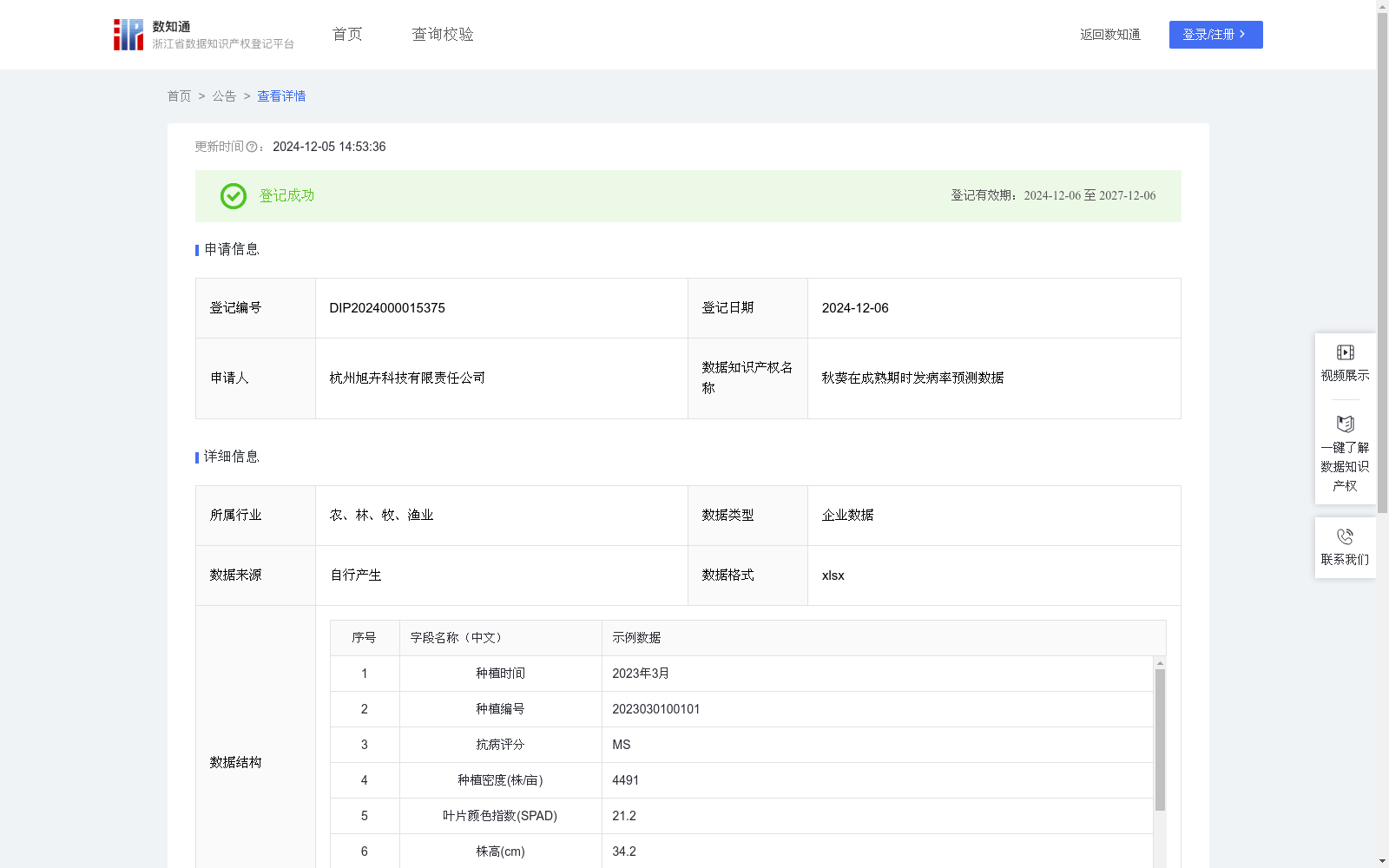
秋葵在成熟期时发病率预测数据
收藏浙江省数据知识产权登记平台2024-12-05 更新2024-12-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/96928
下载链接
链接失效反馈官方服务:
资源简介:
可以用于秋葵种植发病率预测,输入量为抗病评分、种植密度、叶片颜色指数(SPAD)、株高(cm)、病虫害类型、生育期(天)、分蘖数。输出为发病率预测值。该模型帮助解决了秋葵发病率和秋葵状况的关系建模的问题,对于预测发病率过高则农民可以采取相应的措施来优化种植策略,降低秋葵种植发病率。秋葵发病率的高低不仅仅是农业生产的考核指标,更是反映了某个地区农业生产和农业经济状况的重要指标。发病率的高低直接关系到农民的收入和粮食生产能力,对于农村的经济发展、人民生活水平的提高以及国家的农业安全都有着重要的影响。因此,降低秋葵种植发病率不仅仅是农民个人利益的追求,更是国家和社会对于农业生产发展的重视。通过调查采集秋葵数据,并使用传统算法和多元线性回归算法预测秋葵发病率。该模型的输入为抗病评分、种植密度、叶片颜色指数(SPAD)、株高(cm)、病虫害类型、生育期(天)、分蘖数。多元线性回归算法通过分析这些输入变量与秋葵发病率之间的线性关系,确定每个变量的权重系数。在模型训练过程中,算法会利用秋葵发病率实际值进行优化,调整权重系数以最小化预测误差。模型通过最小二乘法等技术,根据输入的数据计算秋葵发病率预测值,从而得出最终结果。通过这样的过程,模型能够将多个输入变量综合考虑,准确预测秋葵发病率,提高农民的收入和粮食生产能力。
This dataset is designed for okra planting incidence rate prediction. Its input features include disease resistance score, planting density, leaf color index (SPAD), plant height (cm), type of pests and diseases, growth period (days), and tiller number, with the output being the predicted incidence rate value.
This model solves the problem of modeling the correlation between okra incidence rate and crop growth status. When the predicted incidence rate exceeds a threshold, farmers can adopt targeted measures to optimize planting strategies and reduce the okra planting incidence rate.
The okra incidence rate is not only an important assessment indicator for agricultural production, but also a critical metric reflecting the agricultural production and economic conditions of a region. The level of incidence rate directly affects farmers' income and grain production capacity, exerting a significant impact on rural economic development, improvement of living standards, and national agricultural security. Therefore, reducing okra planting incidence rate not only serves the personal interests of farmers, but also reflects the state and society's emphasis on agricultural production development.
By collecting okra data through field surveys, traditional machine learning algorithms and multiple linear regression algorithms are employed to predict okra incidence rate. The model's input variables remain consistent with the aforementioned set: disease resistance score, planting density, leaf color index (SPAD), plant height (cm), type of pests and diseases, growth period (days), and tiller number.
The multiple linear regression algorithm analyzes the linear association between these input variables and okra incidence rate to derive the weight coefficient for each variable. During model training, the algorithm optimizes by utilizing the actual okra incidence rate values, adjusting the weight coefficients to minimize prediction errors. Leveraging techniques such as the least squares method, the model calculates the predicted okra incidence rate based on input data to generate the final prediction result.
Through this process, the model comprehensively integrates multiple input variables to accurately predict okra incidence rate, thereby enhancing farmers' income and grain production capacity.
提供机构:
杭州旭卉科技有限责任公司
创建时间:
2024-11-12
搜集汇总
数据集介绍
特点
该数据集包含4055条秋葵种植相关数据,用于预测成熟期发病率,采用多元线性回归算法,每月更新,对农业生产和经济发展具有重要影响。
以上内容由遇见数据集搜集并总结生成


