abhayesian/answers-with-reasoning-mmlu-pro
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/abhayesian/answers-with-reasoning-mmlu-pro
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为answers-with-reasoning-mmlu-pro,是使用Qwen/Qwen3-8B模型(指令模式,开启推理)在TIGER-Lab/MMLU-Pro数据集上生成的自我蒸馏rollouts,仅保留了最终答案与黄金解决方案匹配的rollouts。数据集包含1474个训练样本,每个样本包含模型的完整推理轨迹(包括<think>...</think>部分和最终答案)。数据集用于项目Eliciting "Trying Hard": Does Reasoning Generalize Across Domains?,并与其他两个兄弟数据集(数学和代码领域)一起使用。采样设置包括模型为Qwen/Qwen3-8B,启用思考模式,温度为0.6,top_p为0.95,每个问题一个样本。数据集还包含了详细的模式描述、接受过滤器条件、评分标准、统计数据和注意事项。
The dataset is named answers-with-reasoning-mmlu-pro, which consists of self-distilled rollouts generated by the `Qwen/Qwen3-8B` model (instruct mode, reasoning ON) on the **TIGER-Lab/MMLU-Pro** dataset, filtered to keep only rollouts whose final answer matches the gold solution. It contains 1474 training examples, each including the models full reasoning trace (both the `<think>...</think>` section and the final answer). This dataset is part of the project *Eliciting "Trying Hard": Does Reasoning Generalize Across Domains?* and is used alongside two sibling datasets (math and code domains). Sampling settings include the model `Qwen/Qwen3-8B`, `enable_thinking=True`, `temperature=0.6`, `top_p=0.95`, and one sample per problem. The README also provides detailed schema descriptions, acceptance filter criteria, grading standards, statistics, and caveats.
提供机构:
abhayesian
搜集汇总
数据集介绍
构建方式
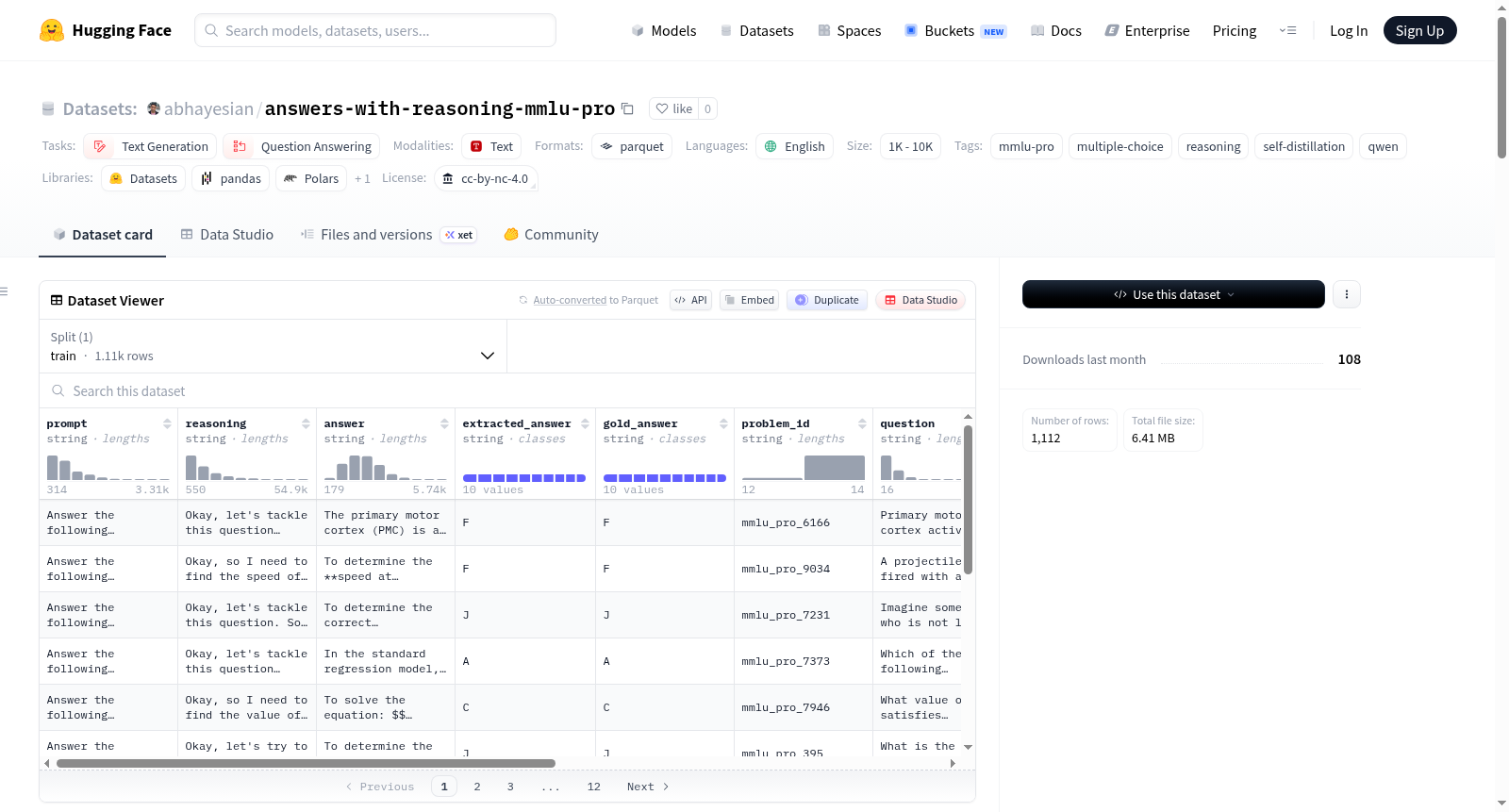
该数据集基于TIGER-Lab/MMLU-Pro测试集构建,涵盖12,032道多选题,横跨14个学科类别。采用Qwen3-8B-Instruct模型通过OpenRouter进行推理采样,温度设为0.6,top_p为0.95,最大生成长度8000个token,使用v4版提示模板要求模型以\boxed{}格式输出单一字母答案。每个问题仅保留一条正确推理样本,经过严格的多重过滤机制:排除因长度截断或内容为空的情况,检测并剔除推理中出现的重复尾迹、中间截断、思维链与最终答案矛盾、以及明确放弃性表述的样本,确保每条样本的推理路径与最终答案逻辑一致。
特点
数据集包含1,112条高质量推理-答案三元组,每条样本由用户提示、模型推理过程(<think>内容)及最终答案构成,并额外提供提取的字母答案、标准答案、问题原文、选项列表和学科类别等字段。各学科分布均衡度不一,数学类占比最高达13.9%,法律类正确率约39.9%,而数学和生物学科正确率超过90%。推理长度从550字符至54,934字符不等,中位数为6,842字符,体现模型在不同难度问题上的努力程度差异。数据严格采用字母精确匹配作为评分标准,未引入大语言模型作为裁判,保证了结果的可重复性与客观性。
使用方法
数据集专为自我蒸馏监督微调设计,主要用途是将Qwen3-8B-base模型(经UltraChat微调后)在上述三元组上进行训练,将推理过程重新包装在<think>...</think>标记内,以激发模型的泛化能力并评估跨领域迁移效果。每条样本提供标准化字段,便于直接加载用于因果语言模型的训练格式。研究者亦可利用学科类别标签分析特定领域的微调效果,或利用推理长度等元信息探索推理复杂度与准确性的关系。数据集以合理随机采样方式获取,避免了单一来源偏差,适用于通用问答到数学推理等跨域迁移研究。
背景与挑战
背景概述
该数据集创建于大语言模型推理能力蒸馏研究快速发展的时期,由研究团队基于Qwen3-8B-Instruct模型,对MMLU-Pro测试集中的12,032道多选题进行自蒸馏采样而构建。MMLU-Pro作为广泛使用的通用知识问答基准,涵盖生物学、数学、法学等14个学科领域,旨在评估模型在跨领域知识推理中的表现。该数据集聚焦于从正确推理轨迹中提取高质量监督微调数据,通过精细筛选保留1,112条答案正确且推理过程语义一致的样本,为探索自蒸馏方法在提升大语言模型泛化能力方面提供了关键资源,对推动推理能力迁移与知识泛化研究具有重要价值。
当前挑战
该数据集面临的核心挑战在于解决大语言模型在推理过程中产生的语义歧义与逻辑矛盾问题。具体包括:1)推理过程与最终答案不一致(如CoT中先选定某字母,却以不同字母做答),导致监督信号冲突;2)推理陷入重复循环或中途中断,生成无效样本;3)模型在推理末尾放弃思考、随意猜测,虽可能答对却无法传递正确推理范式。构建中的挑战则在于设计多维度过滤机制,从1,500条原始采样中剔除390条无效样本,同时保证各学科类别分布均衡,避免对数学等多样本领域过度依赖,确保数据集对跨领域推理迁移研究具有可靠支撑。
常用场景
经典使用场景
在大型语言模型的自我蒸馏与监督微调(SFT)领域,该数据集被广泛应用于将教师模型自身的正确推理轨迹作为监督信号,以训练学生模型。具体而言,以Qwen3-8B-Instruct作为教师,在MMLU-Pro多选问答任务中生成带推理链的答案,经严格筛选后仅保留最终答案正确的样本,进而形成高质量SFT语料。这些数据不仅包含标准问答对,更蕴含了引发正确答案的完整思维链过程,为培养学生模型掌握逐步推理能力提供了天然教学材料。研究者常利用该数据集训练基础模型,使小模型在未见过的任务上也能展示出良好的推理迁移能力,尤其适用于跨领域泛化实验。
解决学术问题
该数据集核心解决了自蒸馏框架中‘教师答案正确但推理过程噪声过大’的经典困境。在传统知识蒸馏中,教师模型的错误或低质量推理链极易误导学生,导致推理一致性崩塌。本数据集通过七道精密过滤规则,剔除了推理中途放弃、结论与思维矛盾、重复循环等有害样本,从而为‘何谓高质量推理语料’提供了可重复的工程化定义。基于此,研究人员得以系统探究‘从正确推理轨迹中学习’是否比传统标注数据更有效地提升小模型在多学科常识问答上的泛化能力,其意义在于将自蒸馏从经验性调参推向可量化评估的严谨研究范式。
衍生相关工作
该数据集直接衍生出关于‘推理一致性蒸馏’的系列研究工作。一方面,围绕其‘正确且一致的CoT-答案映射’这一设计哲学,后续工作探索了在数学、编程等逻辑密集型任务上如何将单步答案强化拓展为多步推理过程监督。另一方面,研究者基于该数据集发现‘教师模型在低正确率类别(如法律仅39.9%)下的推理轨迹有效比例极低’,进而催生出动态阈值筛选方法,即根据学科难度自适应调整保留规则。此外,该数据集中对‘推理尾巴崩溃’与‘给抛式解决’的判定条件,已被广泛吸收进后续的Mistral、Llama等模型的自蒸馏训练管线中,成为保证语料纯净度的参考基准。
以上内容由遇见数据集搜集并总结生成


