MM-Hallu/HEAL-MedVQA
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/MM-Hallu/HEAL-MedVQA
下载链接
链接失效反馈官方服务:
资源简介:
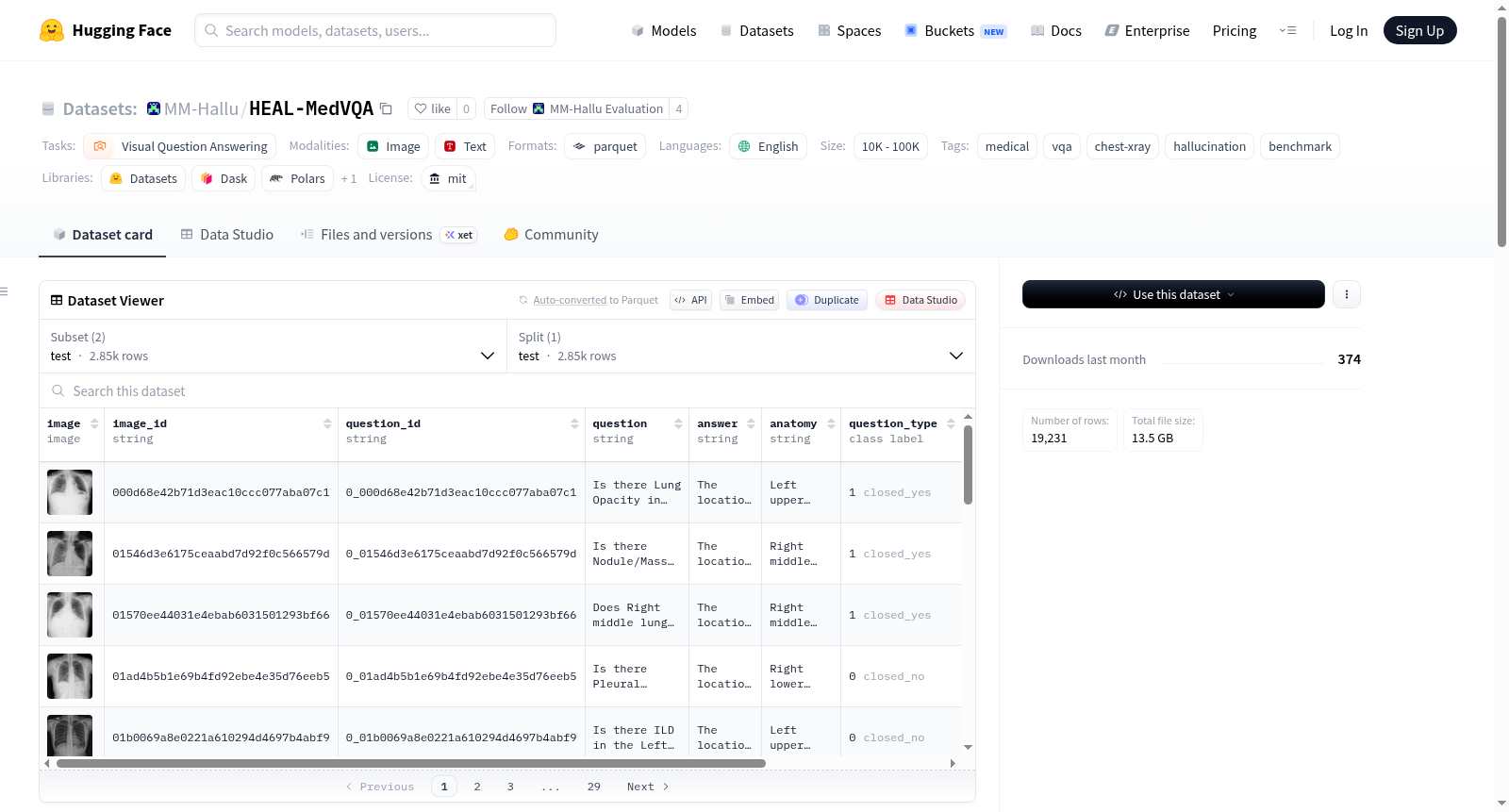
HEAL-MedVQA数据集是MM-Hallu基准集合的一部分,用于评估医学视觉问答(VQA)中的幻觉现象。该数据集基于胸部X光图像,包含封闭式(是/否)和开放式问题,并标注了解剖区域。数据集分为训练集(16,380个样本)和测试集(2,851个样本),总样本数为19,231。数据集字段包括图像、问题ID、问题文本、答案、解剖区域、问题类型等。数据来源为VinDr-CXR。
HEAL-MedVQA is part of the MM-Hallu benchmark collection for evaluating multimodal hallucination in vision-language models. It evaluates medical VQA hallucination on chest X-ray images, including both closed-ended (yes/no) and open-ended questions about radiological findings, with annotated anatomical regions. The dataset contains 16,380 training samples and 2,851 test samples (total 19,231). Fields include image, question_id, question text, answer, anatomy, question_type, etc. Source images are from VinDr-CXR.
提供机构:
MM-Hallu
搜集汇总
数据集介绍
构建方式
HEAL-MedVQA数据集专为评估医学视觉问答中的多模态幻觉现象而构建,聚焦于胸部X光影像的问答任务。该数据集以VinDr-CXR公开胸部X光影像为图像来源,剔除需PhysioNet认证权限的MIMIC-CXR图像,最终整合19,231条样本。每项样本包含嵌入式影像、唯一标识符、问题文本、标准答案、解剖区域标注及分割掩码(以游程编码形式存储)。数据按8:2划分为训练集和测试集,分别容纳16,380和2,851条实例。
使用方法
数据集以Parquet格式存储,支持通过HuggingFace Datasets库便捷加载。用户可通过指定config_name参数' train'或'test'获取对应分片,每条记录包含image、question、answer等字段。模型输入时可组合image与question字段进行多模态推理,利用answer字段计算回答准确率;借助mask_rle、mask_h与mask_w字段可还原分割掩码,实现解剖区域的视觉注意力分析。适用于训练鲁棒的医学VQA模型,或作为基准评估模型在胸部X光问答任务中的幻觉程度。
背景与挑战
背景概述
医疗视觉问答(Medical VQA)旨在通过融合图像理解与自然语言推理,辅助临床决策。然而,现有模型在生成诊断相关回答时频繁产生幻觉(hallucination),严重限制了其临床可信度。为系统评估与缓解这一问题,HEAL-MedVQA数据集应运而生。该数据集创建于近期,由多机构研究团队联合开发,专注于胸部X光影像中的VQA幻觉评估。其核心研究问题在于量化并分析视觉-语言模型在医学场景下产生事实性错误的模式。数据集基于VinDr-CXR公开影像,精心设计了涵盖闭合式(是/否)与开放式(异常/正常)的四类问题,并提供了精细的解剖区域掩码标注。HEAL-MedVQA填补了医学多模态幻觉基准的空白,为构建更可靠、更可解释的临床AI系统提供了关键评估工具。
当前挑战
HEAL-MedVQA致力于应对两大核心挑战:其一,在领域问题层面,医学VQA不同于通用VQA,其回答直接影响诊疗判断,任何事实偏差(如误判病灶存在与否)均可能导致严重临床后果。因此,揭示并量化现有模型在医学影像描述中的幻觉现象,成为提升模型可信任度与落地应用前必须攻克的关键壁垒。其二,在数据集构建过程中,面临多重技术挑战:原始MIMIC-CXR影像因严格的PhysioNet访问限制无法全量获取,导致需依赖VinDr-CXR单一来源,并重新组织问题和掩码;此外,为确保评估的全面性与公平性,需在闭合式与开放式问题间保持平衡,并对异常/正常状态进行细致分类,这要求医学专家深度参与标注与质量审核,显著增加了构建成本与复杂度。
常用场景
经典使用场景
在医学影像分析领域,视觉问答任务要求模型同时理解图像内容与自然语言提问,而胸片作为临床最广泛使用的影像之一,相关模型的可信度至关重要。HEAL-MedVQA数据集专为评估医学视觉问答中的幻觉现象而设计,涵盖闭合式与开放式问题,并附带解剖区域标注,使其成为检验模型在医学图像生成答案时是否忠实于影像事实的核心基准。该数据集的经典使用场景在于系统性地判断多模态大语言模型在回答关于胸部X光片的问题时,是否会产生与影像证据不符或虚构的回复,从而为模型的临床可靠性提供关键度量。
解决学术问题
当前多模态模型在医学影像问答中常出现“幻觉”现象,即生成看似合理但实际与影像不符的答案,这对高风险临床应用构成严重威胁。HEAL-MedVQA首次从细粒度层面关注并量化了该问题,通过整合闭合式和开放式问答,以及解剖区域标签,推动了幻觉检测与归因的研究。该数据集解决了如何精确识别模型在哪些类型的医学问题上更易产生幻觉、幻觉是否与特定解剖位置相关等学术难题,其发布引领了医疗领域多模态模型鲁棒性和可解释性评估的新方向,具有深远的学术价值。
实际应用
在实际临床辅助诊断场景中,胸部X光片是筛查肺炎、肺结节、心脏肥大等疾病的首选手段。HEAL-MedVQA可被部署为模型上线前的“安全测试床”,帮助研发人员筛选出那些在回答阴性发现或异常描述时容易编造信息的不可靠模型。此外,该数据集能够用于训练幻觉检测模块,使得在放射科医生使用基于AI的读片辅助系统时,系统能够主动标记出可能含有幻觉成分的文本回复,从而降低误诊风险,提升医学影像报告生成系统的实用性与可信度。
数据集最近研究
最新研究方向
在医学视觉问答领域,HEAL-MedVQA数据集聚焦于评估和缓解视觉语言模型在胸部X光片分析中的多模态幻觉现象,这是当前AI医疗可解释性与安全性研究的前沿热点。通过构建包含闭合式(是/否)与开放式(异常/正常)问题的双重评测体系,并精细标注解剖部位,该数据集不仅揭示了模型在放射学报告生成中虚构发现的风险,还为设计抗幻觉机制提供了标准化的量化基准。其基于VinDr-CXR真实影像与MIMIC-CXR参考标识的混合来源,结合针对不同类型问题的分层统计,使得研究者能够深入剖析模型在临床问答中错误的模式与解剖分布,从而推动更可信赖的医学诊断辅助系统的发展。
以上内容由遇见数据集搜集并总结生成


