Gurbani_darpan
收藏Hugging Face2024-11-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/singhjagpreet/Gurbani_darpan
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于问答任务的小型旁遮普语数据集,数据量小于1K。
创建时间:
2024-11-25
原始信息汇总
Gurbani_darpan 数据集概述
任务类别
- 问答系统 (question-answering)
语言
- 旁遮普语 (pa)
数据集规模
- 小于1千条数据 (n<1K)
搜集汇总
数据集介绍
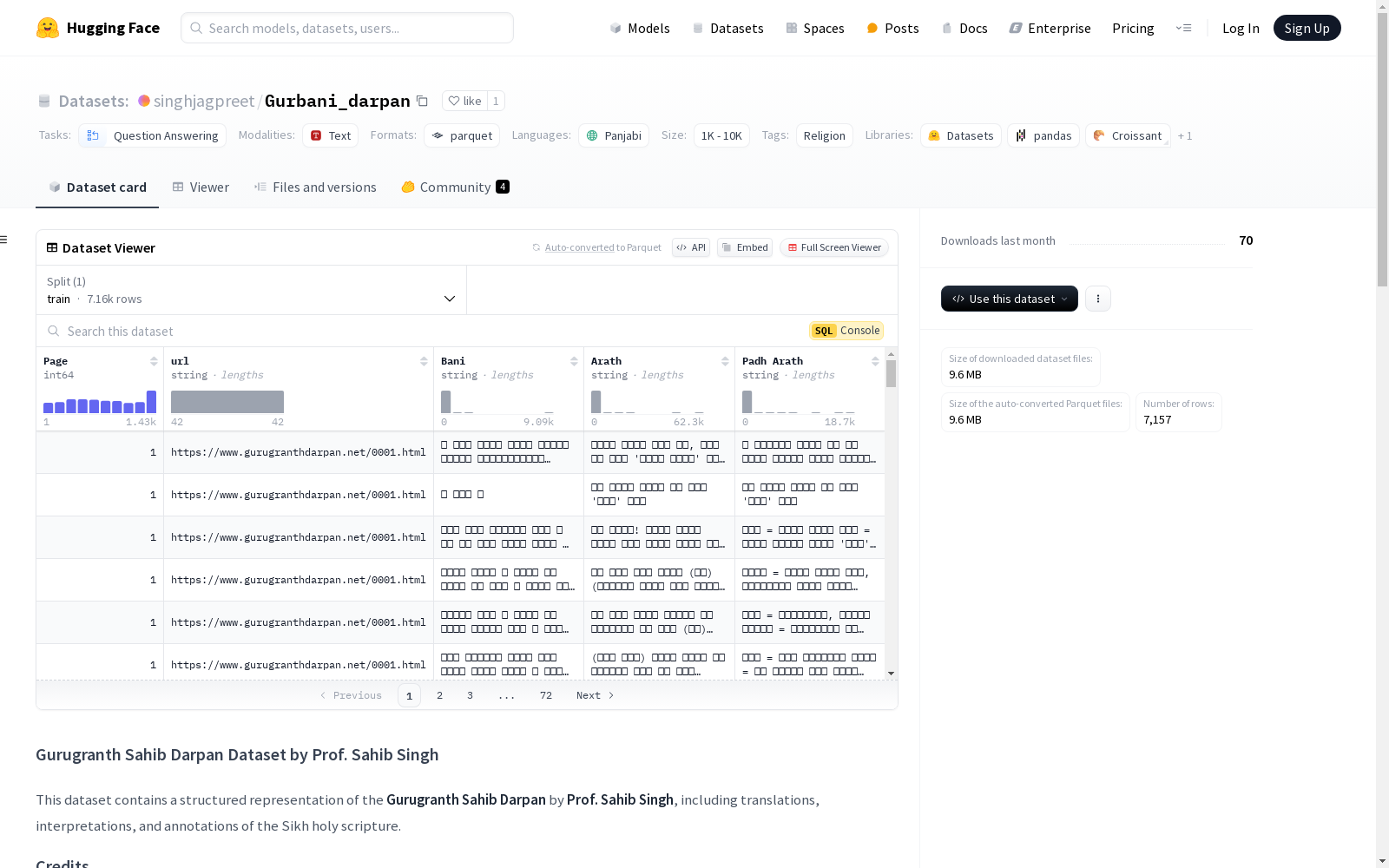
构建方式
Gurbani_darpan数据集的构建基于Prof. Sahib Singh的著作《Gurugranth Sahib Darpan》,该著作是对锡克教圣典《Gurugranth Sahib》的翻译、解释和注释。数据集通过从https://www.gurugranthdarpan.net/darpan.html网页上抓取内容,经过结构化处理后,以JSON、CSV或纯文本格式呈现。这一过程确保了数据的完整性和可访问性,为后续的自然语言处理研究提供了坚实的基础。
特点
Gurbani_darpan数据集的特点在于其多语言性,涵盖了旁遮普语(古尔穆奇文)和英语两种语言。数据集不仅包含了圣典的原文,还提供了详细的翻译和解释,使得研究者能够深入理解文本的宗教和文化背景。此外,数据集的格式灵活,支持JSON、CSV和纯文本,便于不同研究需求的使用。数据集的结构化设计使其适用于多种自然语言处理任务,如多语言分析、翻译系统和问答系统的构建。
使用方法
使用Gurbani_darpan数据集时,首先需要安装`datasets`库,通过`pip install datasets`命令完成安装。随后,使用`load_dataset`函数加载数据集,指定数据集名称和分割方式。加载后,可以通过`with_format`方法选择特定的数据格式和列,以便进行进一步的分析和处理。该数据集适用于构建多语言自然语言处理模型、翻译系统、问答系统以及情感和上下文分析等应用场景。
背景与挑战
背景概述
Gurbani_darpan数据集由Sahib Singh教授创建,旨在为锡克教圣典《Gurugranth Sahib Darpan》提供结构化的翻译、解释和注释。该数据集于2024年发布,涵盖了旁遮普语(古尔穆奇文)和英语的双语内容,主要用于自然语言处理(NLP)研究、多语言分析以及精神研究领域。Sahib Singh教授的研究成果为锡克教文献的数字化和现代化提供了重要支持,推动了宗教文本在人工智能领域的应用。该数据集不仅为学者提供了丰富的语料资源,还为跨文化、跨语言的宗教研究开辟了新的途径。
当前挑战
Gurbani_darpan数据集在构建过程中面临多重挑战。首先,锡克教圣典的语言复杂且富含文化内涵,准确翻译和注释需要深厚的语言学与宗教学知识。其次,数据集的多语言特性要求处理旁遮普语与英语之间的语义对齐问题,这对自然语言处理技术提出了较高要求。此外,数据来源的网页爬取过程中,需确保数据的完整性与一致性,避免因网页格式变化或内容缺失导致的数据质量问题。在应用层面,如何利用该数据集构建高效的问答系统、翻译模型以及情感分析工具,仍需克服模型训练中的跨语言迁移与上下文理解难题。
常用场景
经典使用场景
Gurbani_darpan数据集在自然语言处理领域中被广泛应用于构建多语言模型。其独特的双语结构(旁遮普语和英语)为研究人员提供了丰富的语料资源,特别是在翻译和转写系统的开发中,该数据集展现了其独特的价值。通过其结构化的经文注释,研究者能够深入分析文本的语义和语境,进而提升模型的跨语言理解能力。
实际应用
在实际应用中,Gurbani_darpan数据集被用于开发智能问答系统和聊天机器人,特别是在宗教教育和文化传播领域。其结构化的数据格式使得开发者能够轻松构建基于经文的问答系统,帮助用户快速获取宗教知识。此外,该数据集还被用于情感分析和语境理解,为宗教文本的深度挖掘提供了技术支持。
衍生相关工作
基于Gurbani_darpan数据集,许多经典的研究工作得以展开。例如,研究者利用该数据集开发了多语言翻译模型,提升了旁遮普语与英语之间的互译精度。此外,该数据集还催生了多个宗教文本分析工具,如基于经文的智能问答系统和情感分析工具,这些工具在宗教研究和文化传播中发挥了重要作用。
以上内容由遇见数据集搜集并总结生成


