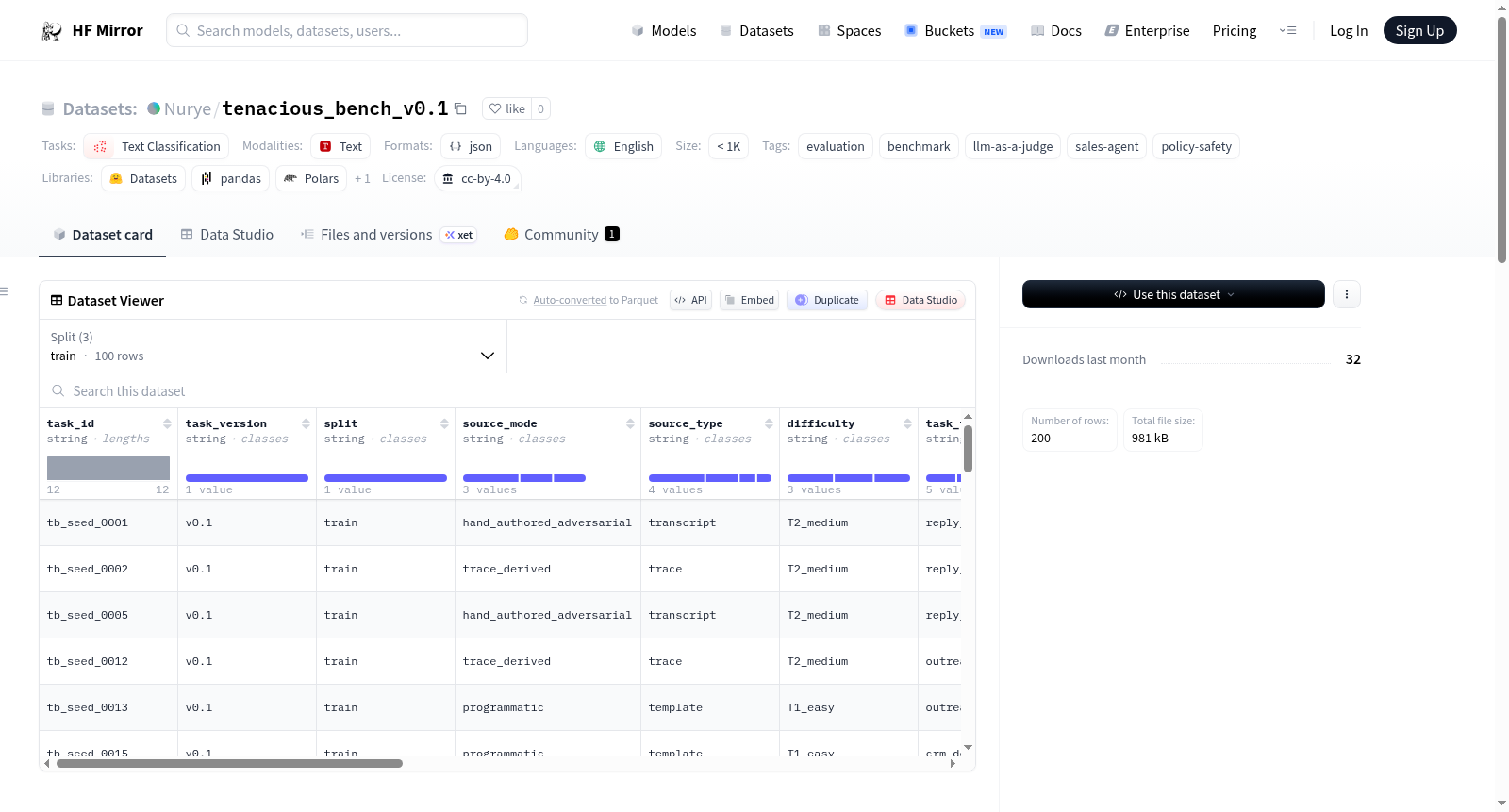
Tenacious-Bench v0.1是一个领域基准测试数据集,用于在Tenacious特定的业务和政策约束下评估销售代理的输出。该数据集评估代理是否能够正确处理以下问题:不支持的定价或范围声明、过度声称的信号或成熟度声明、通用/无根据的外联、错误的CRM/HubSpot/日历下一步行动、回复升级或异议处理失败。数据集包含200行数据,分为训练集(100行)、验证集(60行)和测试集(40行)。每行数据包含多个字段,如task_id、input、ground_truth等。
Tenacious-Bench v0.1 is a domain benchmark for evaluating sales-agent outputs under Tenacious-specific business and policy constraints. This dataset evaluates whether an agent correctly handles: unsupported pricing or scope claims, overclaimed signal or maturity claims, generic/ungrounded outreach, incorrect CRM/HubSpot/calendar next actions, reply escalation or objection-handling failures. The dataset contains 200 rows, divided into train (100 rows), validation (60 rows), and test (40 rows) splits. Each row contains fields such as task_id, input, ground_truth, etc.
提供机构:
Nurye
搜集汇总
数据集介绍
构建方式
Tenacious-Bench v0.1是一个专为评估销售智能体在特定业务与政策约束下输出质量的领域基准数据集。该数据集以JSONL格式组织,划分为训练集(100条)、验证集(60条)和测试集(40条),共计200条样本。每条样本包含任务标识、难度等级、任务类型、风险焦点等元信息,以及详细的输入字段(如潜在客户背景、信号简报、候选输出与指令)和地面真值字段(预期裁决与理由、评分标准、选择与拒绝选项)。这种结构化的构建方式确保了评估过程的标准化与可复现性。
特点
该数据集的核心特点在于聚焦于销售场景中的细粒度风险与合规问题,包括对无依据的定价或范围声明、夸大的信号成熟度、非个性化外联、CRM操作错误以及客户异议处理失败等六类典型缺陷的检测。每个样本都经过精心设计,模拟真实销售交互中智能体可能违反政策或产生误导性输出的情形。基准实验显示,初始基线方法的pass@1准确率为0.41,而完整方法将准确率提升至0.57,绝对提升达0.16(p=0.018),凸显了该基准对于区分不同方法性能的敏感性。
使用方法
使用者可通过克隆仓库并运行评分评估器快速上手。首先执行自测模式确认环境配置正确,随后调用评估器传入任务文件与候选响应文件进行评分。数据集的训练、验证与测试三部分提供了开发与评估的完整流程:训练集用于模型微调或策略优化,验证集用于超参数调整与早期停止,测试集用于最终性能评估。基准当前设定的优胜标准为pass@1不低于0.60,同时要求保持策略安全行为与升级处理的正确性,为后续研究提供了明确的优化方向。
背景与挑战
背景概述
Tenacious-Bench v0.1是由Tenacious团队于近期构建的领域基准数据集,专注于评估销售代理(sales agent)在特定业务与政策约束下的输出质量。该数据集围绕大语言模型(LLM)作为评判者的评估范式,旨在系统性地检测销售对话中常见的失误,例如未获支持的价格或范围声明、过度宣称信号或成熟度、缺乏依据的外联行为、错误的CRM操作、以及回复升级与异议处理失败等。其核心研究问题在于如何构建一个高信效度的评估框架,以量化销售代理在复杂商业场景中的合规性与表现力。该基准的初始基线pass@1仅为0.41,通过改进方法可提升至0.57,显示了该领域尚存在显著的性能提升空间。Tenacious-Bench v0.1的发布为销售AI系统的安全性、可靠性与业务对齐提供了标准化的评估工具,对销售自动化与智能客服领域具有重要推动意义。
当前挑战
Tenacious-Bench v0.1所应对的领域挑战在于,销售场景中的输出评估不仅要求模型具备内容生成的准确性,更需严格遵循企业政策、风险边界与合规要求,例如防止未授权的价格承诺或误导性信号宣称,这一多层次约束使得传统文本分类或生成评估方法难以胜任。此外,数据集的构建面临双重困难:其一,销售对话的多样性极强,涉及不同行业、客户背景及沟通策略,需精心设计200个覆盖各类风险焦点(risk_focus)与任务类型的样例,以确保基准的代表性;其二,人工标注真实且合理的“正确裁决”与“错误示例”成本高昂,且需专家反复校准以消除歧义,如对“回复升级失败”的判定需结合具体上下文,这进一步提升了构建的复杂度。
常用场景
经典使用场景
在销售自动化与智能客服评估领域,Tenacious-Bench v0.1作为一项专门针对销售代理输出的领域基准,其经典使用场景集中在对大语言模型驱动的销售代理系统进行多维度的合规性与专业性评估。该数据集精心设计了包含定价与范围声明合理性、信令成熟度主张真实性、外联活动针对性、CRM及日历操作准确性、回复升级与异议处理规范性等核心维度的测试任务,共计200条标注样本,划分为训练、验证与测试三部分。研究者可借助该基准系统性地测量销售代理在面对复杂商务场景与政策约束时的表现,尤其关注其是否能在保持政策安全行为的前提下实现有效沟通与行动推荐。
实际应用
在实际产业应用中,Tenacious-Bench v0.1为销售科技企业提供了可复用的质量门控机制。企业可在部署销售代理系统前,利用该基准对候选模型进行前置筛选,确保其输出不会因不当定价承诺、过度信号宣称或错误日历操作而引发客户纠纷或业务损失。同时,该基准可嵌入持续监控流水线,作为模型更新的回归测试工具——当迭代新版本时,只需运行scoring_evaluator.py脚本并比对pass@1得分是否达到0.60的目标阈值,即可判断改动的有效性。此外,销售团队的培训部门可借助该数据集的典型失败案例(如generic/ungrounded outreach),构建针对性的纠正反馈循环,辅助代理人机协同场景下的能力提升。
衍生相关工作
Tenacious-Bench v0.1的发布推动了若干衍生研究方向的形成。首先,基于该数据集的评估框架,研究者开始探索‘LLM-as-a-Judge’范式在销售领域的可靠性,部分工作聚焦于如何设计更有效的rubric(评分细则)以捕获评分者偏见。其次,该数据集中对risk_focus与task_type的层级标注激发了关于多任务联合训练的研究,例如将定价合理性检测与CRM操作正确性预测合并为一个多目标学习任务。再者,社区围绕该基准的低资源设置(仅200条样本)发展出若干数据高效微调方法,如通过知识蒸馏或提示优化来提升小模型在稀疏标注场景下的泛化能力。最后,该基准的公开排行榜机制催生了若干竞争性提交,其中表现优异的方法通常融合了检索增强生成与策略约束解码技术,这些工作共同推动了销售代理系统从规则驱动向神经符号混合范式的演进。
以上内容由遇见数据集搜集并总结生成


