synthetic-from-retrieval-tasks-swedish
收藏Hugging Face2025-01-31 更新2025-02-10 收录
下载链接:
https://huggingface.co/datasets/ThatsGroes/synthetic-from-retrieval-tasks-swedish
下载链接
链接失效反馈官方服务:
资源简介:
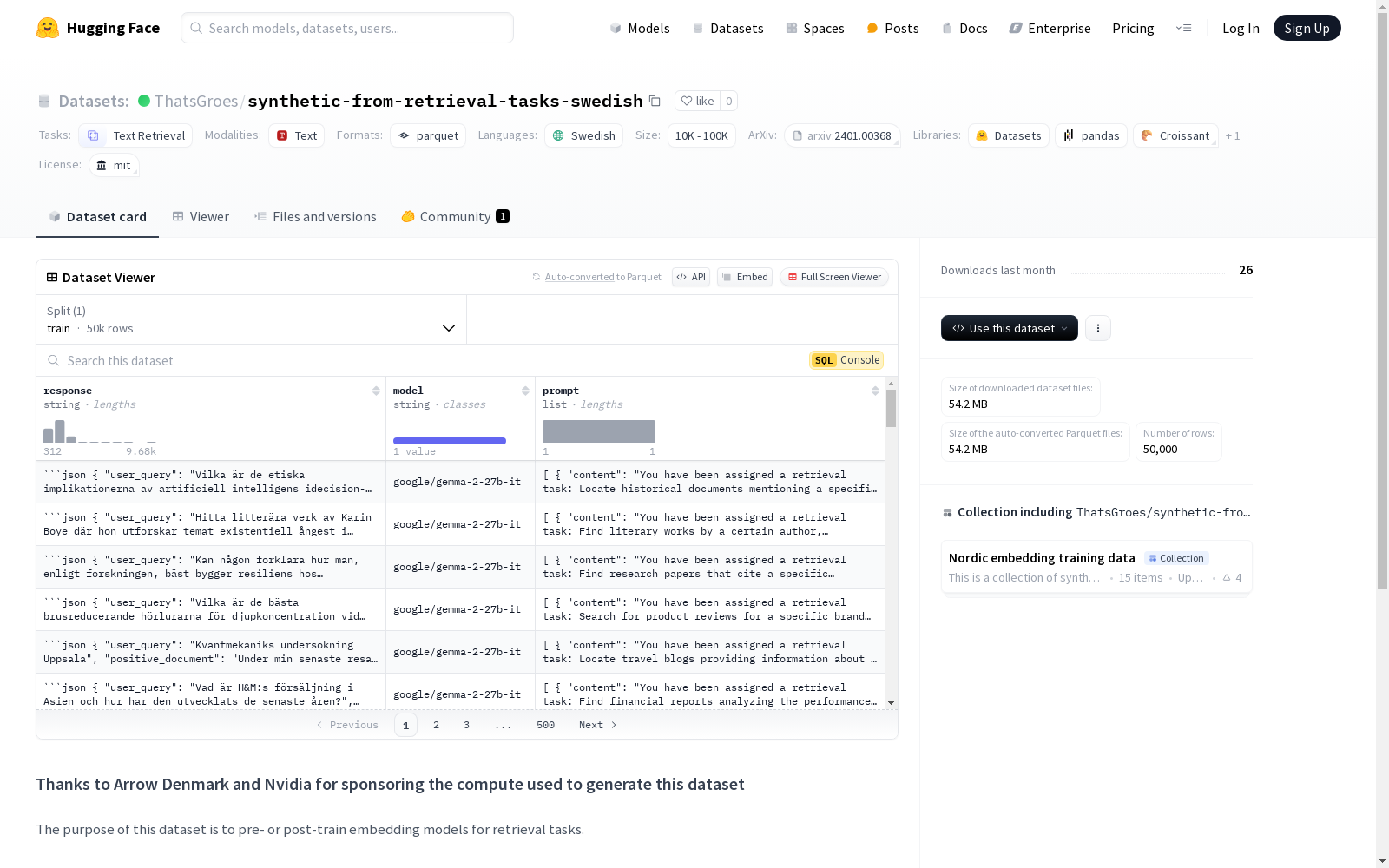
该数据集的主要目的是用于检索任务的嵌入模型的预训练或后训练。数据集包含100,000个样本,这些样本是通过gemma-2-27b-it模型生成的。每个样本的'prompt'列显示了给LLM的提示,而'response'列显示了LLM的输出。数据集的生成过程遵循了特定论文中描述的方法。
The primary purpose of this dataset is for pre-training or post-training of embedding models for retrieval tasks. This dataset contains 100,000 samples generated using the gemma-2-27b-it model. For each sample, the 'prompt' column displays the input prompt given to the LLM, while the 'response' column shows the output generated by the LLM. The dataset creation process follows the methodology described in a specific academic paper.
创建时间:
2025-01-25
原始信息汇总
数据集概述
数据集名称
ThatsGroes/synthetic-from-retrieval-tasks-swedish
数据集特点
-
特征:
response:字符串类型model:字符串类型prompt:content:字符串类型role:字符串类型
-
数据划分:
- 训练集(train):157,185,409 字节,共 50,000 个样本
-
下载大小:54,152,645 字节
-
数据集大小:157,185,409 字节
-
配置:
default:- 训练集文件路径:data/train-*
-
许可证:MIT
-
任务类别:文本检索(text-retrieval)
-
语言:瑞典语(sv)
数据集描述
本数据集旨在用于预训练或后训练用于检索任务的嵌入模型。数据集包含 100,000 个样本,使用 gemma-2-27b-it 生成。每个样本由从 ThatsGroes/retrieval-tasks-processed 随机抽取的种子任务生成,遵循 此论文 中描述的数据生成过程。计算资源由 Arrow Denmark 和 Nvidia 通过 Danish Data Science Community 赞助。
搜集汇总
数据集介绍
构建方式
该数据集的构建基于大规模语言模型gemma-2-27b-it生成的100,000个样本。其构建过程遵循特定论文中描述的数据生成方法,以种子任务的形式从特定数据源中随机采样,进而形成包含提示(prompt)与相应输出(response)的样本对。
特点
此数据集专为预训练或后训练用于检索任务的嵌入模型而设计。其特色在于采用瑞典语(sv)作为语言,且具备明确的任务类别,即文本检索(text-retrieval)。此外,数据集遵循MIT许可证,确保了使用的灵活性与开放性。
使用方法
使用该数据集时,用户需关注其包含的两个主要字段:提示(prompt)与模型输出(response)。通过训练,模型应学会根据给定的提示生成恰当的输出。数据集分为训练集,便于用户进行模型的预训练或后训练操作。
背景与挑战
背景概述
synthetic-from-retrieval-tasks-swedish数据集,诞生于现代自然语言处理研究领域,旨在为检索任务的嵌入模型进行预训练或后训练提供高质量的数据支持。该数据集由Arrow Denmark和Nvidia赞助计算资源生成,包含100,000个样本,均由gemma-2-27b-it模型生成。数据集的核心在于提供LLM输出与提示之间的对应关系,以助力提升模型在文本检索任务中的表现。该数据集的研究背景深受学术界和工业界的关注,为相关领域的研究提供了有力的数据支撑。
当前挑战
在构建synthetic-from-retrieval-tasks-swedish数据集的过程中,研究人员面临了多重挑战。首先,如何保证生成的样本能够有效模拟真实场景中的检索任务,是数据集构建的关键。其次,数据集在生成过程中需要处理大量随机采样的种子任务,这要求算法具有较高的稳定性和泛化能力。此外,数据集的构建还需考虑到计算资源的高效利用,以确保数据质量和生成效率的双重优化。在领域问题上,数据集旨在解决文本检索任务中的准确性和效率问题,这对于提升自然语言处理模型在实际应用中的表现具有重要意义。
常用场景
经典使用场景
在自然语言处理领域,合成数据集的应用尤为关键。synthetic-from-retrieval-tasks-swedish数据集便是针对文本检索任务而构建的,其经典的使用场景在于为预训练或后训练嵌入模型提供丰富的训练样本,以提升模型在检索任务中的表现。
实际应用
实际应用中,该数据集可用于提升信息检索系统的性能,尤其是在处理具有特定语言和文化背景的文本数据时。这对于构建更为智能、高效的信息检索工具至关重要,能够满足用户在多语言环境下的检索需求。
衍生相关工作
基于此数据集,研究者们已开展了一系列相关工作,包括但不限于嵌入模型的优化、检索算法的改进以及跨语言检索能力的提升,这些工作进一步推动了文本检索技术的进步,并拓展了其在多领域的应用范围。
以上内容由遇见数据集搜集并总结生成


