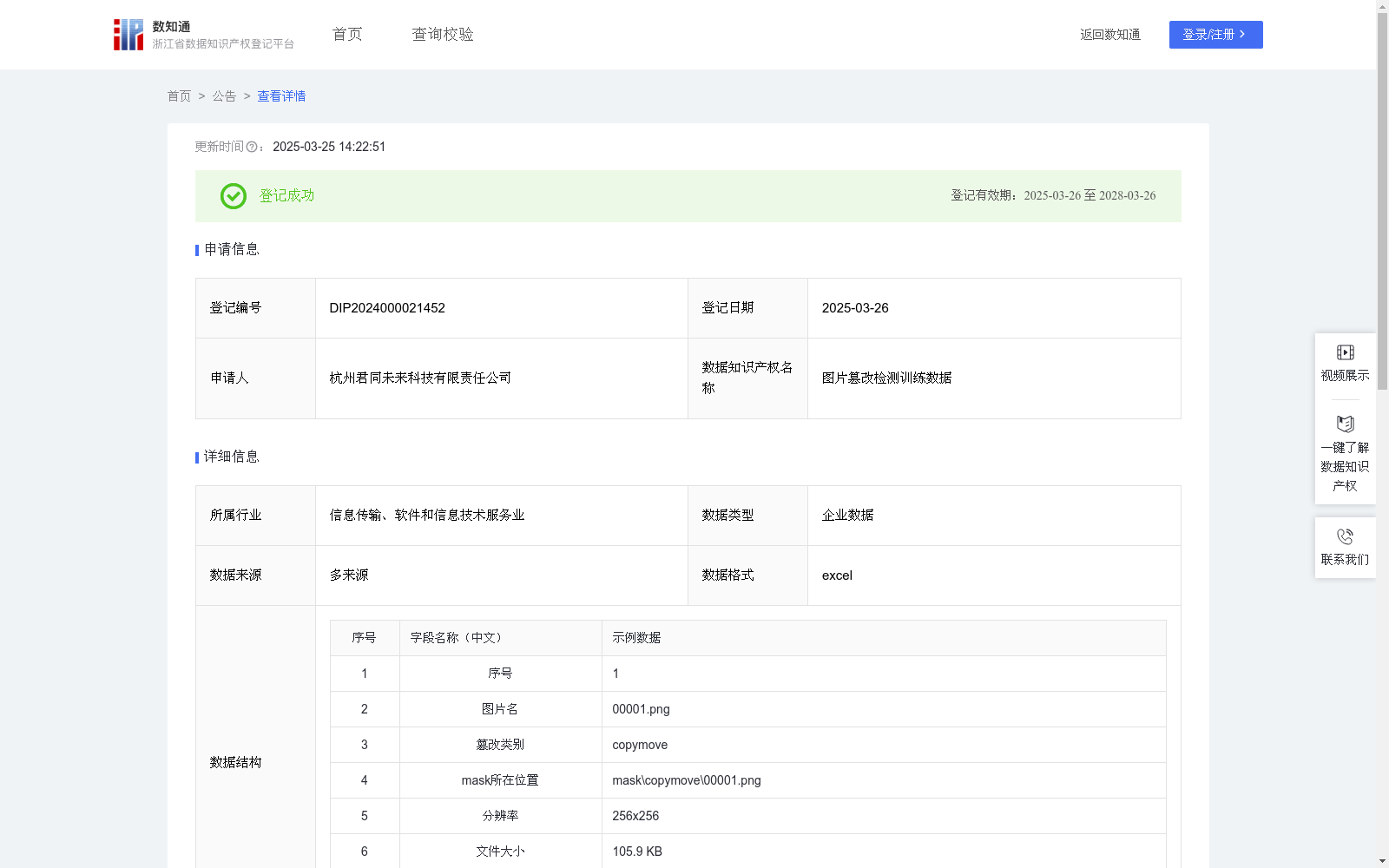
图片篡改检测训练数据
收藏浙江省数据知识产权登记平台2025-03-25 更新2025-03-26 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/119711
下载链接
链接失效反馈官方服务:
资源简介:
通过数据处理和数据加工流程,篡改图片训练数据被转化为高质量、高标注准确性的训练集。这些数据涵盖了不同的篡改手段,包括复制移动、拼接和喷涂等技术,能够为模型提供丰富的训练素材,帮助其深入学习并理解图片篡改的模式与特征。训练后的AI模型能够精准识别各种篡改图片的特征,可以应用于多个场景,例如防止图片伪造、检测恶意篡改的图像、维护媒体平台的内容真实性,以及支持数字版权管理和图像内容监管。(1)数据来源:Image tampering dataset
(2)图片标准化处理:对收集到的图像进行标准化处理,包括缩放到256*256的大小、归一化等。
(3)数据增强:随机旋转图片,改变亮度对比度,随机裁剪、平移、放缩等。
(4)关键视觉特征提取:通过多种方法从图像中提取关键视觉特征,涵盖颜色分布、纹理模式、频域特性、局部二值模式(LBP)、梯度方向直方图(HOG)等,同时关注与伪造图像识别相关的特征,如图像中的几何失真、细节丢失、压缩伪影及不规则光照变化。这些提取的特征为模型提供了丰富的输入信息,使其能够更有效地识别真实图像与经过篡改或合成的图像之间的差异,提升伪造图像检测的准确性和鲁棒性。
(5)深度学习架构选择:基于Non-local网络的深度学习架构,辅以HR-Net进行特征提取工作。
(6)模型训练与评估:高分辨率特征图捕捉局部细节,低分辨率特征图提取全局信息。检测头用四个不同级别的特征图来预测检测分数;渐进机制用特征图生成四个mask。
(7)超参数调优:调节学习率、批量大小、隐藏层维度、注意力头数等参数。
(8)模型优化与验证:构建了独立的测试集对模型进行验证,确保模型在未见数据上也能表现良好。
(3) 关键视觉特征提取:采用多种方法从图像中提取关键视觉特征,涵盖颜色分布、纹理模式、频域特性、局部二值模式(LBP)、梯度方向直方图(HOG)等,同时特别关注与伪造图像识别相关的特征,如几何失真、细节丢失、压缩伪影和不规则光照变化。通过这些特征的提取,模型能够获得丰富的输入信息,从而更精准地识别真实图像与经过篡改或合成的图像之间的差异,提高伪造图像检测的准确性与鲁棒性。
(4) 深度学习架构选择:采用基于Non-local网络的深度学习架构,并结合HR-Net进行特征提取,提升模型的表达能力和精度。
(5) 模型训练与评估:高分辨率的特征图能够捕捉局部细节,低分辨率的特征图则用于提取全局信息。检测头使用四个不同级别的特征图来预测检测分数,而渐进机制则利用这些特征图生成四个mask,以进一步提高检测精度。
(6) 超参数调优:通过调整学习率、批量大小、隐藏层维度、注意力头数等超参数,优化模型性能。
模型优化与验证:构建独立的测试集对模型进行验证,确保模型在未见数据上的表现同样优秀。
Through data processing and refinement workflows, tampered image training data is converted into a high-quality training dataset with high annotation accuracy. This dataset covers various tampering techniques, including copy-move, splicing, and inpainting, providing rich training materials for models to deeply learn and understand the patterns and characteristics of image tampering. The trained AI model can accurately identify various tampered image features, and can be applied to multiple scenarios, such as preventing image forgery, detecting maliciously tampered images, maintaining content authenticity on media platforms, supporting digital rights management, and regulating image content.
(1) Data Source: Image Tampering Dataset
(2) Image Standardization Processing: Standardize the collected images, including resizing to 256×256 pixels and normalization, etc.
(3) Data Augmentation: Perform random rotation, adjust brightness and contrast, random cropping, translation, scaling, and other operations on the images.
(4) Key Visual Feature Extraction: Extract key visual features from images through multiple methods, covering color distribution, texture patterns, frequency-domain characteristics, Local Binary Pattern (LBP), Histogram of Oriented Gradients (HOG), etc., while focusing on features related to forged image recognition, such as geometric distortion, detail loss, compression artifacts, and irregular illumination changes in images. These extracted features provide rich input information for the model, enabling it to more effectively distinguish between real images and tampered or synthesized images, and improving the accuracy and robustness of forged image detection.
(5) Deep Learning Architecture Selection: Adopt a deep learning architecture based on Non-local Neural Networks, supplemented by HR-Net for feature extraction.
(6) Model Training and Evaluation: High-resolution feature maps capture local details, while low-resolution feature maps extract global information. The detection head uses four different levels of feature maps to predict detection scores; the progressive mechanism generates four masks using the feature maps.
(7) Hyperparameter Tuning: Adjust hyperparameters such as learning rate, batch size, hidden layer dimension, and number of attention heads.
(8) Model Optimization and Validation: Construct an independent test set to validate the model, ensuring that the model performs well on unseen data.
(3) Key Visual Feature Extraction: Extract key visual features from images using multiple methods, covering color distribution, texture patterns, frequency-domain characteristics, Local Binary Pattern (LBP), Histogram of Oriented Gradients (HOG), etc., while paying special attention to features related to forged image recognition, such as geometric distortion, detail loss, compression artifacts, and irregular illumination changes. Through the extraction of these features, the model can obtain rich input information, thereby more accurately identifying the differences between real images and tampered or synthesized images, and improving the accuracy and robustness of forged image detection.
(4) Deep Learning Architecture Selection: Adopt a deep learning architecture based on Non-local Neural Networks, combined with HR-Net for feature extraction, to enhance the model's expressive ability and accuracy.
(5) Model Training and Evaluation: High-resolution feature maps can capture local details, while low-resolution feature maps are used to extract global information. The detection head uses four different levels of feature maps to predict detection scores, and the progressive mechanism uses these feature maps to generate four masks to further improve detection accuracy.
(6) Hyperparameter Tuning: Optimize model performance by adjusting hyperparameters such as learning rate, batch size, hidden layer dimension, and number of attention heads.
Model Optimization and Validation: Construct an independent test set to validate the model, ensuring that the model performs equally well on unseen data.
提供机构:
杭州君同未来科技有限责任公司
创建时间:
2024-12-05
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个用于图片篡改检测的训练数据集,包含800条数据,每年更新一次。数据集涵盖了不同的篡改手段,如复制移动、拼接和喷涂等,适用于防止图片伪造、检测恶意篡改图像等场景。数据集采用基于Non-local网络的深度学习架构进行特征提取和模型训练。
以上内容由遇见数据集搜集并总结生成


