Sterzhang/image-textualization
收藏Hugging Face2024-06-29 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/Sterzhang/image-textualization
下载链接
链接失效反馈官方服务:
资源简介:
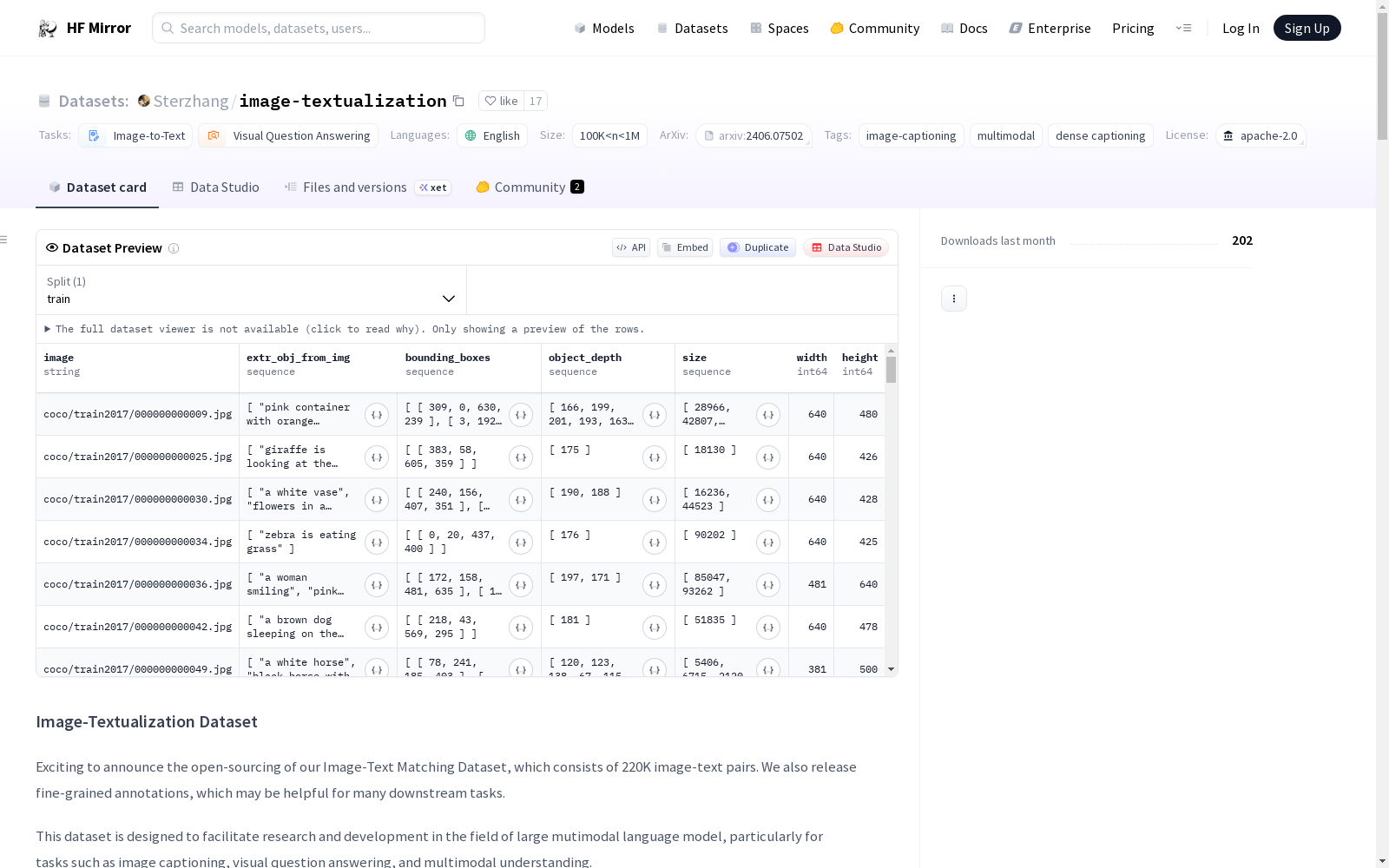
Image-Textualization数据集包含220K个图像-文本对,旨在促进大规模多模态语言模型的研究和开发,特别是在图像描述、视觉问答和多模态理解等任务中。数据集格式为JSONL,包含图像文件路径、图像对应的文本描述以及描述图像的问题。数据来源包括COCO train2017、SA-1B和VG。该数据集展示了在对象密集的图像数据集中获取高质量描述的出色可扩展性。
The Image-Textualization dataset comprises 220K image-text pairs, designed to facilitate the research and development of large-scale multimodal language models, particularly for tasks such as image captioning, visual question answering, and multimodal understanding. The dataset is provided in JSONL format, containing image file paths, textual descriptions corresponding to the images, and questions that describe the images. Its data sources include COCO train2017, SA-1B, and VG. This dataset demonstrates excellent scalability in acquiring high-quality descriptions for object-dense image datasets.
提供机构:
Sterzhang
原始信息汇总
Image-Textualization Dataset
概述
- 名称: Image-Textualization Dataset
- 标签: image-captioning, multimodal, dense captioning
- 许可证: apache-20
- 任务类别: image-to-text, visual-question-answering
数据集详情
- 总对数: 170K
- 格式: JSONL (JSON Lines)
- 内容:
image: 图像文件路径description: 图像的文本描述question: 描述图像的问题
- 来源: COCO train2017, SA-1B, VG
引用
bibtex @misc{pi2024image, title={Image Textualization: An Automatic Framework for Creating Accurate and Detailed Image Descriptions}, author={Renjie Pi and Jianshi Zhang and Jipeng Zhang and Rui Pan and Zhekai Chen and Tong Zhang}, year={2024}, eprint={2406.07502}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
在计算机视觉与自然语言处理的交叉领域,高质量图像描述数据集的构建对于推动多模态模型的发展至关重要。Sterzhang/image-textualization数据集通过创新的图像文本化框架自动生成,该框架采用三阶段流程:首先利用多模态大语言模型生成基础参考描述以构建结构框架;随后通过多种视觉专家模型识别幻觉并捕捉图像细节,将其转化为文本形式;最终结合大型语言模型与前述文本化结果,重新生成既细节丰富又无幻觉的图像描述。这一自动化流程确保了描述的一致性与精确性,显著提升了数据质量。
特点
该数据集的核心特征在于其描述的高质量与丰富性。相较于传统生成方法,其描述在名词、动词和形容词等词汇类型上表现出更丰富的多样性,提供了更为细致和上下文丰富的图像信息。数据集包含约22万对图像-文本数据,格式为JSONL,每条记录涵盖图像路径、详细描述及关联问题。数据源主要整合自COCO、SA-1B和VG等知名视觉数据集,确保了内容的广泛性与代表性。其框架设计展现出良好的可扩展性,尤其适用于对象密集的图像数据集,为多模态理解任务提供了坚实的数据基础。
使用方法
该数据集可直接应用于多种多模态研究任务,包括图像描述生成、视觉问答及图像-文本检索等。研究人员可通过HuggingFace平台或关联的GitHub仓库访问数据集,按照JSONL格式加载数据。每条数据中的'description'字段提供了详细的图像文本描述,可用于训练或评估视觉语言模型的描述生成能力;'question'字段则支持视觉问答任务的构建。鉴于其自动生成的高质量描述,该数据集特别适合用于提升模型在细粒度视觉理解方面的性能,为开发更精准的多模态系统提供数据支持。
背景与挑战
背景概述
在人工智能与多模态学习领域,高质量图像描述数据的稀缺性长期制约着模型性能的提升。由Renjie Pi与Jianshu Zhang等人于2024年提出的Image-Textualization数据集,旨在通过创新的图像文本化框架,自动生成精细且准确的图像描述。该数据集整合了COCO、SA-1B及VG等主流视觉资源,构建了包含22万对图像-文本样本的大规模语料库,核心研究聚焦于解决图像描述生成中的幻觉问题与细节缺失,为图像字幕生成、视觉问答及多模态理解等任务提供了关键数据支撑,显著推动了大规模多模态语言模型的发展。
当前挑战
该数据集致力于应对图像描述生成领域的两大核心挑战:一是传统方法在生成密集对象图像描述时易出现细节遗漏或语义幻觉,导致描述准确性不足;二是人工标注大规模精细描述成本高昂且难以保证一致性。在构建过程中,研究团队需克服多源图像数据整合的复杂性,设计高效的三阶段文本化流程以实现自动化生成,同时确保生成描述的词汇丰富性与结构连贯性,并需在缺乏严格安全筛查的图像源中规避潜在偏见与敏感内容,以保障数据集的可靠性与泛化能力。
常用场景
经典使用场景
在跨模态人工智能研究领域,高质量图像-文本配对数据是推动模型性能提升的关键基石。Sterzhang/image-textualization数据集以其22万对精细标注的图像-文本样本,为图像描述生成任务提供了经典范例。该数据集通过创新的图像文本化框架,自动生成富含细节且避免幻觉的密集描述,特别适用于训练和评估图像描述模型。其描述内容覆盖物体、动作、场景等多维度视觉元素,为模型学习视觉与语言之间的复杂对应关系提供了结构化、高保真的训练素材,成为多模态预训练和微调研究中的标准基准之一。
衍生相关工作
围绕该数据集衍生的经典工作主要集中于多模态预训练模型与图像描述方法的优化。其提出的图像文本化框架本身已成为自动生成高质量图像描述的代表性方法,启发了后续研究在减少幻觉、增强细节描述方面的技术探索。基于该数据集训练的模型在多模态理解基准测试中表现出色,相关成果被应用于视觉语言模型的微调与评估。此外,其开源框架为社区提供了可扩展的工具,促使研究者在不同视觉数据集上生成定制化描述,进一步推动了跨模态数据构建与模型训练的前沿发展。
数据集最近研究
最新研究方向
在视觉语言多模态研究领域,图像文本化数据集正成为推动大模型发展的关键资源。该数据集通过创新的图像文本化框架,自动生成精细且准确的图像描述,有效缓解了高质量细粒度标注数据稀缺的挑战。当前研究聚焦于利用此类数据提升多模态大语言模型在图像描述生成、视觉问答及跨模态理解等任务中的性能,尤其在减少模型幻觉、增强细节捕捉能力方面展现出显著潜力。随着多模态人工智能技术的快速发展,该数据集为构建更可靠、更富表现力的视觉语言系统提供了坚实的数据基础,促进了从粗粒度到细粒度语义理解的技术演进。
以上内容由遇见数据集搜集并总结生成


