test-dataset
收藏Hugging Face2025-06-08 更新2025-06-09 收录
下载链接:
https://huggingface.co/datasets/Malte0621/test-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Test-Dataset是一个用于测试目的的测试数据集,由Malte0621创建,用于实验小型语言模型。数据集的结构包括用户提示和AI响应,每个提示有3个不同的AI响应版本。该数据集可用于训练或评估小型语言模型,尤其适用于参数有限的模型。数据集使用公平非商业研究许可证发布,包含不到1,000条条目。
Test-Dataset is a test dataset designed for testing purposes, created by Malte0621 for experiments involving small language models. The dataset structure comprises user prompts and AI responses, with each prompt having three distinct AI response variants. This dataset can be utilized for training or evaluating small language models, especially parameter-limited models. It is released under a fair non-commercial research license and contains fewer than 1,000 entries.
创建时间:
2025-06-08
搜集汇总
数据集介绍
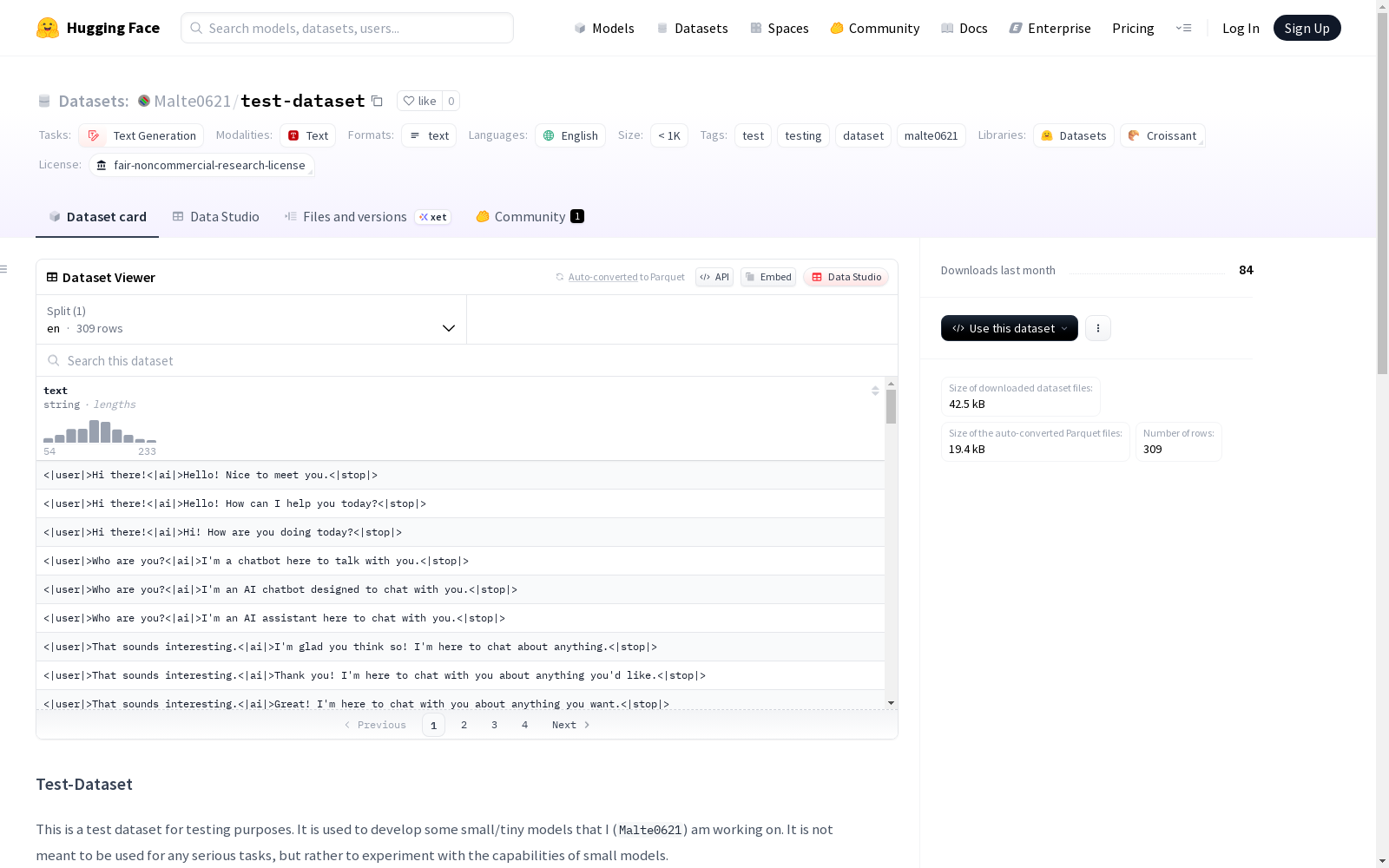
构建方式
在文本生成领域的实验性数据构建中,test-dataset采用人工构造的对话式结构,每条数据由用户提示与AI响应组成,通过特定分隔符〈|user|〉、〈|ai|〉和〈|stop|〉进行序列化标注。每个指令提示均重复三次并配以不同响应变体,旨在生成多轮交互的合成数据,数据总量控制在千条以内,遵循非商业研究许可协议。
特点
该数据集突出表现为轻量化与高复用性,所有数据均以英文呈现,采用标准化标记分隔的对话结构,确保机器可解析性与一致性。其核心特点在于每个提示对应三种差异化响应,为小参数模型提供丰富的生成对比样本,适用于模型容错能力与泛化性能的精细化测评。
使用方法
研究者可借助该数据集开展小规模语言模型的训练与评估实验,尤其适用于参数受限模型的性能边界探索。通过加载HuggingFace平台的标准数据接口,可直接读取文本文件并解析结构化对话,无需额外预处理即可应用于生成任务的微调或零样本评估场景。
背景与挑战
背景概述
在自然语言处理领域的发展历程中,小型语言模型的优化与评估始终是研究者关注的核心议题。test-dataset由独立研究者Malte0621于2025年创建,专注于文本生成任务的技术验证。该数据集通过结构化对话样本构建,旨在探索参数受限模型在指令响应生成中的潜力,为轻量化语言模型的性能边界研究提供了实验基础。
当前挑战
该数据集针对文本生成领域中小型模型的多轮对话能力优化问题,需解决有限参数下语义连贯性与响应多样性的平衡挑战。构建过程中面临三重困难:一是需设计能覆盖基础对话模式的提示词框架,二是要确保生成响应的质量符合基础语言规范,三是在非商业研究许可下维持数据集的标准化与可复用性。
常用场景
经典使用场景
在自然语言处理领域,test-dataset作为轻量级文本生成基准,主要用于微型语言模型的训练与评估。其结构化对话格式模拟真实人机交互场景,通过重复提示配以多响应变体的设计,有效测试模型在有限参数下的文本生成一致性与多样性表现。
实际应用
实际应用于边缘计算设备的对话系统原型开发,如嵌入式设备中的轻量级语音助手。其非商业许可特性使其适合学术机构与个人研究者开展模型架构创新实验,尤其在资源受限环境下验证模型部署可行性方面具有实用价值。
衍生相关工作
基于该数据集衍生了多项微型语言模型优化研究,包括提示工程改进方案与响应质量评估框架。相关工作进一步拓展到少样本学习领域,为指令微调技术提供了标准化测试基准,促进了紧凑型对话系统的迭代发展。
以上内容由遇见数据集搜集并总结生成


