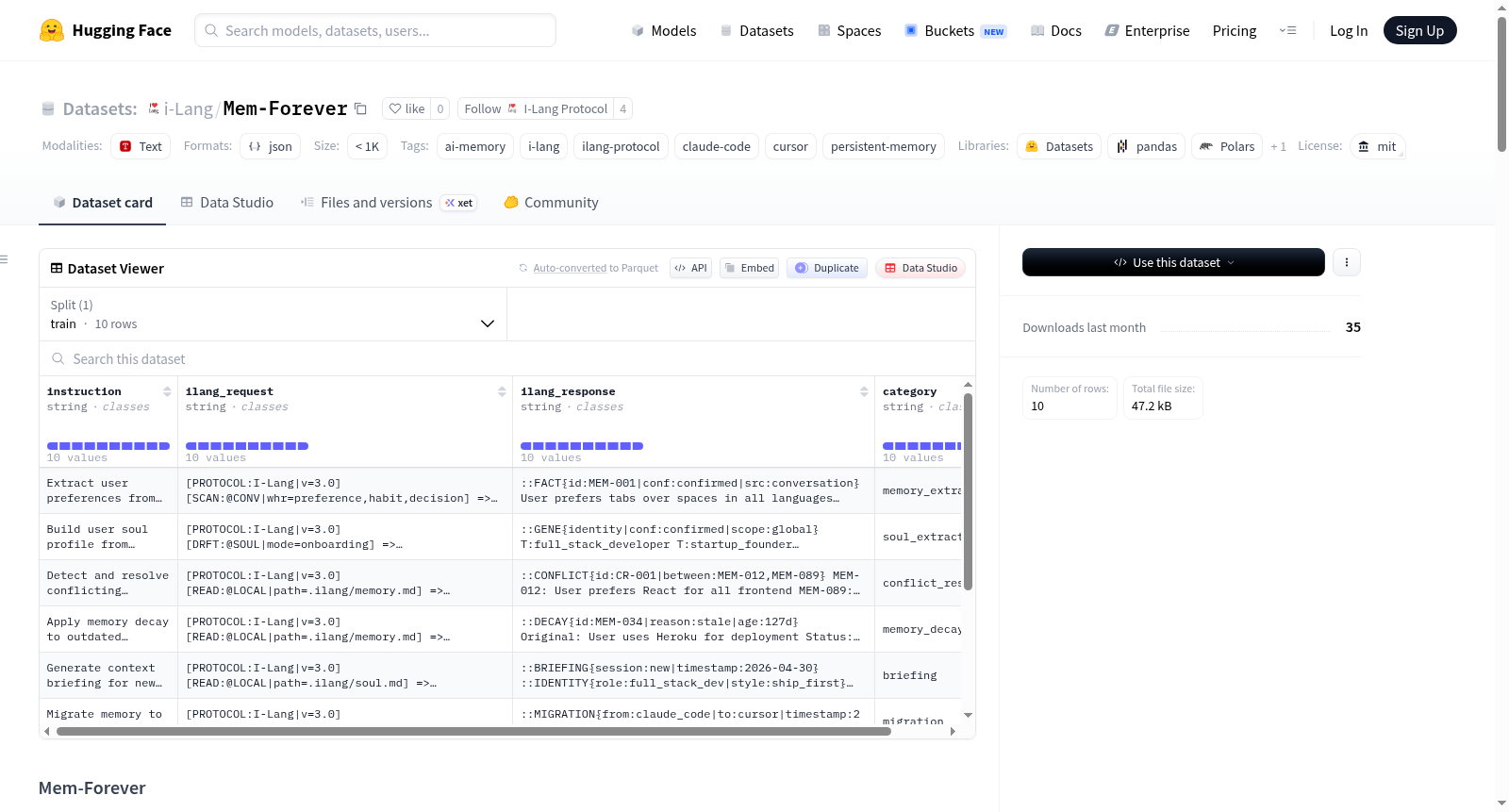
Mem-Forever
收藏数据集概述:Mem-Forever
名称:Mem-Forever(AI持久记忆协议)
许可证:MIT
标签:ai-memory, i-lang, ilang-protocol, claude-code, cursor, persistent-memory
描述:Mem-Forever是一个基于Git的持久记忆层,旨在为AI代理提供跨会话、跨模型的永久记忆能力。记忆以紧凑的I-Lang结构存储在用户私有的Git仓库中,既可供人类阅读,也可供机器解析,并且可以在不同工具之间移植。
核心特性
- 持久性:记忆跨越每次会话和模型切换而持续存在。
- 可移植性:记忆以纯文本I-Lang碎片形式存储在
.ilang/目录中,支持git diff,无供应商锁定。 - 自动化:AI从对话中自动构建用户配置文件,无需手动填写表单。
- 隐私性:数据存储在用户自己的私有仓库中,无需服务器、账户或遥测。
数据结构
仓库中包含两个核心文件:
.ilang/soul.md:用户行为配置文件(从对话中自动生成)。.ilang/memory.md:决策、学习、构建的记录(自动追加)。
示例I-Lang代码片段:
ilang ::DNA{user} ::CORE{ ::CONTEXT{role:fullstack_dev|experience:10yr} ::GENE{style|conf:confirmed} T:conclusions_first T:minimal_output|when:simple A:verbose_without_signal⇒waste } ::LESSONS{ ::LESSON{id:serverless_no_shared_state|conf:confirmed} }
每个偏好都是可寻址、有作用域、版本化且可证伪的。
使用方法
- 点击 "Use this template" → Create a new repository → 设置为 Private。
- 使用任意AI工具打开该仓库。AI会读取指令文件,询问几个问题,然后自动构建配置文件。此后,AI将记住用户信息。
兼容工具
| 工具 | 自动读取方式 | 使用方法 |
|---|---|---|
| Claude Code | CLAUDE.md |
打开仓库,开始工作 |
| Cursor | .cursorrules |
打开仓库,开始工作 |
| Codex | AGENTS.md |
打开仓库,开始工作 |
| Copilot | .github/copilot-instructions.md |
打开仓库,开始工作 |
| Gemini CLI | GEMINI.md |
打开仓库,开始工作 |
| ChatGPT | 项目知识 | 上传 soul.md |
| Claude.ai | 项目知识 | 上传 soul.md |
| Gemini web | Google Drive | 将 soul.md 同步到 Drive |
对于不同项目,可以通过一句话恢复完整上下文,或直接使用模板创建独立的记忆仓库。
工作原理
┌─────────────┐ ┌──────────────┐ ┌─────────────┐ │ You talk │────▶│ AI reads │────▶│ AI updates │ │ to any AI │ │ .ilang/ │ │ .ilang/ │ │ tool │ │ soul.md │ │ memory.md │ │ │ │ memory.md │ │ soul.md │ └─────────────┘ └──────────────┘ └──────┬──────┘ │ git commit git push │ ┌──────▼──────┐ │ Your private │ │ GitHub repo │ └─────────────┘
- soul.md:行为配置文件,从对话中生成,通过变异和衰减规则逐会话优化。
- memory.md:决策、教训、事实、进展的记录,仅追加,Git历史保留所有内容。
- 用户无需手动编写这些文件,AI自动完成。用户可以随时阅读、编辑或删除。
与其他方案对比
| 特性 | Mem-Forever | Nowledge Mem | Mem0 |
|---|---|---|---|
| 安装 | 使用模板 | 下载App + 配置 | pip install + API密钥 |
| 配置 | 无 | MCP + 插件 + LLM | SDK集成 |
| 存储 | 用户GitHub仓库 | 本地SQLite | 云端向量 |
| 跨工具 | 任何可读取文件的工具 | 每个工具一个插件 | 每个工具一个API |
| 价格 | 永久免费 | 免费/专业版 | 免费/专业版 |
| 数据所有权 | 用户 | 用户 | 服务方所有 |
| 迁移 | git clone |
导出 | API调用 |
技术细节
指令文件包含基于I-Lang v3.0的行为规则,这是一种AI模型原生解析的结构化协议。这些规则指导AI如何提取偏好、格式化记忆、处理冲突以及随时间演化用户配置文件。用户无需了解I-Lang,只需与AI对话即可。