DATBENCH; DATBENCH-FULL
收藏arXiv2026-01-06 更新2026-01-07 收录
下载链接:
https://huggingface.co/datasets/DatologyAI/DatBench
下载链接
链接失效反馈官方服务:
资源简介:
DATBENCH是由DatologyAI团队构建的视觉语言模型(VLM)评估套件,包含33个精选数据集,覆盖图表理解、文档解析、空间推理等9大核心能力。该数据集通过转换和过滤原始基准数据,解决了多选题格式偏差、视觉无关样本(占比高达70%)和错误标注(部分数据集噪声达42%)等问题,提升评估的忠实性与判别力。其高效子集DATBENCH可实现13倍加速(最高50倍),同时保持与原数据集相当的判别性能,适用于快速迭代和真实场景下的多模态能力验证。
DATBENCH is a vision-language model (VLM) evaluation suite developed by the DatologyAI team, which includes 33 curated datasets covering nine core capabilities such as chart understanding, document parsing, and spatial reasoning. By transforming and filtering raw benchmark data, this suite addresses key issues including multiple-choice format bias, visually irrelevant samples (accounting for up to 70% of the total), and incorrect annotations (with noise levels reaching 42% in some datasets), thereby improving the fidelity and discriminative power of model evaluations. Its efficient subset enables up to 13-fold speedup (maximum 50-fold), while retaining comparable discriminative performance to the original dataset, making it applicable for rapid iteration and multimodal capability validation in real-world scenarios.
提供机构:
DatologyAI Team
创建时间:
2026-01-06
原始信息汇总
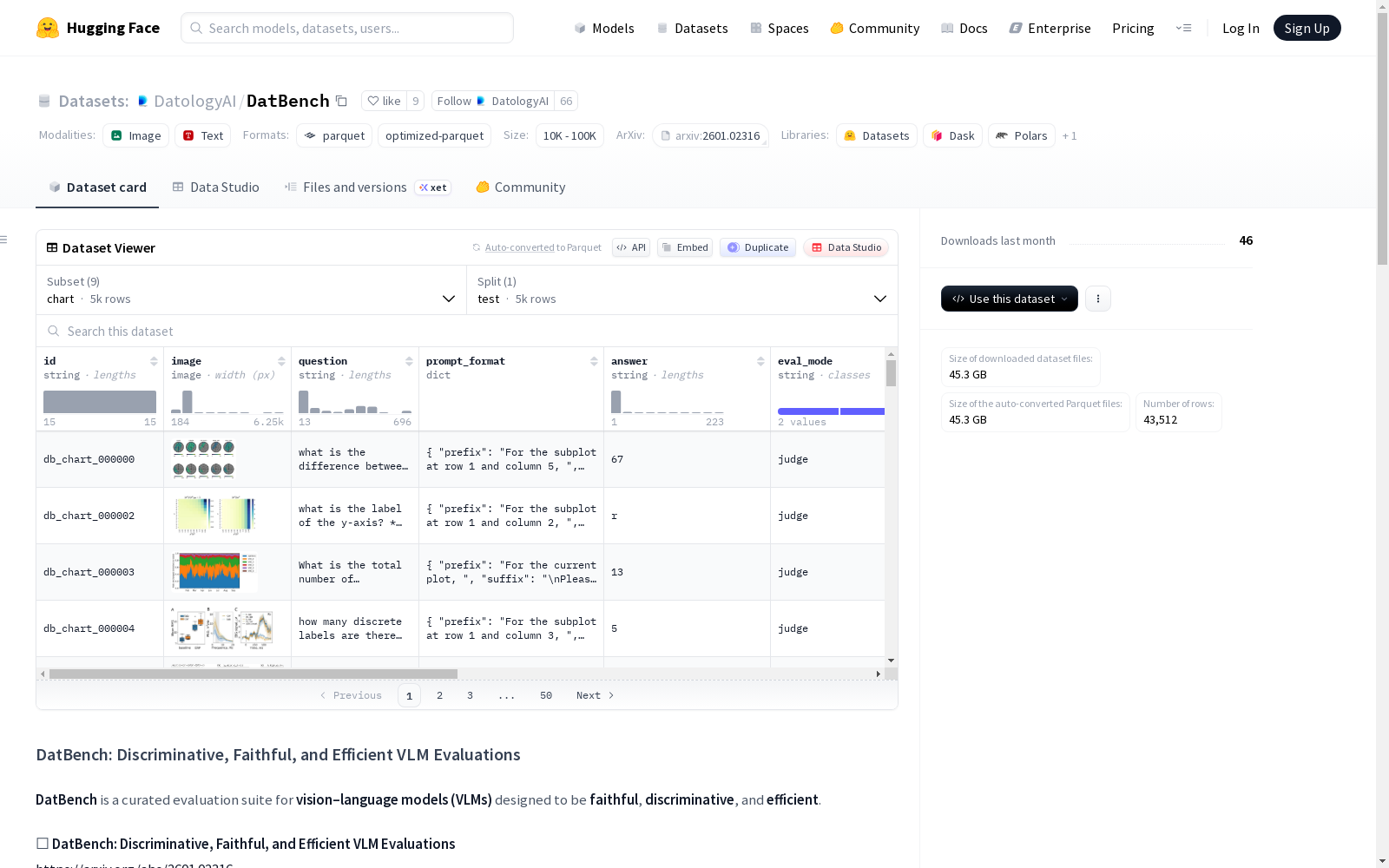
DatBench 数据集概述
数据集基本信息
- 数据集名称: DatBench
- 发布者: DatologyAI
- 主要用途: 用于评估视觉-语言模型(VLMs)的基准测试套件
- 核心特点: 具备忠实性、判别性和高效性
- 相关论文: DatBench: Discriminative, Faithful, and Efficient VLM Evaluations
数据集构成与配置
数据集包含9个不同的配置(config),每个配置对应一种核心能力评估。
配置详情
-
chart
- 样本数量: 5,000
- 数据集大小: 3,675,986,701 字节
- 下载大小: 3,671,014,921 字节
-
counting
- 样本数量: 5,000
- 数据集大小: 1,734,490,422 字节
- 下载大小: 1,732,990,162 字节
-
document
- 样本数量: 5,000
- 数据集大小: 1,170,706,564 字节
- 下载大小: 1,169,470,581 字节
-
general
- 样本数量: 5,000
- 数据集大小: 1,384,920,665 字节
- 下载大小: 1,375,167,714 字节
-
grounding
- 样本数量: 5,000
- 数据集大小: 2,563,334,074 字节
- 下载大小: 2,556,987,602 字节
-
math
- 样本数量: 5,000
- 数据集大小: 280,534,186 字节
- 下载大小: 271,093,089 字节
-
scene
- 样本数量: 5,000
- 数据集大小: 22,245,707,386 字节
- 下载大小: 22,246,418,272 字节
-
spatial
- 样本数量: 3,512
- 数据集大小: 7,523,338,552 字节
- 下载大小: 7,522,636,286 字节
-
table
- 样本数量: 5,000
- 数据集大小: 4,753,003,141 字节
- 下载大小: 4,749,378,300 字节
数据特征
所有配置共享相同的特征结构:
- id: 样本标识符 (string)
- image: 图像数据 (image)
- question: 问题文本 (string)
- prompt_format: 提示词格式结构体
prefix: 前缀 (string)suffix: 后缀 (string)
- answer: 答案 (string)
- eval_mode: 评估模式 (string)
- judge_prompt: 评判提示词 (string)
- is_circular: 是否为循环问题 (bool)
- source_info: 来源信息结构体
dataset: 原始数据集名称 (string)original_idx: 原始索引 (string)
- eval_metrics: 评估指标结构体
discrimination: 区分度分数 (float64)is_frontier: 是否为前沿样本 (bool)
- all_answers: 所有可能答案列表 (list of string)
- metadata: 元数据 (string)
数据划分
所有配置仅包含一个数据划分:
- 划分名称: test
- 用途: 模型测试与评估
数据集构建方法
数据集通过一个四阶段的筛选流程构建,应用于33个广泛使用的VLM基准测试:
- 多项选择题转生成式问题: 消除猜测基线,揭示隐藏的能力差距。
- 盲解性过滤: 移除无需图像即可解答的问题。
- 使用VLM作为评判者进行质量过滤: 丢弃不正确、模糊或低分辨率的样本。
- 判别性子集选择: 保留具有高项目区分度的样本,以最大化每个标记的信号。
数据集变体
- DatBench (高效子集): 高信号、高效率的评估集,相比原始基准测试平均加速约13倍,适用于训练循环、消融实验和快速迭代。
- DatBench-Full (完整清理套件): 包含经过前三阶段筛选后保留的所有高质量样本,更大更全面,适用于最终报告、深度错误分析和全面能力评估。
评估工具
官方提供了评估工具,包含标准化的提示、评分和报告功能。
- 评估代码仓库: https://github.com/datologyai/DatBench
搜集汇总
数据集介绍
构建方式
在视觉语言模型评估领域,传统基准普遍存在数据质量缺陷与计算效率低下等问题。DATBENCH的构建采用了一套系统化的四阶段数据策展流程:首先,将多项选择题转换为开放式生成任务,以消除猜测偏差并揭示模型真实生成能力;其次,通过移除图像输入进行盲测,严格过滤仅凭语言先验即可解答的样本,确保评估真正依赖视觉理解;随后,利用前沿视觉语言模型作为裁判,对全体模型均回答错误的样本进行两阶段质量审查,剔除标注错误、歧义或图像分辨率不足的样本;最终,基于点二列相关系数从各能力维度中精选高区分度的样本子集,在保持排序一致性的同时最大化每个样本的信息密度。
使用方法
DATBENCH为不同评估场景提供了明确的使用指引。研究者在进行模型训练循环或消融实验等高迭代频率任务时,应优先采用高效版的DATBENCH子集,以极低的计算成本获取高区分度的性能信号,从而加速开发进程。当需要进行最终模型报告或深入的错误分析时,则推荐使用完整的DATBENCH-FULL数据集,该版本包含了经过严格质量过滤的全部高质量样本,能够提供最全面的能力覆盖与细粒度评估。两个版本共同构成了一套从快速迭代到最终报告的完整评估体系,有效推动了视觉语言模型评估向更精准、更高效的方向演进。
背景与挑战
背景概述
DATBENCH与DATBENCH-FULL是由DatologyAI团队于2026年提出的视觉语言模型(VLM)评估基准套件,旨在应对当前VLM评估中存在的关键缺陷。该数据集聚焦于提升评估的忠实性、判别性与效率三大核心诉求,通过系统化地转化与筛选现有33个数据集,覆盖图表理解、文档解析、场景OCR、数学逻辑、空间推理等九大VLM能力维度。其创建背景源于现有评估方法普遍存在的多重选择题格式失真、语言先验干扰、标注噪声以及计算成本高昂等问题,严重阻碍了对模型真实多模态推理能力的准确衡量。DATBENCH的推出标志着评估范式从被动度量向主动数据治理的转变,为VLM研究的健康发展提供了严谨且可持续的测量工具。
当前挑战
DATBENCH致力于解决视觉语言模型评估领域的核心挑战。在领域问题层面,其首要挑战在于如何精准度量模型的多模态理解能力,避免因语言先验或格式偏差导致的性能虚高,例如多项选择题的猜测奖励机制可能掩盖高达35%的生成能力差距。构建过程中的挑战则体现为多维度数据治理难题:需将封闭式选择题转化为生成式任务以提升忠实性,识别并剔除高达70%的可仅凭文本解答的样本以确保视觉依赖性,通过VLM作为裁判的多阶段过滤流程清除最多42%的标注错误或模糊样本以降低评估噪声,并基于点二系列相关性的判别性样本选择机制在保持排名稳定的前提下实现最高50倍的计算加速。这些技术挑战共同指向评估数据质量与效率间的根本性权衡。
常用场景
经典使用场景
在视觉语言模型(VLM)的评估领域,DATBENCH 数据集被广泛用于系统性地衡量模型在九大核心能力上的表现,包括图表理解、文档解析、场景文字识别、数学逻辑推理、空间关系理解、目标定位、物体计数、图表表格解读以及通用视觉问答。其经典使用场景在于为研究社区提供一个经过严格筛选和转换的高质量评估基准,通过将传统选择题转换为生成式任务、过滤可仅凭语言先验解答的样本,并剔除标注错误或模糊的示例,确保评估结果真实反映模型的多模态理解能力,而非测试集本身的偏差或噪声。
解决学术问题
DATBENCH 主要解决了当前 VLM 评估中普遍存在的三个关键学术问题:评估的忠实性、区分性和效率性。传统基准常因选择题格式、语言先验可解样本以及标注噪声而导致模型能力被高估或混淆,无法准确区分不同性能层次的模型。该数据集通过系统性的数据转换与过滤,显著提升了评估的忠实度,确保测试真正依赖视觉输入;同时基于项目区分度理论优化样本选择,增强了评估的区分能力,使细微的性能差异得以显现;此外,其高效子集 DATBENCH 在保持区分力的前提下,实现了平均13倍的评估加速,有效缓解了大规模模型评估带来的巨大计算负担。
实际应用
在实际应用层面,DATBENCH 为工业界和学术界的模型开发与迭代提供了高效可靠的评估工具。其高效子集 DATBENCH 适用于训练循环和消融研究等需要快速迭代的场景,大幅降低评估成本;而完整版本 DATBENCH-FULL 则用于最终模型报告和深入的错误分析,提供全面的能力覆盖。该数据集帮助研发团队更精准地诊断模型在感知与推理之间的权衡、测试时计算扩展带来的“过度思考”惩罚,以及语言先验对多模态性能的掩盖效应,从而指导模型架构优化、训练数据策展和部署策略的制定。
数据集最近研究
最新研究方向
在视觉语言模型评估领域,DATBENCH与DATBENCH-FULL数据集标志着评估范式从规模导向向质量导向的深刻转变。该研究聚焦于解决现有基准中普遍存在的忠实性、判别性与效率失衡问题,通过系统性的数据筛选与转换机制,如将多项选择题转化为生成式任务、剔除仅依赖语言先验可解的样本,以及基于点二列相关系数的高判别性子集选择,显著提升了评估的精度与信噪比。这些方法不仅揭示了模型在生成式场景下高达35%的隐性能力落差,还通过平均13倍的加速比实现了高效评估,为应对模型规模持续扩展带来的计算挑战提供了可行路径。当前,该数据集正推动研究社区深入探索模型在推理与感知任务间的本质权衡、推理时计算扩展对感知性能的负面影响,以及语言先验对多模态能力真实度量的干扰,从而为下一代视觉语言模型的开发与评估奠定了更为严谨的基准基础。
相关研究论文
- 1DatBench: Discriminative, Faithful, and Efficient VLM EvaluationsDatologyAI Team · 2026年
以上内容由遇见数据集搜集并总结生成


